

| 情報学部 | 菅沼ホーム | 全体目次 | 演習解答例 | 付録 | 索引 |
double x[10];
// 初期設定する場合(いずれの方法でも可)
double x[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
double x[10] {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // 初期化子リスト(C++11)
double x[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
double x[] {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; // 初期化子リスト(C++11) const int n = 10; // n の値は変更できない double x[n];
int n;
printf("データの数を入力してください ");
scanf("%d", &n);
double x[n]; // 最近の C では可能 x[5] = 3.0; y = x[3];
for (i1 = 1; i1 <= 14; i1++) // i1 の値に注意 y[i1-1] = x[i1];
char c = 'x';
char z[10];
scanf("%c", &z[2]); // z の 3 番目の要素に 1 文字入力する
scanf("%s", z); // 9 文字以下の文字列を入力する
// (文字列の最後に \0 が付加される)
printf("%c\n", z[2]); // z の 3 番目の要素を出力する
printf("%s\n", z); // 文字列を出力する ---------------------(C++11)範囲 for 文-------------------------
for (変数宣言 : 範囲) {
文(複数の文も可)
}
void sub(int x[]) {
for (auto a : x)
printf("%d ", a);
printf("\n");
}
int main() {
int x[] = {4, 5, 6};
for (auto a : x)
printf("%d ", a);
printf("\n");
return 0;
}
01 /****************************/
02 /* 範囲 for 文 */
03 /* coded by Y.Suganuma */
04 /****************************/
05 #include <iostream>
06 #include <vector>
07 #include <map>
08
09 using namespace std;
10
11 int main()
12 {
13 // 配列
14 cout << "*** array ***\n";
15 int k = 0, a[5];
16 // for (int& x : a) {
17 for (auto& x : a) {
18 cout << (k+1) << " 番目のデータ? ";
19 cin >> x;
20 k++;
21 }
22 // 従来の for 文
23 /*
24 for (int i1 = 0; i1 < 5; i1++) {
25 cout << (i1+1) << " 番目のデータ? ";
26 cin >> a[i1];
27 }
28 */
29 // for (int x : a)
30 for (auto x : a)
31 cout << " " << x;
32 cout << endl;
33 // 従来の for 文
34 /*
35 for (int i1 = 0; i1 < 5; i1++)
36 cout << " " << a[i1];
37 cout << endl;
38 */
39 // vector*
40 cout << "*** vector ***\n";
41 vector<int> v {10, 20, 30, 40, 50};
42 // for (int x : v)
43 for (auto x : v)
44 cout << " " << x;
45 cout << endl;
46 // 従来の for 文
47 /*
48 for (unsigned int i1 = 0; i1 < v.size(); i1++)
49 cout << " " << v[i1];
50 cout << endl;
51 */
52 // map
53 cout << "*** map ***\n";
54 map<string, int> mp {{"tanaka", 90}, {"suzuki", 100}, {"sato", 70}};
55 // for (pair<string, int> x : mp)
56 for (auto x : mp)
57 cout << " (" << x.first << ", " << x.second << ")";
58 cout << endl;
59 // 従来の for 文
60 /*
61 map<string, int>::iterator it;
62 for (it = mp.begin(); it != mp.end(); it++)
63 cout << " (" << (*it).first << ", " << (*it).second << ")";
64 cout << endl;
65 */
66
67 return 0;
68 }
1 番目のデータ? 1 2 番目のデータ? 2 3 番目のデータ? 3 4 番目のデータ? 4 5 番目のデータ? 5 1 2 3 4 5 *** vector *** 10 20 30 40 50 *** map *** (sato, 70) (suzuki, 100) (tanaka, 90)
----------------------(C++11)範囲 for 文終わり--------------------
/********************************/
/* 平均値の計算と平均値以下の人 */
/* coded by Y.Suganuma */
/********************************/
#include <stdio.h>
int main()
{
/*
データの数の読み込み
*/
int n;
printf("人数は? ");
scanf("%d", &n);
if (n <= 0 || n > 50)
printf("人数が不適当です\n");
/*
データの読み込み
*/
else {
int i1;
double mean = 0.0;
double x[50];
for (i1 = 0; i1 < n; i1++) {
printf("%d 番目の人の点は? ", i1+1);
scanf("%lf", &(x[i1]));
mean += x[i1];
}
/*
平均値の計算と出力
*/
mean /= n;
printf(" 平均値は=%f\n", mean);
/*
平均値以下の人を調べ,出力
*/
for (i1 = 0; i1 < n; i1++) {
if (x[i1] <= mean)
printf(" %d番 %f点\n", i1+1, x[i1]);
}
}
return 0;
}
printf("%f\n", x[51]);
x[55] = 3.6;
/****************************/
/* 平方根の計算 */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
#include <math.h>
int main()
{
/*
ファイル名の入力
*/
char f_name[50];
printf("出力ファイル名は? ");
scanf("%s", f_name);
/*
平方根の計算
*/
double data = 0.0;
double x[100], y[100];
int i1;
for (i1 = 0; i1 < 100; i1++) {
data += 1.0;
x[i1] = data;
y[i1] = sqrt(data);
}
/*
出力
*/
FILE *out = fopen(f_name, "w");
for (i1 = 0; i1 < 100; i1++)
fprintf(out, "%f %f\n", x[i1], y[i1]);
return 0;
}
/****************************/
/* 大文字から小文字への変換 */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int main()
{
/*
データ数の入力
*/
char c[50];
printf("大文字の文字列を入力してください(49字以内) ");
scanf("%s", c);
/*
小文字へ変換
*/
int k = 0;
while (c[k] != '\0') {
c[k] += 32;
k++;
}
/*
出力
*/
printf("%s\n", c);
return 0;
}
int x[4] = {100, 200, 300, 400}; // 各要素の初期設定も行っている
int *y; // int y[4]; と宣言した場合は,y = x; は実行できない
char *c; 
y = x; または y = &(x[0]);
int *x = new int [4];
for (int i1 = 0; i1 < 4; i1++)
x[i1] = 100 * (i1 + 1);
// C++11 以降であれば,上 3 行の代わりに下の 1 行で可能
//int *x = new int [4] {100, 200, 300, 400}; // 初期化子リスト,C++11
int *y;
char *c; 
y++; *y = ・・・;
*y = ・・・; *(y+1) = ・・・; a = *(y+2); ・・・
c = (char *)x; c++;
01 int x1[4] = {1, 2};
02 int x2[] = {1, 2};
03 int *x3 = {1, 2}; // 誤り
04 char c1[15] = {"test data"}; // char c1[15] = "test data"; でも可
05 char c2[] = {"test data"}; // char c2[] = "test data"; でも可
06 int x4[4] = {0}; // すべての要素が 0 で初期設定される
07 int x5[4] = {}; // 上と同様
08 int x6[4] {1, 2}; // C++11 以降では可能(初期化子リスト)
09 int x7[] {1, 2}; // C++11 以降では可能(初期化子リスト)
/****************************/
/* 配列とポインタ */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int main()
{
/*
初期設定された値と確保された領域のサイズ
*/
int i1;
int x2[6] = {1, 2, 3, 4, 5, 6}; /* 6つのデータ領域 */
for (i1 = 0; i1 < 6; i1++)
printf("%d ", x2[i1]);
printf("(%dバイト)\n", sizeof(x2));
int x3[] = {1, 2, 3, 4}; /* 4つのデータ領域 */
for (i1 = 0; i1 < 4; i1++)
printf("%d ", x3[i1]);
printf("(%dバイト)\n", sizeof(x3));
char c1[15] = {"test data"}; /* 15個のデータ領域 */
char c2[] = {"test data"}; /* 10個のデータ領域 */
printf("%s (%dバイト)\n", c1, sizeof(c1));
printf("%s (%dバイト)\n", c2, sizeof(c2));
/*
要素の参照と変更
*/
int *x1 = x2; // x1 = &x2[0]の意味
x1[1] = -1;
*(x1+2) = -2;
x2[3] = -3;
*(x2+4) = -4;
for (i1 = 0; i1 < 6; i1++)
printf("%d ", x1[i1]);
printf("\n");
for (i1 = 0; i1 < 6; i1++)
printf("%d ", x2[i1]);
printf("\n");
char *c3 = c2;
c3[6] = '\0';
printf("%s (%dバイト)\n", c2, sizeof(c2));
printf("%s (%dバイト)\n", c3, sizeof(c3));
return 0;
}
1 2 3 4 5 6 (24バイト) 1 2 3 4 (16バイト) test data (15バイト) test data (10バイト) 1 -1 -2 -3 -4 6 1 -1 -2 -3 -4 6 test d (10バイト) test d (4バイト)
int a[3][2]; // 初期設定を行わない場合
int x[3][2] = {{100, 200}, {300, 400}, {500, 600}}; // 以下のいずれの方法でも可
//int x[][2] = {{100, 200}, {300, 400}, {500, 600}};
//int x[3][2] {{100, 200}, {300, 400}, {500, 600}}; // C++11
//int x[][2] {{100, 200}, {300, 400}, {500, 600}}; // C++11 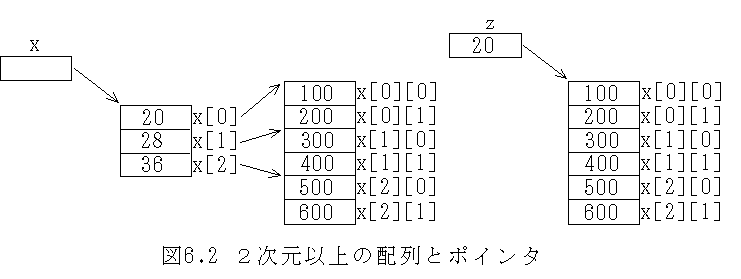

int **y = x;
int *w[3]; // w は,int に対するポインタの配列 int **y = &(w[0]); // int **y = w; でも良い w[0] = x[0]; w[1] = x[1]; w[2] = x[2];
int **x = new int *[3];
for (int i1 = 0; i1 < 3; i1++)
x[i1] = new int[2];
// 以下のようにすれば,上と同じ値で初期設置も可能
int **x = new int *[3];
x[0] = new int[2] {100, 200};
x[1] = new int[2] {300, 400};
x[2] = new int[2] {500, 600}; int **y = x;
int *z = (int *)x; // int *z = &x[0][0]; でも良い
int *z = x[1]; //int *z = &x[1][0]; でも OK
int x1[][] = {{1, 2}, {3, 4}, {5, 6}}; // 誤り int x1[3][2] = {{1, 2}, {3, 4}, {5, 6}}; // 3行2列 int x1[3][2] {{1, 2}, {3, 4}, {5, 6}}; // 3行2列,C++11 int x2[][2] = {{1, 2}, {3, 4}}; // 2行2列 int x2[][2] {{1, 2}, {3, 4}}; // 2行2列,C++11 int x3[3][] = {{1, 2}, {3, 4}}; // 誤り char c1[5][10] = {"zero", "one", "two", "three"}; // 5行10列 char c2[][10] = {"zero", "one", "two", "three"}; // 4行10列 char c4[5][] = {"zero", "one", "two", "three"}; // 誤り
/****************************/
/* 2次元配列とポインタ */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int main()
{
int x1[3][2] = {{1, 2}, {3, 4}, {5, 6}}; /* 3行2列 */
int x2[][2] = {{1, 2}, {3, 4}}; /* 2行2列 */
char c1[5][10] = {"zero", "one", "two", "three"}; /* 5行10列 */
char c2[][10] = {"zero", "one", "two", "three"}; /* 4行10列 */
char *c3[] = {"zero", "one", "two", "three"}; /* 4つのポインタ */
int *px, *px1;
char *pc;
/*
初期設定された値と確保された領域のサイズ
*/
printf("%d (%dバイト)\n", x1[1][1], sizeof(x1));
printf("%d (%dバイト)\n", x2[1][1], sizeof(x2));
printf("%s (%dバイト)\n", c1[3], sizeof(c1));
printf("%s (%dバイト)\n", c2[3], sizeof(c2));
printf("%s (%dバイト)\n", c3[3], sizeof(c3));
/*
要素の参照
*/
px = (int *)x1;
px1 = x1[2];
pc = &(c1[2][0]);
printf("%d %d %d %d\n", x1[2][1], px[5], *(px+5), px1[1]);
printf("%c%c%c %s\n", c1[2][0], pc[1], *(pc+2), pc);
return 0;
}
4 (24バイト) 4 (16バイト) three (50バイト) three (40バイト) 6 6 6 6 two two
int x[4][3][2]; // 初期設定等で省略できるのは 4 という値だけ

int ***y;
int *z = (int *)x; // int *z = &x[0][0][0];
int ***x = new int **[4];
for (int i1 = 0; i1 < 4; i1++) {
x[i1] = new int *[3];
for (int i2 = 0; i2 < 3; i2++)
x[i1][i2] = new int[2];
} int ***y = x; // x と同じ 3 次元配列 int **z = x[1]; // x[1][][] に対応する 2 次元配列 int *w = x[1][0]; // x[1][0][] に対応する 1 次元配列
/****************************/
/* 3次元配列とポインタ */
/* coded by Y.Suganuma */
/****************************/
#include <stdio.h>
int main()
{
int i1, x[4][3][2], *x1[4][3], **x2[4];
for (i1 = 0; i1 < 4; i1++) {
int i2;
for (i2 = 0; i2 < 3; i2++)
x1[i1][i2] = x[i1][i2];
}
for (i1 = 0; i1 < 4; i1++)
x2[i1] = x1[i1];
int **x3 = x2[2]; // x[2][][] を 2 次元配列として処理
int ***y = &x2[0]; // int ***y = x2;,x と同じ 3 次元配列
x[2][1][0] = 100;
printf("%d %d %d\n", x[2][1][0], y[2][1][0], x3[1][0]); // 全て100
int *z = (int *)x; // int *z = &x[0][0][0];
z[((2*3)+1)*2+0] = 1000; // 1 次元配列として処理
printf("%d %d %d %d\n", x[2][1][0], y[2][1][0], x3[1][0], z[((2*3)+1)*2+0]); // 全て1000
return 0;
}
/* 以下,new 演算子を使用した場合
#include <stdio.h>
int main()
{
int ***x = new int **[4];
for (int i1 = 0; i1 < 4; i1++) {
x[i1] = new int *[3];
for (int i2 = 0; i2 < 3; i2++)
x[i1][i2] = new int [2];
}
int **x3 = x[2]; // x[2][][] を 2 次元配列として処理
int ***y = x; // x と同じ 3 次元配列
x[2][1][0] = 100;
printf("%d %d %d\n", x[2][1][0], y[2][1][0], x3[1][0]); // 全て100
int *z = x[2][1]; // x[2][1][] を 1 次元配列として処理
z[0] = 1000;
printf("%d %d %d %d\n", x[2][1][0], y[2][1][0], x3[1][0], z[0]); // 全て1000
return 0;
}
*/
// int x[5000000]; // 実行できない
// int *x = (int *)malloc(5000000 * sizeof(int)); // 実行可
int *x = new int [5000000]; // 実行可
x[4999999] = 100;
printf("%d\n", x[4999999]);
int a[50][3];
/**********************************/
/* メモリの動的確保(1次元配列) */
/* coded by Y.Suganuma */
/**********************************/
#include <stdio.h>
#include <stdlib.h>
int main()
{
/*
データの数
*/
int n;
printf("データの数は? ");
scanf("%d", &n);
/*
領域の確保
*/
int *x = (int *)malloc(n * sizeof(int));
/*
データの入力と和の計算
*/
int i1, sum = 0;
for (i1 = 0; i1 < n; i1++) {
printf(" %d 番目のデータを入力してください ", i1+1);
scanf("%d", &x[i1]);
sum += x[i1];
}
printf("和 = %d\n", sum);
/*
領域の開放
*/
free(x);
return 0;
}
/**********************************/
/* メモリの動的確保(2次元配列) */
/* coded by Y.Suganuma */
/**********************************/
#include <stdio.h>
#include <stdlib.h>
int main()
{
/*
データの数
*/
int m, n;
printf("クラスの人数は? ");
scanf("%d", &n);
printf("科目の数は? ");
scanf("%d", &m);
/*
領域の確保
*/
int **ten = (int **)malloc(n * sizeof(int *));
int *mean = (int *)calloc(m, sizeof(int));
/*
データの入力と和の計算
*/
int i1;
for (i1 = 0; i1 < n; i1++) {
ten[i1] = (int *)calloc(m, sizeof(int));
printf("%d 番目の学生\n", i1+1);
int i2;
for (i2 = 0; i2 < m; i2++) {
printf(" %d 番目の科目の点数は? ", i2+1);
scanf("%d", &ten[i1][i2]);
mean[i2] += ten[i1][i2];
}
}
/*
平均の出力
*/
printf("各科目の平均点は以下の通りです\n");
for (i1 = 0; i1 < m; i1++)
printf(" %d", mean[i1]/n);
printf("\n");
/*
領域の開放
*/
free(ten);
free(mean);
return 0;
}
int *pi = new int; // 2 で初期設定したい場合は,new int (2);
delete pi;
double *dp = new double [10]; // 10個のdouble型データを記憶
// 10の部分は変数でも構わない
・・・・・
delete [] dp;
int *x = new int [5] {1, 2, 3, 4, 5}; // 初期設定も可能C++11
int *x = new int [5] = {1, 2, 3, 4, 5}; // error
int *x = new int [] {1, 2, 3, 4, 5}; // error 
double** pd = new double* [2];
for (i1 = 0; i1 < 2; i1++)
pd[i1] = new double [3];
// 初期設定を行う場合C++11
double** pd = new double* [2];
pd[0] = new double [3] {1, 2, 3};
pd[1] = new double [3] {4, 5, 6}; for (i1 = 0; i1 < 2; i1++) delete [] pd[i1]; delete [] pd;
/**************************************/
/* メモリの動的確保(1次元配列,new) */
/* coded by Y.Suganuma */
/**************************************/
#include <stdio.h>
int main()
{
/*
データの数
*/
int n;
printf("データの数は? ");
scanf("%d", &n);
/*
領域の確保
*/
int *x = new int [n];
/*
データの入力と和の計算
*/
int sum = 0;
for (int i1 = 0; i1 < n; i1++) {
printf(" %d 番目のデータを入力してください ", i1+1);
scanf("%d", &x[i1]);
sum += x[i1];
}
printf("和 = %d\n", sum);
/*
領域の開放
*/
delete [] x;
return 0;
}
/**************************************/
/* メモリの動的確保(2次元配列,new) */
/* coded by Y.Suganuma */
/**************************************/
#include <stdio.h>
int main()
{
/*
データの数
*/
int m, n;
printf("クラスの人数は? ");
scanf("%d", &n);
printf("科目の数は? ");
scanf("%d", &m);
/*
領域の確保
*/
int **ten = new int * [n];
int *mean = new int [m];
for (int i1 = 0; i1 < m; i1++)
mean[i1] = 0;
/*
データの入力と和の計算
*/
for (int i1 = 0; i1 < n; i1++) {
ten[i1] = new int [m]; // 学生毎に科目数を変えることも可
printf("%d 番目の学生\n", i1+1);
for (int i2 = 0; i2 < m; i2++) {
printf(" %d 番目の科目の点数は? ", i2+1);
scanf("%d", &ten[i1][i2]);
mean[i2] += ten[i1][i2];
}
}
/*
平均の出力
*/
printf("各科目の平均点は以下の通りです\n");
for (int i1 = 0; i1 < m; i1++)
printf(" %d", mean[i1]/n);
printf("\n");
/*
領域の開放
*/
for (int i1 = 0; i1 < n; i1++)
delete [] ten[i1];
delete [] ten;
delete [] mean;
return 0;
}
001 /****************************/
002 /* new 演算子と代入・初期化 */
003 /* coded by Y.Suganuma */
004 /****************************/
005 #include <stdio.h>
006 #include <vector>
007
008 using namespace std;
009
010 /*****************/
011 /* クラスComplex */
012 /*****************/
013 class Complex
014 {
015 public:
016 int x, y[1], *z;
017 Complex ()
018 {
019 x = 0;
020 y[0] = 0;
021 z = new int [1];
022 z[0] = 0;
023 }
024 };
025
026 /********/
027 /* main */
028 /********/
029 int main()
030 {
031 // 単純変数
032 printf("***単純変数***\n");
033 int a1 = 0;
034 int a2 = a1;
035 a2 = 1234;
036 printf(" a1 %d\n", a1);
037 printf(" a2 %d\n", a2);
038 printf("***単純変数(new)***\n");
039 int *p1 = new int(0);
040 int *p4 = p1;
041 *p4 = 1234; // p1 が示す値も 1234 になる
042 printf(" p1 %d\n", *p1);
043 printf(" p4 %d\n", *p4);
044 // 複数データ(配列と同等)
045 printf("***配列***\n");
046 int b1[4] = {1, 2, 3, 4};
047 int b2[4];
048 for (int i1 = 0; i1 < 4; i1++)
049 b2[i1] = b1[i1];
050 b2[2] = 200;
051 printf(" b1");
052 for (int i1 = 0; i1 < 4; i1++)
053 printf(" %d", b1[i1]);
054 printf("\n b2");
055 for (int i1 = 0; i1 < 4; i1++)
056 printf(" %d", b2[i1]);
057 printf("\n***配列(new)***\n");
058 int *p2 = new int [4];
059 for (int i1 = 0; i1 < 4; i1++)
060 p2[i1] = i1 + 1;
061 int *p5 = p2; // p5 = &p2[0] と同じ
062 p5[2] = 200; // *(p5+2) = 200; と同じ
063 printf(" p2");
064 for (int i1 = 0; i1 < 4; i1++)
065 printf(" %d", p2[i1]);
066 printf("\n p5");
067 for (int i1 = 0; i1 < 4; i1++)
068 printf(" %d", p5[i1]);
069 // クラスのオブジェクト
070 printf("\n***クラスのオブジェクト***\n");
071 Complex c1;
072 Complex c2 = c1;
073 c2.x = 10;
074 c2.y[0] = 20;
075 c2.z[0] = 30;
076 printf(" c1 x %d y[0] %d z[0] %d\n", c1.x, c1.y[0], c1.z[0]);
077 printf(" c2 x %d y[0] %d z[0] %d\n", c2.x, c2.y[0], c2.z[0]);
078 printf("***クラスのオブジェクト(new)***\n");
079 Complex *p3 = new Complex();
080 Complex *p6 = p3;
081 p6->x = 10;
082 p6->y[0] = 20;
083 p6->z[0] = 30;
084 printf(" p3 x %d y[0] %d z[0] %d\n", p3->x, p3->y[0], p3->z[0]); // (*p3).x,・・・ でも可
085 printf(" p6 x %d y[0] %d z[0] %d\n", p6->x, p6->y[0], p6->z[0]); // (*p6).x,・・・ でも可
086 // STL の vector
087 printf("***STL の vector***\n");
088 vector <int> d1(4, 0);
089 vector <int> d2 = d1;
090 d2[1] = 10;
091 printf(" d1");
092 for (int i1 = 0; i1 < 4; i1++)
093 printf(" %d", d1[i1]);
094 printf("\n d2");
095 for (int i1 = 0; i1 < 4; i1++)
096 printf(" %d", d2[i1]);
097 printf("\n***STL の vector(new)***\n");
098 vector <int> *p7 = new vector <int> (4, 0);
099 vector <int> *p8 = p7;
100 (*p7)[1] = 10;
101 printf(" p7");
102 for (int i1 = 0; i1 < 4; i1++)
103 printf(" %d", (*p7)[i1]);
104 printf("\n p8");
105 for (int i1 = 0; i1 < 4; i1++)
106 printf(" %d", (*p8)[i1]);
107 printf("\n");
108 // 領域の開放
109 delete p1;
110 delete [] p2;
111 delete p3;
112 delete p7;
113
114 return 0;
115 }
***単純変数*** a1 0 a2 1234

***単純変数(new)*** p1 1234 p4 1234
***配列*** b1 1 2 3 4 b2 1 2 200 4
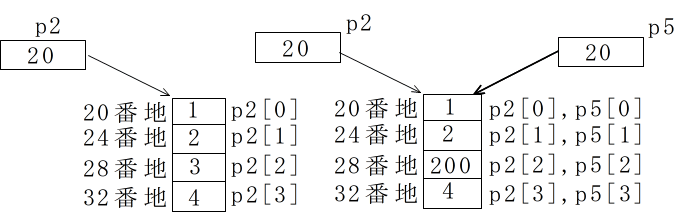
***配列(new)*** p2 1 2 200 4 p5 1 2 200 4
***クラスのオブジェクト*** c1 x 0 y[0] 0 z[0] 30 c2 x 10 y[0] 20 z[0] 30
***クラスのオブジェクト(new)*** p3 x 10 y[0] 20 z[0] 30 p6 x 10 y[0] 20 z[0] 30
***STL の vector*** d1 0 0 0 0 d2 0 10 0 0 ***STL の vector(new)*** p7 1 10 1 1 p8 1 10 1 1
RANGE NUM
0- 10 2 **
11- 20 5 *****
・・・・
91-100 3 ***
*
* *
* * ・・・・・ * *
* * * * *
-------------- ・・・・・ ---------
1 2 3 ・・・・・ 11 12
| 情報学部 | 菅沼ホーム | 全体目次 | 演習解答例 | 付録 | 索引 |