

| 情報学部 | 菅沼ホーム | 全体目次 | 演習解答例 | 付録 | 索引 |
y = sqrt(x);
#include <math.h> double sqrt(double x) x : 倍精度浮動小数点数
double x = 3.14; double y = sqrt(x); // double y = sqrt(3.14) としても良い
double d_data;
int i_data;
char c_data[10];
scanf("%lf %d %s", &d_data, &i_data, c_data); 3.141592654 123 abc
3.141592654 123 abc
double d_data;
int i_data;
char c_data[10];
・・・・・
printf("結果は %f %10.3f %d %5d %s %c\n", d_data, d_data, i_data, i_data, c_data, c_data[1]);
結果は 3.141593 3.142 123 123 abc b
#include <stdio.h>
int main()
{
double x[2];
int y;
char str[10];
scanf("%lf %lf %d %s", &x[0], &x[1], &y, str);
printf("result %s %.4f %c %f%6d\n", str, x[0], str[2], x[1], y);
return 0;
}
result printf 3.1416 i 2.500000 123
/****************************/
/* 文字列操作の例 */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
#include <string.h>
int main()
{
// 現在の文字列の内容を出力
char abc[] = "abc";
printf("-abc- %s\n", abc); // 文字列として出力
printf("-abc- "); // 1文字ずつ出力
int i1;
for (i1 = 0; i1 < 3; i1++)
printf("%c", abc[i1]);
printf("\n");
// 文字列の長さ
int len1, len2, len3;
char *defgh = "defgh"; // 警告メッセージ(この表現は,避けた方が良い)
char emp[20] = "";
len1 = strlen(abc);
len2 = strlen(defgh);
len3 = strlen(emp);
printf("各文字列の長さ %d %d %d\n", len1, len2, len3);
// 文字列のコピー
char *str = strcpy(emp, abc);
len1 = strlen(emp);
printf("-str- %s -emp- %s 長さ %d\n", str, emp, len1);
// 文字列の比較
int c1 = strcmp(emp, abc);
int c2 = strcmp(emp, defgh);
printf("-empとabc- %d -empとdefgh- %d\n", c1, c2);
// 文字列の結合
str = strcat(emp, " ");
str = strcat(emp, defgh);
len1 = strlen(emp);
printf("-str- %s -emp- %s 長さ %d\n", str, emp, len1);
// 文字列の検索
str = strstr(emp, "ef");
len1 = strlen(str);
printf("-str- %s 長さ %d -emp- %s\n", str, len1, emp);
return 0;
}
-abc- abc -abc- abc 各文字列の長さ 3 5 0 -str- abc -emp- abc 長さ 3 -empとabc- 0 -empとdefgh- -1 -str- abc defgh -emp- abc defgh 長さ 9 -str- efgh 長さ 4 -emp- abc defgh
---------------------(C++)string クラス-------------------------
/****************************/
/* 文字列操作の例(C++) */
/* coded by Y.Suganuma */
/****************************/
#include <iostream>
#include <string>
using namespace std;
int main()
{
// 現在の文字列の内容を出力
string abc = "abc";
cout << "-abc- " << abc << endl; // 文字列として出力
cout << "-abc- "; // 1文字ずつ出力
for (int i1 = 0; i1 < 3; i1++)
cout << abc[i1];
cout << endl;
// 文字列の長さ
string defgh = "defgh";
string emp = "";
int len1 = abc.size();
int len2 = defgh.size();
int len3 = emp.size();
cout << "各文字列の長さ " << len1 << " " << len2 << " " << len3 << endl;
// 文字列のコピー
emp = abc.assign(abc);
len1 = emp.size();
cout << "-emp- " << emp << " 長さ " << len1 << endl;
// 文字列の比較
cout << boolalpha << "emp == abc ? " << (emp == abc) << endl;
cout << "emp >= defgh ? " << (emp >= defgh) << endl;
// 文字列の結合
string str = emp + " " + defgh;
len1 = str.size();
cout << "-str- " << str << " 長さ " << len1 << endl;
// 文字列の検索
int n = str.find("ef");
cout << (n+1) << " 番目以降の文字列 " << str.substr(5) << endl;
return 0;
}
-abc- abc -abc- abc 各文字列の長さ 3 5 0 -emp- abc 長さ 3 emp == abc ? true emp >= defgh ? false -str- abc defgh 長さ 9 6 番目以降の文字列 efgh
----------------------(C++)string クラス終わり--------------------
関数の型 関数名 ( 引数リスト )
例 : constexpr int func(・・・・・)
/****************************/
/* nの階乗の計算 */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int main()
{
/*
データの入力
*/
int n;
printf("nの値を入力して下さい ");
scanf("%d", &n);
/*
階乗の計算
*/
double kai = 1.0; /* 初期設定 */
int i1;
for (i1 = 1; i1 <= n; i1++)
kai *= (double)i1;
/*
結果の出力
*/
printf(" %dの階乗は=%f\n", n, kai);
return 0;
}
/****************************/
/* nの階乗の計算 */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
double kaijo(int);
int main()
{
/*
データの入力
*/
int n;
printf("nの値を入力して下さい ");
scanf("%d", &n);
/*
階乗の計算
*/
double kai = kaijo(n);
/*
結果の出力
*/
printf(" %dの階乗は=%f\n",n,kai);
return 0;
}
/**************************/
/* mの階乗 */
/* m : データ */
/* return : mの階乗 */
/**************************/
double kaijo(int m)
{
double s = 1.0;
int i1;
for (i1 = 1; i1 <= m; i1++)
s *= (double)i1;
return s;
}
printf(" %dの階乗は=%f\n", n, kaijo(n));
/****************************/
/* nの階乗の計算 */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int kaijo(int);
int main()
{
/*
データの入力
*/
int n;
printf("nの値を入力して下さい ");
scanf("%d", &n);
/*
階乗の計算
*/
int kai = kaijo(n);
/*
結果の出力
*/
printf(" %dの階乗は=%d\n", n, kai);
return 0;
}
/**************************/
/* mの階乗 */
/* m : データ */
/* return : nの階乗 */
/**************************/
int kaijo(int m)
{
int s;
if (m > 1)
s = m * kaijo(m-1); /* 自分自身を呼んでいる */
else
s = 1;
return s;
}
/****************************/
/* nCrの計算 */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
double kaijo(int);
int main()
{
/*
データの入力
*/
int n, r;
printf("nとrの値を入力して下さい ");
scanf("%d %d", &n, &r);
/*
nCrの計算と出力
*/
double sn = kaijo(n);
double sr = kaijo(r);
double snr = kaijo(n-r);
printf(" %dC%dは=%f\n", n, r, sn/(sr*snr));
return 0;
}
/**************************/
/* mの階乗 */
/* m : データ */
/* return : nの階乗 */
/**************************/
double kaijo(int m)
{
double s = 1.0;
int i1;
for (i1 = 1; i1 <= m; i1++)
s *= (double)i1;
return s;
}
[記憶クラス] [型修飾]データ型 変数名, 配列名, 関数名, ・・・
const int n = 10; double x[n];
y = ::x;
01 /**********************************/
02 /* 変数の有効範囲(同じファイル) */
03 /* coded by Y.Suganuma */
04 /**********************************/
05 #include <stdio.h>
06
07 void sub3(void);
08
09 extern int j; // 26 行目で宣言された j
10
11 void sub1(void)
12 {
13 extern int i; // 25 行目で宣言された i
14 int k = 3;
15 printf("%d %d %d\n", i, j, k);
16 }
17
18 void sub2(void)
19 {
20 int i = 5;
21 int k = 6;
22 printf("%d %d %d\n", i, j, k);
23 }
24
25 int i = 1;
26 int j = 2;
27
28 int main()
29 {
30 sub2();
31 sub1();
32 sub3();
33
34 return 0;
35 }
36
37 void sub3(void)
38 {
39 int k = 7;
40 printf("%d %d %d\n", i, j, k);
41 }
5 2 6 1 2 3 1 2 7
------------------------file 1----------------------------
/************************************/
/* 変数の有効範囲(別々のファイル) */
/* coded by Y.Suganuma */
/************************************/
void sub1(void);
void sub2(void);
void sub3(void);
int i = 1;
int j = 2;
int main()
{
sub2();
sub1();
sub3();
return 0;
}
------------------------file 2----------------------------
#include <stdio.h>
void sub1(void)
{
extern int i; // file 1 で宣言された i
extern int j; // file 1 で宣言された j
int k = 3;
printf("%d %d %d\n", i, j, k);
}
------------------------file 3----------------------------
#include <stdio.h>
void sub2(void)
{
extern int j; // file 1 で宣言された j
int i = 5;
int k = 6;
printf("%d %d %d\n", i, j, k);
}
------------------------file 4----------------------------
#include <stdio.h>
void sub3(void)
{
extern int i; // file 1 で宣言された i
extern int j; // file 1 で宣言された j
int k = 7;
printf("%d %d %d\n", i, j, k);
}
01 /*******************************/
02 /* C/C++における変数の有効範囲 */
03 /* coded by Y.Suganuma */
04 /*******************************/
05 #include <stdio.h>
06
07 int x = 10; // 以下に記述されたすべての関数で有効
08
09 int main()
10 {
11 int x = 20; // main 関数内で有効
12 int y; // main 関数内で有効
13
14 y = ::x; // 7 行目の x を参照( C では許されない)
15 printf("x %d y %d\n", x, y);
16
17 if (x > 5) {
18 int y = 30; // 18,19 行目だけで有効
19 printf("x %d y %d\n", x, y);
20 }
21
22 printf("x %d y %d\n", x, y);
23
24 for (int x = 1; x <= 3; x++) { // x は 24 ~ 27 行目で有効
// この表現は,C では許されない
25 int y = x + 1; // 25,26 行目だけで有効
26 printf("x %d y %d\n", x, y);
27 }
28
29 printf("x %d y %d\n", x, y);
30
31 return 0;
32 }
x 20 y 10 x 20 y 30 x 20 y 10 x 1 y 2 x 2 y 3 x 3 y 4 x 20 y 10
namespace 名前空間名 { リスト };
namespace name1
{
int func1( ・・・ ) { ・・・ }
・・・・・
}; x = name1::func1( ・・・ );
#include <stdio.h>
namespace Test1 {
void print(int k1, int k2)
{
printf("%d %d\n", k1, k2);
}
}
namespace Test2 {
void print(int k1, int k2)
{
printf("%d / %d", k1, k2);
}
}
/****************/
/* main program */
/****************/
int main()
{
Test1::print(10, 20);
Test2::print(10, 20);
return 0;
}
10 20 10 / 20
/****************/
/* main program */
/****************/
using namespace Test1;
int main()
{
print(10, 20);
Test2::print(10, 20);
return 0;
}
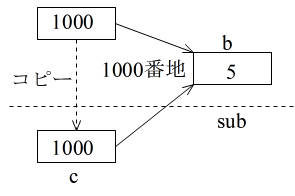
01 {
02 ・・・
03 int a = 1;
04 int b = 5;
05 int n = sub(a, &b);
06 ・・・
07 }
08 int sub(int a, int *c) // int* c でも可,c には b のアドレスのコピー
09 {
10 ・・・
11 *c = 10; // 4 行目の b の値を変更
12 ・・・
13 a = 100; // 3 行目の a の値は変化しない
14 ・・・
15 }
/****************************/
/* 複数結果の受け渡し */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int sub(int, int, int *); // int* でも可
int n; /* 以下の関数にすべて有効 */
int main()
{
/*
データの入力
*/
int a, b;
printf("a,b,及び,nの値を入力して下さい ");
scanf("%d %d %d", &a, &b, &n);
/*
関数の呼び出し
*/
int res;
int ind = sub(a, b, &res); /* 変数resはアドレス渡し */
/*
結果の出力
*/
if (ind == 0)
printf("n %d result %d\n", n, res);
else
printf("n = 0 (n %d)\n", n);
return 0;
}
/*****************************/
/* (a+b)/nの計算 */
/* a,b : データ */
/* res : 計算結果 */
/* return : =0 : normal */
/* =1 : n = 0 */
/*****************************/
int sub(int a, int b, int *res) // int* res でも可
{
extern int n;
int ind;
if (n == 0) {
ind = 1;
n = 100;
}
else {
ind = 0;
*res = (a + b) / n;
}
return ind;
}
n 3 result 2 n = 0 (n 100)
/****************************/
/* 複数結果の受け渡し */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
void sub(int, int, int *, int *);
int n; /* 以下の関数にすべて有効 */
int main()
{
/*
データの入力
*/
int a, b;
printf("a,b,及び,nの値を入力して下さい ");
scanf("%d %d %d", &a, &b, &n);
/*
関数の呼び出し
*/
int res, ind;
sub(a, b, &res, &ind);
/*
結果の出力
*/
if (ind == 0)
printf("n %d result %d", n, res);
else
printf("n = 0 (n %d)\n", n);
return 0;
}
/**************************/
/* (a+b)/nの計算 */
/* a,b : データ */
/* res : 計算結果 */
/* ind : =0 : normal */
/* =1 : n = 0 */
/**************************/
void sub(int a, int b, int *res, int *ind)
{
extern int n;
if (n == 0) {
*ind = 1;
n = 100;
}
else {
*ind = 0;
*res = (a + b) / n;
}
}
/****************************/
/* 複数結果の受け渡し */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int *sub(int, int);
int n; /* 以下の関数にすべて有効 */
int main()
{
/*
データの入力
*/
int a, b;
printf("a,b,及び,nの値を入力して下さい ");
scanf("%d %d %d", &a, &b, &n);
/*
関数の呼び出し
*/
int *res = sub(a, b); /* resに結果が入る */
/*
結果の出力
*/
if (res[0] == 0)
printf("n %d result %d", n, res[1]);
else
printf("n = 0 (n %d)\n", n);
delete [] res;
return 0;
}
/**************************************/
/* (a+b)/nの計算 */
/* a,b : データ */
/* return : res[0] : =0 : normal */
/* =1 : n = 0 */
/* res[1] : 計算結果 */
/**************************************/
int *sub(int a, int b)
{
extern int n;
int *res = new int [2];
if (n == 0) {
res[0] = 1;
n = 100;
}
else {
res[0] = 0;
res[1] = (a + b) / n;
}
return res;
}
/****************************/
/* 複数結果の受け渡し */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
void sub(int, int, int *);
int n; /* 以下の関数にすべて有効 */
int main()
{
/*
データの入力
*/
int a, b;
printf("a,b,及び,nの値を入力して下さい ");
scanf("%d %d %d", &a, &b, &n);
/*
関数の呼び出し
*/
int res[2];
sub(a, b, res);
/*
結果の出力
*/
if (res[0] == 0)
printf("n %d result %d", n, res[1]);
else
printf("n = 0 (n %d)\n", n);
return 0;
}
/***********************************/
/* (a+b)/nの計算 */
/* a,b : データ */
/* res : res[0] : =0 : normal */
/* =1 : n = 0 */
/* res[1] : 計算結果 */
/***********************************/
void sub(int a, int b, int *res) // void sub(int a, int b, int res[]) でも可
{
extern int n;
if (n == 0) {
res[0] = 1;
n = 100;
}
else {
res[0] = 0;
res[1] = (a + b) / n;
}
}
int func(int, int = 5, char * = "test");
func(x) func(x, 10);
func(x, 5, "test") func(x, 10, "test");
01 /****************************/
02 /* デフォルト引数 */
03 /* coded by Y.Suganuma */
04 /****************************/
05 #include <stdio.h>
06
07 void sub(int, int = 5, FILE * = stdout);
08
09 int main()
10 {
11 sub(10); // sub(10, 5, stdout)と解釈,標準出力
12 sub(10, 10); // sub(10, 10, stdout)と解釈,標準出力
13 sub(10, 20, stdout); // 標準出力
14 FILE *out = fopen("test.txt", "w");
15 sub(10, 30, out); // ファイル test.txt へ出力
16 fclose(out);
17 return 0;
18 }
19
20 /*********************************/
21 /* 整数の足し算 */
22 /* x,y : データ */
23 /* fp : 出力先 */
24 /*********************************/
25 void sub(int x, int y, FILE *fp)
26 //void sub(int x, int y = 5, FILE *fp = stdout)
27 {
28 fprintf(fp, "結果は=%d\n", x+y);
29 }
int sub(・・・, int c[], ・・・) // int sub(・・・, int *c, ・・・) でも可
{
・・・
}
int main {
int b[5];
・・・
n = sub(・・・, b, ・・・);
・・・
}
/****************************/
/* 1次元配列の受け渡し */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
void wa(int, int*, int*, int*);
int main()
{
int a[2][3] = {{1, 2, 3}, {4, 5, 6}}, b[3];
/*
関数の呼び出し
*/
wa(3, &(a[0][0]), &(a[1][0]), b); /* 1行目と2行目のベクトル和の計算 */
/*
結果の出力
*/
int i1;
for (i1 = 0; i1 < 3; i1++)
printf("%d ", b[i1]);
printf("\n");
return 0;
}
/***********************************/
/* n次元ベクトルの和 */
/* n : 次元数 */
/* a,b : 和を計算するベクトル */
/* c : 計算結果が入るベクトル */
/***********************************/
void wa(int n, int* a, int* b, int* c)
{
int i1;
for (i1 = 0; i1 < n; i1++)
c[i1] = a[i1] + b[i1];
}
5 7 9
---------------------(C++11)初期化子リストの受け渡し-------------------------
/****************************/
/* 初期化子リストの受け渡し */
/* coded by Y.Suganuma */
/****************************/
#include <iostream>
#include <vector>
using namespace std;
void wa(vector<pair<int, int>>, int *);
int main()
{
int res[2] = {0};
vector<pair<int, int>> v {{1, 2}, {3, 4}, {5, 6}};
cout << "v";
for (auto x : v)
cout << " (" << x.first << ", " << x.second << ")";
cout << endl;
wa(v, res);
// wa({{1, 2}, {3, 4}, {5, 6}}, res); // 初期化子リスト
cout << " result " << res[0] << " " << res[1] << endl;
return 0;
}
/*********************************************/
/* ペアの和 */
/* r[0] : vector の各要素の first の和 */
/* r[1] : vector の各要素の second の和 */
/*********************************************/
void wa(vector<pair<int, int>> v, int *r)
{
for (auto x : v) {
r[0] += x.first;
r[1] += x.second;
}
}
v (1, 2) (3, 4) (5, 6) result 9 12
----------------------(C++11)初期化子リストの受け渡し--------------------
int b[4][10];
int sub(・・・, int c[][10], ・・・)
int sub(・・・, int (*c)[10], ・・・)
C = AB, cij = Σkaikbkj k = 1, ・・・, m
/**********************************/
/* 2次元配列の受け渡し(方法1) */
/* coded by Y.Suganuma */
/**********************************/
#include <stdio.h>
void seki(int, int, int, double [][3], double [][2], double [][2]);
int main()
{
/*
関数の呼び出し
*/
double a[2][3] = {{1.0, 2.0, 3.0}, {4.0, 5.0, 6.0}};
double b[3][2] = {{1.0, 0.0}, {0.0, 1.0}, {0.0, 0.0}};
double c[2][2];
seki(2, 3, 2, a, b, c);
/*
結果の出力
*/
int i1;
for (i1 = 0; i1 < 2; i1++) {
int i2;
for (i2 = 0; i2 < 2; i2++)
printf("%f ", c[i1][i2]);
printf("\n");
}
return 0;
}
/**************************************/
/* 行列の積 */
/* n,m,l : 次元数 */
/* a : n x m */
/* b : m x l */
/* c : 計算結果が入る行列,n x l */
/**************************************/
void seki(int n, int m, int l, double a[][3], double b[][2], double c[][2])
{
int i1, i2, i3;
for (i1 = 0; i1 < n; i1++) {
for (i2 = 0; i2 < l; i2++) {
c[i1][i2] = 0;
for (i3 = 0; i3 < m; i3++)
c[i1][i2] += a[i1][i3] * b[i3][i2];
}
}
}
1 2 4 5
/**********************************/
/* 2次元配列の受け渡し(方法2) */
/* coded by Y.Suganuma */
/**********************************/
#include <stdio.h>
void seki(int, int, int, double**, double**, double**);
int main()
{
/*
領域の確保と値の設定
*/
double **a = new double* [2];
double **b = new double* [3];
double **c = new double* [2];
for (int i1 = 0; i1 < 2; i1++) {
c[i1] = new double [2];
if (i1 == 0)
a[i1] = new double [3] {1, 2, 3};
else
a[i1] = new double [3] {4, 5, 6};
}
for (int i1 = 0; i1 < 3; i1++) {
if (i1 == 0)
b[i1] = new double [2] {1, 0};
else if (i1 == 1)
b[i1] = new double [2] {0, 1};
else
b[i1] = new double [2] {0, 0};
}
/*
関数の呼び出し
*/
seki(2, 3, 2, a, b, c);
/*
結果の出力
*/
for (int i1 = 0; i1 < 2; i1++) {
for (int i2 = 0; i2 < 2; i2++)
printf("%f ", c[i1][i2]);
printf("\n");
}
return 0;
}
/**************************************/
/* 行列の積 */
/* n,m,l : 次元数 */
/* a : n x m */
/* b : m x l */
/* c : 計算結果が入る行列,n x l */
/**************************************/
void seki(int n, int m, int l, double **a, double **b, double **c)
{
for (int i1 = 0; i1 < n; i1++) {
for (int i2 = 0; i2 < l; i2++) {
c[i1][i2] = 0;
for (int i3 = 0; i3 < m; i3++)
c[i1][i2] += a[i1][i3] * b[i3][i2];
}
}
}
/**********************************/
/* 2次元配列の受け渡し(方法3) */
/* coded by Y.Suganuma */
/**********************************/
#include <stdio.h>
void seki(int, int, int, double *, double *, double *);
int main()
{
/*
関数の呼び出し
*/
double a[2][3] = {{1.0, 2.0, 3.0}, {4.0, 5.0, 6.0}};
double b[3][2] = {{1.0, 0.0}, {0.0, 1.0}, {0.0, 0.0}};
double c[2][2];
seki(2, 3, 2, &a[0][0], &b[0][0], &c[0][0]);
/*
結果の出力
*/
int i1, i2;
for (i1 = 0; i1 < 2; i1++) {
for (i2 = 0; i2 < 2; i2++)
printf("%f ", c[i1][i2]);
printf("\n");
}
return 0;
}
/**************************************/
/* 行列の積 */
/* n,m,l : 次元数 */
/* a : n x m */
/* b : m x l */
/* c : 計算結果が入る行列,n x l */
/**************************************/
void seki(int n, int m, int l, double *a, double *b, double *c)
{
int i1, i2, i3;
for (i1 = 0; i1 < n; i1++) {
for (i2 = 0; i2 < l; i2++) {
c[l*i1+i2] = 0;
for (i3 = 0; i3 < m; i3++)
c[l*i1+i2] += a[m*i1+i3] * b[l*i3+i2]; /* 添え字に注意 */
}
}
}
int (*sub)(double, char *)
int add(int a, int b)
{
return a + b;
}
int main()
{
int (*fun)(int, int) = &add;
printf("和 %d\n", fun(2, 3));
return 0;
}

xn+1 = xn - f(xn) / f'(xn)
/****************************/
/* 関数名の受け渡し */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
double newton(double(*)(double), double(*)(double),
double, double, double, int, int *);
double snx(double);
double dsnx(double);
int main()
{
double eps1 = 1.0e-7;
double eps2 = 1.0e-10;
double x0 = 0.0;
int max = 20, ind;
double x = newton(snx, dsnx, x0, eps1, eps2, max, &ind);
printf("ind=%d x=%f f=%f df=%f\n",ind,x,snx(x),dsnx(x));
return 0;
}
/*****************************************************/
/* Newton法による非線形方程式(f(x)=0)の解 */
/* fn : f(x)を計算する関数名 */
/* dfn : f(x)の微分を計算する関数名 */
/* x0 : 初期値 */
/* eps1 : 終了条件1(|x(k+1)-x(k)|<eps1) */
/* eps2 : 終了条件2(|f(x(k))|<eps2) */
/* max : 最大試行回数 */
/* ind : 実際の試行回数 */
/* (負の時は解を得ることができなかった) */
/* return : 解 */
/*****************************************************/
#include <math.h>
double newton(double(*f)(double), double(*df)(double),
double x0, double eps1, double eps2, int max, int *ind)
{
double x1 = x0;
double x = x1;
int sw = 0;
*ind = 0;
while (sw == 0 && *ind >= 0) {
sw = 1;
*ind += 1;
double g = (*f)(x1);
if (fabs(g) > eps2) {
if (*ind <= max) {
double dg = (*df)(x1);
if (fabs(dg) > eps2) {
x = x1 - g / dg;
if (fabs(x-x1) > eps1 && fabs(x-x1) > eps1*fabs(x)) {
x1 = x;
sw = 0;
}
}
else
*ind = -1;
}
else
*ind = -1;
}
}
return x;
}
/************************/
/* 関数値(f(x))の計算 */
/************************/
double snx(double x)
{
double y = exp(x) - 3.0 * x;
return y;
}
/********************/
/* 関数の微分の計算 */
/********************/
double dsnx(double x)
{
double y = exp(x) - 3.0;
return y;
}
ind=5 x=0.619061 f=0.000000 df=-1.142816
---------------------(C++11)関数オブジェクトとラムダ式-------------------------
/******************************/
/* 関数オブジェクトとラムダ式 */
/* coded by Y.Suganuma */
/******************************/
#include <stdio.h>
#include <math.h>
class Snx
{
public:
double operator() (double x)
{
return (double)(exp(x) - 3.0 * x);
}
};
class DSnx
{
public:
double operator() (double x)
{
return (double)(exp(x) - 3.0);
}
};
double newton1(auto, auto, double, double, double, int, int *); // ラムダ式
double newton2(Snx, DSnx, double, double, double, int, int *); // 関数オブジェクト
int main()
{
double eps1 = 1.0e-7;
double eps2 = 1.0e-10;
double x0 = 0.0;
int max = 20, ind;
// ラムダ式
auto snx1 = [](double x){ return exp(x) - 3.0 * x; };
auto dsnx1 = [](double x){ return exp(x) - 3.0; };
double x = newton1(snx1, dsnx1, x0, eps1, eps2, max, &ind);
printf("ind=%d x=%f f=%f df=%f\n",ind, x, snx1(x), dsnx1(x));
// 関数オブジェクト
Snx snx2;
DSnx dsnx2;
x = newton2(snx2, dsnx2, x0, eps1, eps2, max, &ind);
printf("ind=%d x=%f f=%f df=%f\n",ind, x, snx2(x), dsnx2(x));
return 0;
}
/*****************************************************/
/* Newton法による非線形方程式(f(x)=0)の解 */
/* fn : f(x)を計算する関数 */
/* dfn : f(x)の微分を計算する関数 */
/* x0 : 初期値 */
/* eps1 : 終了条件1(|x(k+1)-x(k)|<eps1) */
/* eps2 : 終了条件2(|f(x(k))|<eps2) */
/* max : 最大試行回数 */
/* ind : 実際の試行回数 */
/* (負の時は解を得ることができなかった) */
/* return : 解 */
/*****************************************************/
// ラムダ式
double newton1(auto f, auto df, double x0, double eps1, double eps2, int max, int *ind)
{
double x1 = x0;
double x = x1;
int sw = 0;
*ind = 0;
while (sw == 0 && *ind >= 0) {
sw = 1;
*ind += 1;
double g = f(x1);
if (fabs(g) > eps2) {
if (*ind <= max) {
double dg = df(x1);
if (fabs(dg) > eps2) {
x = x1 - g / dg;
if (fabs(x-x1) > eps1 && fabs(x-x1) > eps1*fabs(x)) {
x1 = x;
sw = 0;
}
}
else
*ind = -1;
}
else
*ind = -1;
}
}
return x;
}
// 関数オブジェクト
double newton2(Snx f, DSnx df, double x0, double eps1, double eps2, int max, int *ind)
{
double x1 = x0;
double x = x1;
int sw = 0;
*ind = 0;
while (sw == 0 && *ind >= 0) {
sw = 1;
*ind += 1;
double g = f(x1);
if (fabs(g) > eps2) {
if (*ind <= max) {
double dg = df(x1);
if (fabs(dg) > eps2) {
x = x1 - g / dg;
if (fabs(x-x1) > eps1 && fabs(x-x1) > eps1*fabs(x)) {
x1 = x;
sw = 0;
}
}
else
*ind = -1;
}
else
*ind = -1;
}
}
return x;
}
----------------------(C++11)関数オブジェクトとラムダ式終わり--------------------
/****************************/
/* 関数名の配列 */
/* coded by y.suganuma */
/****************************/
#include <stdio.h>
/*
FP は 2 つの int の引数を受け取り,int を返す関数へのポインタであると宣言
*/
typedef int (*FP) (int, int);
/*
4つの関数を宣言
*/
int add(int, int);
int sub(int, int);
int mul(int, int);
int div(int, int);
int main()
{
int i1, x = 12;
FP f_tb[] = {&add, &sub, &mul, &div}; /* 関数へのポインタ配列 */
for (i1 = 0; i1 < 4; i1++)
printf("result %d\n", f_tb[i1](x, i1+1));
return 0;
}
/********/
/* 加算 */
/********/
int add(int x, int y)
{
return (x + y);
}
/********/
/* 減算 */
/********/
int sub(int x, int y)
{
return (x - y);
}
/********/
/* 乗算 */
/********/
int mul(int x, int y)
{
return (x * y);
}
/********/
/* 除算 */
/********/
int div(int x, int y)
{
return (x / y);
}
result 13 result 10 result 36 result 3
データ型 &別名 = 式;
int &y = x;
x = 10; y = 10;
const
/****************************/
/* 参照渡し */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
void sub(int &, int, int *, char *&, char *, char *);
int main()
{
int x = 10, y = 20, z = 0;
char *d1 = new char[6] {'d', 'a', 't', 'a', '1'};
char *d2 = new char[6] {'d', 'a', 't', 'a', '2'};
char d3[6] = "data3";
printf("x %d y %d z %d d1 %s d2 %s d3 %s\n", x, y, z, d1, d2, d3);
sub(x, y, &z, d1, d2, d3);
printf("x %d y %d z %d d1 %s d2 %s d3 %s\n", x, y, z, d1, d2, d3);
return 0;
}
/********************************/
/* 参照渡しの例 */
/* a : intの参照渡し */
/* b : intのデータ渡し */
/* c : intのアドレス渡し */
/* c1 : アドレスの参照渡し */
/* c2 : アドレスの通常渡し */
/* c3 : 配列の通常渡し */
/********************************/
void sub(int &a, int b, int *c, char *&c1, char *c2, char *c3)
// void sub(const int a, ・・・) とすれば,a の値を変更できない
{
a += 5;
b += 5;
*c = a + b;
c3[1] = 'x';
c1++;
c2++;
c3++;
printf("a %d b %d c %d c1 %s c2 %s c3 %s\n", a, b, *c, c1, c2, c3);
}
x 10 y 20 z 0 d1 data1 d2 data2 d3 data3 a 15 b 25 c 40 c1 ata1 c2 ata2 c3 xta3 x 15 y 20 z 40 d1 ata1 d2 data2 d3 dxta3
/****************************/
/* 参照渡し(参照型関数) */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int x = 10;
int &sub(int);
int main()
{
int y = 20;
printf("x %d y %d\n", x, y);
/*
現在の変数xの値の参照(関数を右辺)
*/
y = sub(5);
printf("x %d y %d\n", x, y);
/*
変数xに結果を代入(関数を左辺)
*/
sub(100) += 3; // 以下の 2 行でも可
// int& (*z)(int) = ⊂
// z(100) += 3;
printf("x %d y %d\n", x, y);
return 0;
}
/*********************/
/* 関数が変数xの別名 */
/*********************/
int &sub(int a)
{
x += a;
return x;
}
x 10 y 20 x 15 y 15 x 118 y 15
---------------------(C++11)右辺値参照・ムーブセマンティクス-------------------------
int x1 = 10; int& x2 = 10; // error int& x2 = x1; // 左辺値参照 int&& y1 = x1; // error int&& y2 = 20; // 右辺値参照
01 #include <iostream>
02 #include <string>
03
04 using namespace std;
05
06 class Test {
07 public:
08 int *data;
09 // コンストラクタ
10 Test() {
11 data = new int [10000];
12 cout << " (コンストラクタ)";
13 }
14 // copy コンストラクタ
15 Test(const Test& da) {
16 data = new int [10000];
17 copy(da.data, da.data+10000, data);
18 cout << " (copyコンストラクタ)";
19 }
20 // move コンストラクタ
21 Test(Test&& t)
22 {
23 data = t.data;
24 t.data = nullptr;
25 cout << " (moveコンストラクタ)";
26 }
27 // デストラクタ
28 ~Test() {
29 delete [] data;
30 }
31 };
32
33 int main()
34 {
35 // 右辺値参照
36 string&& x = "abc";
37 string y = x;
38 // string&& z = y; // エラー
39 // string&& z = x; // エラー
40 cout << "右辺値参照 x " << x << " &x " << &x << " y " << y << " &y " << &y << endl;
41 x = "xxx";
42 cout << " xを変更 x " << x << " &x " << &x << " y " << y << " &y " << &y << endl;
43 y = "yyy";
44 cout << " yを変更 x " << x << " &x " << &x << " y " << y << " &y " << &y << endl;
45 // move
46 string m3 = "abc";
47 string m4 = m3;
48 cout << "m3 を m4 に代入(普通)m3 " << m3 << " &m3 " << &m3 << " m4 " << m4 << " &m4 " << &m4 << endl;
49 // move(m3); // 何も起こらない
50 string m5 = move(m3);
51 cout << "m3 を m5 に代入(move)m3 " << m3 << " &m3 " << &m3 << " m5 " << m5 << " &m5 " << &m5 << endl;
52 // 右辺値参照の利用
53 cout << "tm を宣言";
54 Test tm{}; // Test tm = Test();
55 tm.data[10] = 10;
56 cout << " tm.data[10] = " << tm.data[10] << endl;
57
58 cout << "tm を t1 に代入,tm の data 変更";
59 Test t1 = tm;
60 tm.data[10] = 20;
61 cout << " t1.data[10] = " << t1.data[10] << " tm.data[10] = " << tm.data[10] << endl;
62
63 cout << "tm を move し t2 へ";
64 Test t2 = move(tm); // tmpは以後使用しない
65 cout << " t2.data[10] = " << t2.data[10] << " tm.data = nullptr\n";
66
67 return 0;
68 }
右辺値参照 x abc &x 0x61fe88 y abc &y 0x61fea0
xを変更 x xxx &x 0x61fe88 y abc &y 0x61fea0
yを変更 x xxx &x 0x61fe88 y yyy &y 0x61fea0
m3 を m4 に代入(普通)m3 abc &m3 0x61feb8 m4 abc &m4 0x61fed0 m3 を m5 に代入(move)m3 &m3 0x61feb8 m5 abc &m5 0x61fee8
tm を宣言 (コンストラクタ) tm.data[10] = 10 tm を t1 に代入,tm の data 変更 (copyコンストラクタ) t1.data[10] = 10 tm.data[10] = 20 tm を move し t2 へ (moveコンストラクタ) t2.data[10] = 20 tm.data = nullptr
----------------------(C++11)右辺値参照・ムーブセマンティクス終わり--------------------
int main()
add 2 3
int main ( int argc, char *argv[], char *envp[] )
/******************************/
/* main関数の引数(数字の和) */
/* coded by Y.Suganuma */
/******************************/
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{
/*
引数の内容の出力
*/
printf(" 引数の数 %d\n",argc);
printf(" プログラム名 %s\n",argv[0]);
int i1, k, sum = 0;
for (i1 = 1; i1 < argc; i1++) {
k = atoi(argv[i1]); /* 文字を整数に変換 */
printf(" %d 番目の引数 %d\n", i1+1, k);
sum += k;
}
/*
結果の表示
*/
printf("結果=%d\n", sum);
return 0;
}
引数の数 3
プログラム名 test
2 番目の引数 2
3 番目の引数 3
結果=5
/*******************************/
/* main関数(環境変数の出力) */
/* coded by Y.Suganuma */
/*******************************/
#include <stdio.h>
int main(int argc, char *argv[], char *envp[])
{
int i1 = 0;
while (envp[i1] != NULL) {
printf("%d %s\n", i1+1, envp[i1]);
i1++;
}
return 0;
}
/****************************/
/* 関数名のオーバーロード */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
/****************/
/* 文字列の出力 */
/****************/
void print(char* moji)
{
printf("%s\n", moji);
}
/*****************/
/* double の出力 */
/*****************/
void print(double dbd)
{
printf("%f\n", dbd);
}
/**************/
/* int の出力 */
/**************/
void print(int ind)
{
printf("%d\n", ind);
}
/********/
/* main */
/********/
int main()
{
// 以下,データの型に対応した関数が選択される
print("moji-retu");
print(3.14);
print(100);
return 0;
}
moji-retu 3.140000 100
inline int sub(int x, ・・・)
/*********************************/
/* インライン関数と#defineマクロ */
/* coded by Y.Suganuma */
/*********************************/
#include <stdio.h>
#include <math.h>
#include <time.h>
#define ookisa(x, y) sqrt(x * x + y * y) /* マクロによる計算 */
inline double length1(double, double);
double length2(double, double);
int main()
{
double a = 3.0;
double b = 4.0;
double x;
long i1;
clock_t c1, c2;
/*
マクロによる計算
*/
c1 = clock();
for (i1 = 0; i1 < 1000000; i1++)
x = ookisa(a, b);
c2 = clock();
printf("計算時間は %f 秒です(マクロ)\n", (double)(c2-c1)/CLOCKS_PER_SEC);
/*
インライン関数
*/
c1 = c2;
for (i1 = 0; i1 < 1000000; i1++)
x = length1(a, b);
c2 = clock();
printf("計算時間は %f 秒です(インライン関数)\n", (double)(c2-c1)/CLOCKS_PER_SEC);
/*
普通の関数
*/
c1 = c2;
for (i1 = 0; i1 < 1000000; i1++)
x = length2(a, b);
c2 = clock();
printf("計算時間は %f 秒です(普通の関数)\n", (double)(c2-c1)/CLOCKS_PER_SEC);
return 0;
}
/***************************/
/* sqrt(x*x+y*y)(inline) */
/* x,y : 2つのデータ */
/* return : 結果 */
/***************************/
inline double length1(double x, double y)
{
return sqrt(x * x + y * y);
}
/*******************************/
/* sqrt(x*x+y*y)(普通の関数) */
/* x,y : 2つのデータ */
/* return : 結果 */
/*******************************/
double length2(double x, double y)
{
return sqrt(x * x + y * y);
}
計算時間は 35 秒です(マクロ) 計算時間は 39 秒です(インライン関数) 計算時間は 40 秒です(普通の関数)
/****************************/
/* 例外処理 */
/* coded by Y.Suganuma */
/****************************/
#include <iostream>
#include <math.h>
using namespace std;
void sq(double x, double y)
{
if (x < 0.0 && y < 0.0) {
char *str = "両方とも負\n";
throw str;
}
else if (x < 0.0 || y < 0.0) {
char *str = "片方が負\n";
throw str;
}
double z = sqrt(x+y);
cout << z << endl;
}
int main()
{
try {
double x, y;
cout << "1 つ目のデータは? ";
cin >> x;
cout << "2 つ目のデータは? ";
cin >> y;
sq(x, y);
}
catch (char *str)
{
cout << str;
}
return 0;
}
1.73205 両方とも負
/****************************/
/* 例外処理 */
/* coded by Y.Suganuma */
/****************************/
#include <iostream>
#include <math.h>
#include <string.h>
using namespace std;
class Negative {
public:
char *str;
double x, y;
Negative(char *str, double x, double y) {
this->str = new char [100];
strcpy(this->str, str);
this->x = x;
this->y = y;
}
void message(int sw) {
if (sw == 0)
cout << " 1 番目の値を正にして再実行しました\n";
else
cout << " データを修正してください\n";
}
};
void sq(double x, double y)
{
if (x < 0.0 && y < 0.0)
throw Negative("両方とも負\n", x, y);
else if (x < 0.0 || y < 0.0)
throw Negative("片方が負\n", x, y);
double z = sqrt(x+y);
cout << z << endl;
}
int main()
{
try {
double x, y;
cout << "1 つ目のデータは? ";
cin >> x;
cout << "2 つ目のデータは? ";
cin >> y;
sq(x, y);
}
catch (Negative &ng)
{
cout << ng.str;
if (ng.y > 0.0) {
ng.message(0);
sq(-ng.x, ng.y);
}
else
ng.message(1);
}
return 0;
}
片方が負
1 番目の値を正にして再実行しました
1.73205 ---------------------(C++11)例外処理-------------------------
int function( ・・・・・ ) noexcept
{
・・・・・
} ----------------------(C++11)例外処理終わり--------------------
| 情報学部 | 菅沼ホーム | 全体目次 | 演習解答例 | 付録 | 索引 |