
- C++
- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.例えば,
int x[3], y[4]; //int x[3] = {1, 2, 3}; //int x[3] {1, 2, 3}; のような初期設定の可能- のように宣言すれば,3 つ,及び,4 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,x[0],x[1],x[2],y[0],y[1],y[2],y[3] のようにして参照できます.配列の大きさを表す 3 や 4 の部分は,基本的に定数である必要がありますが,gcc の新しいバージョンでは変数も許されます.しかし,汎用的な面を考慮すれば,定数に限定した方が良いと思います.実際,VC++ においては,変数を使用するとエラーになってしまいます.
- 配列は,ポインタと非常に強い関係があります.例えば,上のように宣言した場合,3 つ,及び,4 つの整数型データを記憶できる領域の先頭アドレスをポインタ変数 x,及び,y が指しているようなイメージになります.ただし,x++,x = y などの演算ができないなど,ポインタ変数とは多少異なります.
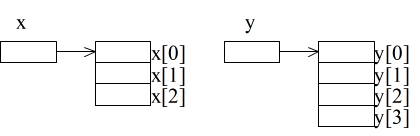
- 多次元の配列を扱うことも可能です.例えば,
int y[2][3] = {{10, 20, 30}, {40, 50, 60}}; //int y[2][3] {{10, 20, 30}, {40, 50, 60}}; も OK- のように記述すれば,2 行 3 列の表に対応する配列を定義できます.ポインタ変数との関係から考えると,以下の図に示すように,ポインタ変数 y が,2 つのポインタ変数 y[0],y[1] を記憶する領域の先頭を指し,y[0],y[1] が,各々,3 つの整数型データを記憶する領域の先頭を指すことになります.ただし,下の図に示すように,実際のデータが記憶される領域は連続的に確保されるため,
int *x = &y[0][2];
- のように記述すれば,変数 x は,4 個の要素からなる 1 次元配列として扱えます.もちろん,x を通して値を変更すれば,対応する y の値も変化します(逆も同様).
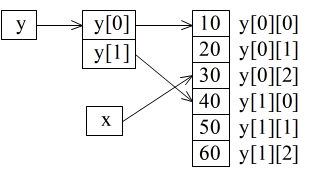
- new 演算子を使用して配列を実現することも可能です.new 演算子は,指定されたデータ型を指定された数(変数によって指定することも可能)だけ記憶できる領域を確保し,その先頭のアドレスを返す演算子です.例えば,
int *u1 = new int [3], *u2 = new int [3], *u3; // int *u1 = new int [3] {1, 2, 3}; のような初期設定も OK for (int i1 = 0; i1 < 3; i1++) { u1[i1] = i1 + 1; u2[i1] = i1 + 1; } u3 = u1;- のような記述によって,整数型のデータを 3 つ記憶できる領域が確保され,その先頭アドレスがポインタ変数 u1 に記憶されます.u2 についても同様ですが,u1 とは別の配列になります.また,各要素の参照は,配列と同じ方法で可能です.u1 は,基本データ型の一種であるポインタ変数ですので,上の 6 行目のような代入が可能です.その結果,以下に示すような状態になります.
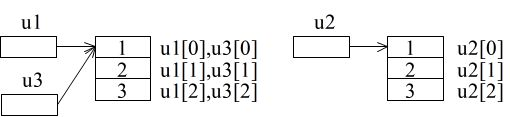
- 上の図からも明らかなように,u3 には u1 に記憶されているアドレスが記憶されるため,u1 と u3 は同じ領域を指すことになります.従って,u1 の要素の値を変更すれば,対応する u3 の要素の値も変化します(逆も同様).C++ 以外の言語においては,ポインタ変数という形では現れませんが,配列を確保する場合,ここで述べた new 演算子を使用した方法と似た結果になる場合が多いので注意してください.
- また,
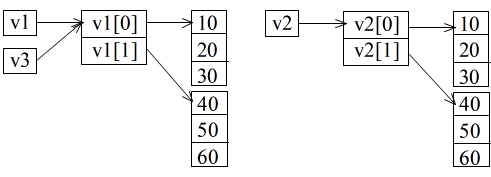
// 以下のような方法で初期設定も可能 //int ** v1 = new int* [2]; //v1[0] = new int [3] {10, 20, 30}; //v1[1] = new int [3] {40, 50, 60}; v1[0] = new int [3]; v2[0] = new int [3]; for (int i1 = 0; i1 < 3; i1++) { v1[0][i1] = 10 * (i1 + 1); v2[0][i1] = 10 * (i1 + 1); } v1[1] = new int [3]; v2[1] = new int [3]; for (int i1 = 0; i1 < 3; i1++) { v1[1][i1] = 10 * (i1 + 4); v2[1][i1] = 10 * (i1 + 4); } v3 = v1;- のように,new 演算子によって,多次元配列も実現可能です(行毎に列数を変えることも可能).そのイメージは,下に示すように,new 演算子を使用しない場合に対する多次元配列の箇所で示したものとほとんど同じです.ただし,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできませんが,例えば,
int *x = v1[1];
- のように記述すれば,変数 x は,配列 v1 の 2 行目に対応し,3 個の要素からなる 1 次元配列として扱えます.もちろん,x を通して値を変更すれば,対応する v1 の値も変化します(逆も同様).
- 今まで述べた方法では,プログラムの実行時に,要素の削除,追加等を行うことができません( new 演算子を使用した場合は多少面倒であるが可能).しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,C++ 標準ライブラリ内の vector クラスを使用することによって実現できます.vector クラスにおいては,必要な数だけのデータを追加,削除,変更等が可能です.また,
vector<int> w1, w2; ・・・ w2 = w1;
- のような代入も可能であり,w1 に含まれるすべてのデータがコピーされ,w2 に記憶されます.w1 と w2 は独立した変数として働き,w1 のデータを変更しても w2 のデータは影響を受けません(逆も同様).上の例で示したような int 型を要素とする場合は特に問題ありませんが,クラスのオブジェクトを要素とし,かつ,クラス内で new 演算子を使用している場合は,注意が必要です.浅いコピーに基づいているため,各要素に記憶されているオブジェクトデータはコピーされますが,オブジェクト内にあるアドレスデータはそのアドレスがコピーされるだけで,アドレスが指している先のデータはコピーされません.従って,コピー元とコピー先で同じデータを指すことになります.
- C++ 標準ライブラリ内には,vector クラス意外にも,複合データを扱う多くのクラスが存在しますが,次節のプログラム例においては,map クラスに関する例についても述べています.
- Java
- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.例えば,
int u1[] = {1, 2, 3}, u2[] = {1, 2, 3}, u3[], u4[]; u3 = u1; u4 = u1.clone(); //int u1[] = new int [3]; // 初期設定を行わない場合- の 1 行目のように宣言すれば,u1,u2 という,1,2,3 で初期設定された 3 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,u1[0],u1[1],u1[2],u2[0],u2[1],u2[2] のようにして参照できます.また,配列変数であることだけを宣言した変数 u3,u4 を定義しています.
- また,2 行目において,u1 を u3 に代入しています.しかし,この代入は,整数型の場合のような代入ではありません.つまり,u1 の領域及びそこに記憶されている要素をすべてコピーし,u3 に代入しているわけではありません.ここでは,u1,u2,u3 をポインタとしてとらえた方が理解しやすいと思います.つまり,2 行目の代入によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているという意味です.実際,u1 の値を変更すれば,u3 の値も変化します(逆も同様).このことを概念的に示せば以下のようになります.しかし,3 行目のように,clone メソッドを使用すると,u1 と u4 は異なる配列になり,u4 の値を変更しても,u1 には影響を与えません(逆も同様).
- 多次元の配列を扱うことも可能です(行毎に列数を変えることも可能).例えば,
int v1[][] = {{10, 20, 30}, {40, 50, 60}}; int v2[][] = {{10, 20, 30}, {40, 50, 60}}; int v3[][] = v1; // int v3[][] = v1.clone(); //double v1[][] = new double [2][3]; // 初期設定を行わない場合 //double v1[][] = new double [2][]; // この行以下の 3 行のような形でも可能 //for (int i1 = 0; i1 < 2; i1++) // v1[i1] = new double [3]; // 行毎に列数を変えることも可能- の 1,2 行目の記述によって 2 行 3 列の表に対応する配列 v1,v2 が生成されます.v3 に対しては,2 次元配列であることだけを宣言していますが,3 行目の記述によって,v3 も,v1 と同じ 2 行 3 列の配列になります.そのイメージは,new 演算子を使用した C++ の場合と同じく,以下のようになります.3 行目のコメントにあるように,clone を使用しても,浅いコピーであるため,v3 の値を変更すれば,v1 の対応する値も変化します(逆も同様).
- 例えば,
int vp1[] = v1[0]; // v1,v3 の 1 行目 int vp2[] = v1[1]; // v1,v3 の 2 行目 int vp3[] = v1[1].clone();
- のように,各行を 3 つの要素からなる 1 次元配列として扱うことも可能です.勿論,vp1 と v1[0] は同じ場所を指していますので,例えば,vp1[1] の値を変更すれば,v1[0][1] の値も変化します(逆も同様).また,1 次元配列の場合と同様,clone メソッドを使用すれば,各行と独立した配列を定義することも可能です( 3 行目).しかし,すべてのデータが連続した領域に確保されるとは限らないため,C++ のように,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません.
- さらに,以下に示すような方法を使用すれば,各行毎の初期設定も行うことが可能です.
int x1[] = {10, 20, 30}; int x2[] = {40, 50, 60}; int v1[][] = {x1, x2};- 今まで述べた方法では,プログラムの実行時に,要素の追加,削除等を行うことができません.しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,java.util パッケージ 内の ArrayList クラスなどを使用することによって実現できます.ArrayList クラスにおいては,実行時に,必要な数だけのデータを追加,削除,変更等が可能です.C++ における vector クラスを使用した場合と似ていますが,配列の場合と同様,
ArrayList <Integer> w1, w2; ・・・ w2 = w1;
- の代入文によってアドレスが記憶されるため,w1 の要素の値を変更すると w2 に対する値も変化します(逆も同様).java.util パッケージ には,ArrayList クラス意外にも,複合データを扱う多くのクラスが存在しますが,次節のプログラム例においては,連想配列に相当する TreeMap クラスに関する例についても述べています.
- JavaScript
- 配列は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.例えば,
let x = new Array(1, 2.3, "abc"); //let x = new Array(); // 要素数は未定,初期設定を行わない //let x = new Array(100); // 要素数が100の配列,初期設定を行わない
- のように宣言すれば,3 つのデータを記憶できる領域が確保され,各要素に記憶される値が 1,2.3,"abc" で初期設定されます.また,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.この例に示すように,各要素は,必ずしも,同じデータ型である必要はありません.しかし,間違いの元になる可能性がありますので,配列は,同じデータ型だけで構成するようにした方が良いと思います.また,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 例えば,
let u1 = new Array(1, "abc", 2); let u2 = new Array(1, "abc", 2); let u3 = u1; u3[1] = 4;
- の最初の 2 行では,同じ値で初期設定された 2 つの配列 u1,u2 を定義し,次の行において u1 を u3 に代入しています.しかし,この代入は,整数型の場合のような代入ではありません.つまり,u1 の領域及びそこに記憶されている要素をすべてコピーし,u3 に代入しているわけではありません.ここでは,u1,u2,u3 をポインタとしてとらえた方が理解しやすいと思います.つまり,2 行目の代入によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているという意味です.実際,u1 の値を変更すれば,u3 の値も変化します(逆も同様).このことを概念的に示せば以下のようになります.
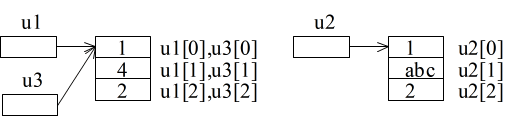
- 多次元の配列を扱うことも可能です(行毎に列数を変えることも可能).例えば,
let v1 = new Array(2); v1[0] = new Array(10, 20, 30); v1[1] = new Array(40, 50, 60); let v2 = new Array(2); v2[0] = new Array(10, 20, 30); v2[1] = new Array(40, 50, 60); let v3 = v1;
- のように,配列の要素を,さらに配列として定義すれば,2 次元の配列を定義できます.この例では,2 行 3 列の配列になります.7 行目の記述によって,v3 も,v1 と同じ 2 行 3 列の配列になります.そのイメージは,new 演算子を使用した C++ の場合と同じく,以下のようになります.
- また,
let vp1 = v1[0]; // v1,v3 の 1 行目 let vp2 = v1[1]; // v1,v3 の 2 行目
- のように,各行を 1 次元配列として扱うことも可能です.勿論,vp1 と v1[0] は同じ場所を指していますので,例えば,vp1[1] の値を変更すれば,v1[0][1] の値も変化します(逆も同様).しかし,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません.
- PHP
- 配列は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.例えば,
$x = array(1, 2.3, "abc"); //$x = array(); // 要素数は未定,初期設定を行わない
- のように宣言すれば,3 つのデータを記憶できる領域が確保され,各要素に記憶される値が 1,2.3,"abc" で初期設定されます.また,変数名と添え字を利用して,$x[0],$x[1],$x[2] のようにして参照できます.この例に示すように,各要素は,必ずしも,同じデータ型である必要はありません.しかし,間違いの元になる可能性がありますので,配列は,同じデータ型だけで構成するようにした方が良いと思います.また,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 例えば,
$u1 = array(1, "abc", 2); $u2 = $u1; $u3 = &$u1;
- の最初の行では,初期設定された配列 $u1 を定義し,次の行において $u1 を $u2 に代入しています.この代入によって,整数型の場合と同じように,$u1 のすべてのデータが $u2 にコピーされ新しい配列が作成されます.下に述べる 2 次元配列の場合も同様ですが,この点は,C++ における new 演算子を使用する場合,Java,JavaScript,Ruby,Python,C#,VB などと異なることに注意してください.ただし,3 行目のように,参照を利用すれば,$u3 と $u1 は同じ配列になります.なお,コピーは,浅いコピーに準じた方法で行われますが,詳細については,次節のプログラム例を見てください.
- 多次元の配列を扱うことも可能です(行毎に列数を変えることも可能).例えば,
$v1 = array(2); $v1[0] = array(10, 20, 30); $v1[1] = array(40, 50, 60); $v2 = $v1; $v3 = &$v1;
- における 1 行目~ 3 行目のように,配列の要素を,さらに配列として定義すれば,2 次元の配列を定義できます.この例では,2 行 3 列の配列になります.4 行目においては,$v1 を $v2 に代入していますが,1 次元配列の場合と同様,$v2 は,$v1 のすべての要素をコピーして,全く新しい配列として生成されます.ただし,5 行目のように,参照を利用すれば,$v3 と $v1 は同じ配列になります.
- また,
$v4 = $v1[0]; // $v4 = &$v1[0];
- のように,2 次元配列 $v1 の各行を 1 次元配列として扱うことも可能です.この場合も,1 次元配列の場合と同様,$v4 は,$v1 の 1 行目のすべての値をコピーした全く新しい配列となります.ただし,コメントに示すように,参照を利用すれば,$v4 と $v1[0] は同じ配列になります.
- Ruby
- 配列は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.Ruby においては Array クラスのインスタンスとして定義され,例えば,
x = Array[1, 2.3, "abc"]; # x = [1, 2.3, "abc"]; でも可 #x = Array.new(); # 初期設定をしない場合 #x = Array.new(3); # サイズを指定しても良い
- のように宣言すれば,3 つのデータを記憶できる領域が確保され,各要素に記憶される値が 1,2.3,"abc" で初期設定されます.また,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.この例に示すように,各要素は,必ずしも,同じデータ型である必要はありません.しかし,間違いの元になる可能性がありますので,配列は,同じデータ型だけで構成するようにした方が良いと思います.また,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 例えば,
u1 = Array[1, "abc", 2]; u2 = Array[1, "abc", 2]; u3 = u1; u4 = u1.clone(); u3[1] = 10; u4[0] = 20;
- の最初の 2 行では,同じ値で初期設定された 2 つの配列 u1,u2 を定義し,次の行において u1 を u3 に代入しています.しかし,この代入は,整数型の場合のような代入ではありません.つまり,u1 の領域及びそこに記憶されている要素をすべてコピーし,u3 に代入しているわけではありません.ここでは,u1,u2,u3 をポインタとしてとらえた方が理解しやすいと思います.つまり,2 行目の代入によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているという意味です.実際,u1 の値を変更すれば,u3 の値も変化します(逆も同様).このことを概念的に示せば以下のようになります.しかし,4 行目のように clone を使用すると,u4 は u1 とは異なる配列となります.
- 多次元の配列を扱うことも可能です(行毎に列数を変えることも可能).例えば,
v1 = Array[[10, 20, 30], [40, 50, 60]]; v2 = Array[[10, 20, 30], [40, 50, 60]]; v3 = v1; v4 = v1.clone(); #v1 = Array.new(); # 初期設定をしない場合 #for i1 in (0...2) # v1[i1] = Array.new(); # v1[i1] = Array[1, 2, 3]; # 行毎の初期設定も可
- のように,配列の要素を,さらに配列として定義すれば,2 次元の配列を定義できます.この例では,2 行 3 列の配列になります.3 行目の記述によって,v3 も,v1 と同じ 2 行 3 列の配列になります.そのイメージは,new 演算子を使用した C++ の場合と同じく,以下のようになります.4 行目のように,clone を使用しても,浅いコピーであるため,v4 の値を変更すれば,v1 の値も変化します(逆も同様).
- また,
v4 = v1[0]; // v1,v3 の 1 行目 v5 = v1[0].clone();
- の 1 行目のように,各行を 1 次元配列として扱うことも可能です.勿論,v4 と v1[0] は同じ場所を指していますので,例えば,v4[1] の値を変更すれば,v1[0][1] の値も変化します(逆も同様).2 行目のように,clone を使用すれば,v5 は,v1 の 1 行目とは異なる 1 次元配列になります.しかし,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません.
- Python
- 配列は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.例えば,
x = array("i", [1, 2, 3]) # x = array("i") 初期設定を行わない場合 y = [1, "abc", 2]- の 1 行目のように宣言すれば,1,2,3 で初期設定された 3 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.array は,"i" の部分で指定された同じデータ型の数値データだけを取り扱うことができますが,array とほぼ同じ機能を持った list では,2 行目に示すように,異なるデータ型を要素として持つことができます.また,いずれの場合においても,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 例えば,
u1 = array("i", [1, 2, 3]) u2 = array("i", [1, 2, 3]) u3 = u1 u4 = copy.copy(u1)- の 1 行目,2 行目においては,同じ値で初期設定された 2 つの配列 u1,u2 を定義し,3 行目では,u1 の値を u3 に代入(記憶)しています.しかし,この代入は,整数型の場合のような代入ではありません.つまり,u1 の領域及びそこに記憶されている要素をすべてコピーし,u3 に代入しているわけではありません.ここでは,u1,u2,u3 をポインタとしてとらえた方が理解しやすいと思います.つまり,3 行目の代入によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているという意味です.実際,u1 の値を変更すれば,u3 の値も変化します(逆も同様).
- 4 行目においては,u1 の浅いコピーを u4 に代入しています.浅いコピーによって,アドレスだけでなく,アドレスが指している値(配列の各要素)もコピーされ,u4 に記憶されます.つまり,u1 と u4 は,異なる配列となり,片方の配列における値の変更は,他の配列に全く影響を与えません.例えば,
u3[1] = 4 u4[2] = 5
- のような変更を行った結果を概念的に示せば以下のようになります( u2 に関する部分は除く).

- 多次元の配列を扱うことも可能です(行毎に列数を変えることも可能).例えば,
v1 = [array("i", [10, 20, 30]), array("i", [40, 50, 60])] v2 = [array("i", [10, 20, 30]), array("i", [40, 50, 60])] v3 = v1 v4 = copy.copy(v1) v5 = copy.deepcopy(v1)- の 1 行目,2 行目のように記述すれば,2 行 3 列の表に対応する配列を定義できます.3 行目においては,v1 の値のコピーを v3 に代入,4 行目においては,v1 の浅いコピーを v4 に代入,また,5 行目においては,v1 の深いコピーを v5 に代入しています.ここで,
v1[0][1] = 70 v3[0][2] = 100 v4[1][0] = 200 v5[1][1] = 300 v6 = v1[0] # v1,v3,v4 の 1 行目 v6[0] = 400
- のようにして,要素の値を変更してみます.v1 や v3 を変更した場合の結果は,1 次元配列と同様,v1 と v3 が同じように変化します.しかし,浅いコピーを行った v4 を介した変更に対しても,v1 や v3 が影響を受けます.2 次元配列は,v1 がポインタ変数 v1[0],v1[1] からなる配列の先頭を指し,ポインタ変数 v1[0],v1[1] が,各々,各行のデータが入っている配列の先頭を指しているとみなせます(下に示す図を参照).浅いコピーが,v1 の指す領域だけをコピー(この例の場合は,v1[0],v1[1] を v4[0],v4[1] にコピー)して,v4 に記憶しているため,このようなことが起こります.v5 に対して行った深いコピーにおいては,v1[0],v1[1] が指すデータ領域もコピーされて,v5 に記憶されます.そのため,v5 は,全く別の配列となり,その要素の値の変更は他の配列に影響を与えません.
- 5 行目~ 6 行目に示すように,各行を 1 次元配列として扱うことも可能です.勿論,v6 と v1[0] は同じ場所を指していますので,例えば,v6[1] の値を変更すれば,v1[0][1] の値も変化します(逆も同様).しかし,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません.

- NumPy を利用して,配列を扱うことも可能です.array や list との大きな違いは,多次元配列であっても,データが連続した領域に記憶されることです.そのため,多次元配列に対して浅いコピーを利用しても,全く別の配列として取り扱われます.なお,プログラムの実行時に,要素の追加,削除等を行うことは多少面倒です.
- C#
- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.例えば,
int[] u1 = {1, 2, 3}, u2 = {1, 2, 3}, u3; u3 = u1; //int[] u1 = new int [] {1, 2, 3}; //int[] u1 = new[] {1, 2, 3}; //int[] u1 = new int [3]; // 初期設定を行わない場合- の 1 行目のように宣言すれば,u1,u2 という,1,2,3 で初期設定された 3 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,u1[0],u1[1],u1[2],u2[0],u2[1],u2[2] のようにして参照できます.また,u3 に対しては,配列変数であることだけを宣言した変数 u3 を定義しています.
- また,2 行目において,u1 を u3 に代入しています.しかし,この代入は,整数型の場合のような代入ではありません.つまり,u1 の領域及びそこに記憶されている要素をすべてコピーし,u3 に代入しているわけではありません.ここでは,u1,u2,u3 をポインタとしてとらえた方が理解しやすいと思います.つまり,2 行目の代入によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているという意味です.実際,u1 の値を変更すれば,u3 の値も変化します(逆も同様).このことを概念的に示せば以下のようになります.
- 多次元の配列を扱うことも可能です(行毎に列数を変えることも可能).例えば,
01 //int[][] v1 = new int [2][3]; // この記述は許されない 02 int[][] v1 = new int[][] { 03 new int[] {10, 20, 30}, 04 new int[] {40, 50, 60} 05 }; 06 int[][] v2 = new int [2][]; // この方法でも良い 07 v2[0] = new int[] {10, 20, 30}; 08 v2[1] = new int[] {40, 50, 60}; 09 //int[][] v1 = new int [2][]; // 以下の 3 行でも良い(初期設定を行わない場合) 10 //for (int i1 = 0; i1 < 2; i1++) { 11 // v1[i1] = new int [3]; 12 int[][] v3 = v1;- の 02 行目~ 08 行目の記述によって 2 行 3 列の表に対応する配列 v1,v2 が生成されます.v3 に対しては,12 行目の記述によって,v3 も,v1 と同じ 2 行 3 列の配列になります.そのイメージは,new 演算子を使用した C++ の場合と同じく,以下のようになります.
- 例えば,
int vp1[] = v1[0]; // v1,v3 の 1 行目 int vp2[] = v1[1]; // v1,v3 の 2 行目
- のように,各行を 3 つの要素からなる 1 次元配列として扱うことも可能です.勿論,vp1 と v1[0] は同じ場所を指していますので,例えば,vp1[1] の値を変更すれば,v1[0][1] の値も変化します(逆も同様).しかし,すべてのデータが連続した領域に確保されるとは限らないため,C++ のように,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません.
- C# には,多次元配列を定義するあと一つの方法があります.例えば,
int[,] v1 = {{10, 20, 30}, {40, 50, 60}}; //int[,] v1 = new int[,] {{10, 20, 30}, {40, 50, 60}}; //int[,] v1 = new[,] {{10, 20, 30}, {40, 50, 60}}; //int[,] v1 = new int [2,3]; // 初期設定を行わない- のような形で,2 次元配列 v1 の定義を行うことができます.この配列の i 行 j 列要素の参照は,v1[i,j] のようにして行います.参照方法以外,使用方法として,先に述べた配列と大きな差はありませんが,このようにして定義した場合,C/C++ の配列のように,連続した記憶領域が確保されるため,より高速な演算が期待できます.ただし,行毎に列数を変えたり,各行を 1 次元配列として扱うような処理は不可能です.
- 今まで述べた方法では,プログラムの実行時に,要素の追加,削除等を行うことができません.しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,List クラスなどを使用することによって実現できます.List クラスにおいては,実行時に,必要な数だけのデータを追加,削除,変更等が可能です.C++ における vector クラスを使用した場合と似ていますが,配列の場合と同様,
List <int> w1, w2; ・・・ w2 = w1;
- の代入文によってアドレスが記憶されるため,w1 の要素の値を変更すると w2 に対する値も変化します(逆も同様).次節のプログラム例においては,連想配列に相当する Dictionary クラスに関する例についても述べています.
- VB
- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.例えば,
Dim u1() As Integer = {1, 2, 3} Dim u2() As Integer = {1, 2, 3} Dim u3() As Integer = u1; 'Dim u1(3) As Integer = {1, 2, 3} ' 配列サイズを指定した初期設定は不可能 'Dim u1(n) As Integer ' 初期設定なし,n は添え字の最大値- の 1,2 行目のように宣言すれば,u1,u2 という,1,2,3 で初期設定された 3 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,u1(0),u1(1),u1(2),u2(0),u2(1),u2(2) のようにして参照できます.なお,5 行目のような宣言を行ったとき,他の言語のように,n は配列サイズではなく,添え字の最大値を表しています.従って,要素は,u1(0),u1(1),・・・,u1(n) となります.
- また,3 行目において,配列変数であることだけを宣言した変数 u3 に u1 を代入しています.しかし,この代入は,整数型の場合のような代入ではありません.つまり,u1 の領域及びそこに記憶されている要素をすべてコピーし,u3 に代入しているわけではありません.ここでは,u1,u2,u3 をポインタとしてとらえた方が理解しやすいと思います.つまり,3 行目の代入によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているという意味です.実際,u1 の値を変更すれば,u3 の値も変化します(逆も同様).このことを概念的に示せば以下のようになります.

- 多次元の配列を扱うことも可能です(行毎に列数を変えることは不可能).例えば,
Dim v1(,) As Integer = {{10, 20, 30}, {40, 50, 60}} Dim v2(,) As Integer = {{10, 20, 30}, {40, 50, 60}} Dim v3(,) As Integer = v1 'Dim v1(,) As Integer = New Integer(,) {{10, 20, 30}, {40, 50, 60}} でも可 'Dim v1(2,3) As Integer = {{10, 20, 30}, {40, 50, 60}} 要素数指定の初期設定は不可 'Dim v1(2,3) As Integer 初期設定は行わない場合- の 1,2 行目の記述によって 2 行 3 列の表に対応する配列 v1,v2 が生成されます.i 行 j 列要素の参照は,v1(i,j) のようにして行います.3 行目において,配列変数であることだけを宣言した変数 v3 に v1 を代入しています.その結果,v3 も,v1 と同じ 2 行 3 列の配列になります.しかし,各行を 3 つの要素からなる 1 次元配列として扱うことはできません.
- 今まで述べた方法では,プログラムの実行時に,要素の追加,削除等を行うことができません.しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,List クラスなどを使用することによって実現できます.List クラスにおいては,実行時に,必要な数だけのデータを追加,削除,変更等が可能です.C++ における vector クラスを使用した場合と似ていますが,配列の場合と同様,
Dim w1 As New List(Of Integer) Dim w2 As New List(Of Integer) ・・・ w2 = w1;
- の代入文によってアドレスが記憶されるため,w1 の要素の値を変更すると w2 に対する値も変化します(逆も同様).
- C++
- 平均点以上の人数( 1 次元配列)
01 #include <stdio.h> 02 03 int main() 04 { 05 int m1; // 人数 06 printf("人数は? "); 07 scanf("%d", &m1); 08 int a1[m1]; // int a1[100]; の方が好ましい 09 // int a1[m1] = {1, 2, 3}; のような初期設定不可 10 // int b1[m1]; 11 // b1 = a1; // このような代入は許されない 12 double mean1 = 0.0; 13 for (int i1 = 0; i1 < m1; i1++) { 14 printf(" %d 番目の人の点数は? ", i1+1); 15 scanf("%d", &a1[i1]); 16 mean1 += a1[i1]; 17 } 18 mean1 /= (double)m1; 19 int n1 = 0; 20 for (int i1 = 0; i1 < m1; i1++) { 21 if (a1[i1] >= mean1) 22 n1++; 23 } 24 printf(" 平均点( %f )以上は %d 人\n", mean1, n1); 25 26 return 0; 27 }- 1 次元配列を利用したプログラムです.人数と各人の点数を入力し,平均点以上の人数を求めています.08 行目のように,配列の大きさとして変数を使用することは可能ですが,09 行目のような初期設定はできません.先に述べましたように,配列の大きさとして変数を使用すると,コンパイラの種類やバージョンによってはエラーになってしまうため,コメントにあるように,定数を使用した方が良いと思います.実際,このままでは,VC++ においては,エラーになってしまいます.コメントにあるような記述を行った場合,100 人を超える人数を扱うことができませんので,m1 の値が 100 より大きい場合は,エラーメッセージを出力するような処理が必要です.
- 初期設定を行うためには,
int a1[3] = {1, 2, 3}; int a1[] = {1, 2, 3}; // 3 は,省略可能- のいずれかの方法で行う必要があります.また,配列の大きさを定数で宣言したとしても,11 行目のような代入文は許されません.繰り返し文を使用して,a1 の各要素を b1 の各要素に代入していかざるを得ません.もちろん,a1 と b1 は全く別の配列となります.
- 12 行目~ 18 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.平均値は,小数点以下まで求めたいため,キャスト演算子 (double) を使用して,int 型の変数 m1 を double 型に変換しています( 18 行目).( int / int ) は,結果も int になり,小数点以下が切り捨てられますが,( double / int ) や ( int / double ) の場合は,int の部分が double に変換され,結果も double になるため,キャスティングを必ずしも必要としません.
- 20 行目~ 23 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.
- 12 行目~ 18 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.平均値は,小数点以下まで求めたいため,キャスト演算子 (double) を使用して,int 型の変数 m1 を double 型に変換しています( 18 行目).( int / int ) は,結果も int になり,小数点以下が切り捨てられますが,( double / int ) や ( int / double ) の場合は,int の部分が double に変換され,結果も double になるため,キャスティングを必ずしも必要としません.
- 平均点以上のクラス数( 2 次元配列)
01 #include <stdio.h> 02 03 int main() 04 { 05 int m2; // クラス数 06 printf("クラス数は? "); 07 scanf("%d", &m2); 08 double mean2 = 0.0; // 全体の平均 09 double c_mean2[m2]; // クラス毎の平均,double c_mean2[10]; の方が好ましい 10 int s_num2 = 0; // 全体の人数 11 int a2[m2][50]; // int a2[5][50]; の方が好ましい 12 // int a2[m2][2] = {{1, 2}, {3, 4}, {5, 6}}; のような初期設定不可 13 // int b2[m2][50]; 14 // b2 = a2; // このような代入は許されない 15 for (int i1 = 0; i1 < m2; i1++) { 16 int n_m2; // クラス内の人数 17 printf(" クラス %d の人数は? ", i1+1); 18 scanf("%d", &n_m2); 19 c_mean2[i1] = 0.0; 20 for (int i2 = 0; i2 < n_m2; i2++) { 21 printf(" クラス %d の %d 番目の人の点数は? ", i1+1, i2+1); 22 scanf("%d", &a2[i1][i2]); 23 c_mean2[i1] += a2[i1][i2]; 24 } 25 mean2 += c_mean2[i1]; 26 s_num2 += n_m2; 27 c_mean2[i1] /= (double)n_m2; // クラスの平均 28 } 29 mean2 /= (double)s_num2; // 全体の平均 30 int n2 = 0; 31 for (int i1 = 0; i1 < m2; i1++) { 32 if (c_mean2[i1] >= mean2) 33 n2++; 34 } 35 printf(" 平均点( %f )以上のクラスは %d \n", mean2, n2); 36 37 return 0; 38 }- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数を入力し,全体の平均点以上の平均点をとったクラス数を求めています.11 行目のように,配列の大きさとして変数を使用することは可能ですが,12 行目のような初期設定はできません.09 行目,11 行目においては,変数 m2 を使用して配列の大きさを決めていますが,1 次元配列の場合と同様,コメントにあるように定数を使用した方が良いと思います.その場合は,クラスの数が 5 を超えた場合やクラスの人数が 50 を超えた場合に対して,エラーメッセージを出力するような処理が必要です.
- 初期設定を行うためには,
int a2[3][2] = {{1, 2}, {3, 4}, {5, 6}}; int a2[][2] = {{1, 2}, {3, 4}, {5, 6}}; // 3 は,省略可能- のいずれかの方法で行う必要があります.配列の行がクラスに対応し,列にそのクラス内の各人の点数が入ります.クラス毎に人数が異なりますが,11 行目では,最大のクラス内人数以上の値(この例では 50 )で,型宣言を行っておく必要があります.2 次元配列であっても,連続した領域に確保されますので,
int *x = &(a2[0][0]);
- のような宣言を行えば,配列 a2 を,(m1 × 5) 個の要素からなる 1 次元配列 x として処理することも可能です.もちろん,領域の最初ではなく,その途中のアドレスを指定することも可能です.
- また,1 次元配列と同様,配列の大きさを定数で宣言したとしても,14 行目のような代入文は許されません.2 重の繰り返し文を使用して,a2 の各要素を b2 の各要素に代入していかざるを得ません.もちろん,a2 と b2 は全く別の配列となります.
- 15 行目の for 文によって,15 行目~ 28 行目がクラスの数だけ繰り返され,29 行目において,全体の平均点を求めています.内側のループ 20 行目~ 24 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a2[i1][i2] に保存し,27 行目において,対応するクラスの平均点を計算しています.27 行目,29 行目において,変数 n_m2,s_num2 を double に型変換しているのは,1 次元配列を使用したプログラム内で説明したとおりです.
- また,1 次元配列と同様,配列の大きさを定数で宣言したとしても,14 行目のような代入文は許されません.2 重の繰り返し文を使用して,a2 の各要素を b2 の各要素に代入していかざるを得ません.もちろん,a2 と b2 は全く別の配列となります.
- 平均点以上の人数( new 演算子による 1 次元配列)
01 #include <stdio.h> 02 03 int main() 04 { 05 int m3; // 人数 06 printf("人数は? "); 07 scanf("%d", &m3); 08 int *a3 = new int [m3]; // 初期化: int *a3 = new int [3] {1, 2, 3}; 09 // int *b3; 10 // b3 = a3; a3 と b3 は同じ配列(a3 を変更すれば b3 も変化) 11 double mean3 = 0.0; 12 for (int i1 = 0; i1 < m3; i1++) { 13 printf(" %d 番目の人の点数は? ", i1+1); 14 scanf("%d", &a3[i1]); 15 mean3 += a3[i1]; 16 } 17 mean3 /= (double)m3; 18 int n3 = 0; 19 for (int i1 = 0; i1 < m3; i1++) { 20 if (a3[i1] >= mean3) 21 n3++; 22 } 23 printf(" 平均点( %f )以上は %d 人\n", mean3, n3); 24 delete [] a3; 25 26 return 0; 27 }- 1 次元配列を使用したプログラムを,new 演算子による 1 次元配列を使用して書き直したものです.プログラムとしてはほとんど同じですが,new 演算子を使用するといくつかの点で異なってきます.まず,初期設定は,08 行目のコメントに記述したように,初期化子リストを使用した方法だけが可能です.また,new 演算子は,領域を確保し,そのアドレスを返す演算子ですので,a3 はアドレスを記憶している変数になります.従って,09 行目~ 10 行目のような代入が可能になります.その結果,a3 と b3 は同じ配列になり,a3 を変更すれば b3 も変化することになります(逆も同様).
- さらに,new 演算子によって確保した領域は,24 行目に示すように,delete 演算子によって解放してやる必要があります.しかし,C++ にはガーベッジコレクション機能がありませんので,new と delete を頻繁に繰り返すと,メモリ不足の状況に落ちる可能性がありますので注意して下さい.
- 平均点以上のクラス数( new 演算子による 2 次元配列)
01 #include <stdio.h> 02 int main() 03 { 04 int m4; // クラス数 05 printf("クラス数は? "); 06 scanf("%d", &m4); 07 double mean4 = 0.0; // 全体の平均 08 double *c_mean4 = new double [m4]; // クラス毎の平均 09 int s_num4 = 0; // 全体の人数 10 int **a4 = new int *[m4]; 11 for (int i1 = 0; i1 < m4; i1++) { 12 int n_m4; // クラス内の人数 13 printf(" クラス %d の人数は? ", i1+1); 14 scanf("%d", &n_m4); 15 a4[i1] = new int [n_m4]; 16 c_mean4[i1] = 0.0; 17 for (int i2 = 0; i2 < n_m4; i2++) { 18 printf(" クラス %d の %d 番目の人の点数は? ", i1+1, i2+1); 19 scanf("%d", &a4[i1][i2]); 20 c_mean4[i1] += a4[i1][i2]; 21 } 22 mean4 += c_mean4[i1]; 23 c_mean4[i1] /= (double)n_m4; 24 s_num4 += n_m4; 25 } 26 mean4 /= (double)s_num4; 27 int n4 = 0; 28 for (int i1 = 0; i1 < m4; i1++) { 29 if (c_mean4[i1] >= mean4) 30 n4++; 31 } 32 printf(" 平均点( %f )以上のクラスは %d \n", mean4, n4); 33 // int **b4; 34 // b4 = a4; a4 と b4 は同じ配列(a4 を変更すれば b4 も変化) 35 // int *c4; 36 // c4 = a4[1]; c4 は,a4 の 2 行目と同じ 1 次元配列 37 // (a4 の 2 行目を変更すれば c4 も変化) 38 delete [] c_mean4; 39 for (int i1 = 0; i1 < m4; i1++) 40 delete [] a4[i1]; 41 delete [] a4; 42 43 return 0; 44 }- 2 次元配列を使用したプログラムを,new 演算子による 2 次元配列を使用して書き直したものです.プログラムとしてはほとんど同じですが,new 演算子を使用すると,初期設定(初期化子リストを利用して可能)の方法以外に,いくつかの点で異なってきます.2 次元配列の生成のために,まず,10 行目において m4 個 のint 型のポインタを記憶する領域を確保し,そのアドレスを a4 に記憶しています.次に,クラスの人数 n_m4 を入力した後,n_m4 個の int 型データを記憶する領域を確保し,そのアドレスを a4[i1] に記憶しています( 15 行目).このように,各行毎に列の数が異なる 2 次元配列を作成することができます.
- a4 はポインタですので,33 行目~ 34 行目のような代入が可能になり,その結果,a4 と b4 は同じ配列になり,a4 を変更すれば b4 も変化することになります(逆も同様).また,35 行目~ 36 行目のような代入を行うことによって,2 次元配列 a4 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.c4 は,a4 の 2 行目と同じ 1 次元配列になり,a4 の 2 行目を変更すれば c4 も変化します(逆も同様).しかし,a4 のデータ領域は必ずしも連続していませんので,通常の配列のように,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- new 演算子を使用した 1 次元配列の場合と同様,new 演算子によって確保した領域は,delete 演算子によって解放してやる必要があります.ただし,39 行目~ 41 行目に示すように,2 次元配列の場合は注意してください.まず,ポインタ配列の各要素が指しているデータ領域を開放します( 39 行目~ 40 行目).次に,a4 が指しているポインタ配列を解放します( 41 行目).これを逆に行わないでください.
- a4 はポインタですので,33 行目~ 34 行目のような代入が可能になり,その結果,a4 と b4 は同じ配列になり,a4 を変更すれば b4 も変化することになります(逆も同様).また,35 行目~ 36 行目のような代入を行うことによって,2 次元配列 a4 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.c4 は,a4 の 2 行目と同じ 1 次元配列になり,a4 の 2 行目を変更すれば c4 も変化します(逆も同様).しかし,a4 のデータ領域は必ずしも連続していませんので,通常の配列のように,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- ファイル入出力( vector クラスの利用)
01 #include <stdio.h> 02 #include <vector> 03 04 using namespace std; 05 06 int main() 07 { 08 printf("ファイル入出力(vector クラス)\n"); 09 FILE *in = fopen("data.txt","r"); 10 FILE *out = fopen("out.txt","w"); // fopen(..., "a") は追加 11 double mean5 = 0.0; 12 int x, m5 = 0; 13 vector<int> a5; 14 while (EOF != fscanf(in, "%d", &x)) { 15 a5.push_back(x); 16 mean5 += x; 17 m5++; 18 fprintf(out, "%d %d\n", m5, x); 19 } 20 fclose(in); 21 fclose(out); 22 mean5 /= (double)m5; 23 int n5 = 0; 24 for (int i1 = 0; i1 < m5; i1++) { 25 if (a5[i1] >= mean5) 26 n5++; 27 } 28 printf(" 平均点( %f )以上は %d 人\n", mean5, n5); 29 // vector<int> b5; 30 // b5 = a5; a5 と b5 は,要素の値は同じでも別の配列 31 32 return 0; 33 }- 今までの方法においては,データを入力する前に配列のサイズを決めておく必要がありました.例えば,ファイルにいくつかのデータが入っており,その数は未定だったとします.もちろん,今までの方法においても,十分大きなサイズの配列を準備するなど,解決方法がないわけではありませんが,データを入力するたびに,配列サイズが変化してくれればより使いやすいかもしれません.ここでは,C++ 標準ライブラリ内の vector クラスを使用して,データ数が未知であるファイル内のデータを読み込み,平均値を求め,平均点以上のデータ数を出力しています.なお,ファイル data.txt には,1 行に 1 つずつのデータが入っているものとします.また,特に必要性はありませんが,データ番号と読み込んだデータをファイル out.txt に書き込んでいます.
- 09 行目において,ファイル data.txt を読み取り用に,また,10 行目において,ファイル out.txt を書き込み用に開いています.14 行目において,ファイル内データを 1 つずつ変数 x に読み込み,18 行目において,データ番号と読み込んだデータをファイルに出力し,20,21 行目において,各ファイルを閉じています.14 行目は,データを読み込み,それが EOF ( End of File,ファイルの終わり)で無い限り,while 文による繰り返しを継続するということを意味しています.
- 13 行目において,int 型の要素からなる vector クラスのオブジェクト(拡張された配列と思ってください) a5 を定義しています.この時点では,a5 の要素数は 0 です.vector では,要素の追加,削除,変更を容易に行えます.15 行目においては,入力されたデータを a5 に追加しています.17 行目において,入力されたデータを数えていますが,このようなことを行わなくても,「 a5.size() 」という記述によって,a5 に記憶されている要素数を知ることができます.
- また,29 行目~ 30 行目のような処理も可能ですが,vector の場合,代入によってすべての要素がコピーされるため,a5 と b5 は,要素の値は同じでも全く別の vector クラスのオブジェクトとなります.
- 09 行目において,ファイル data.txt を読み取り用に,また,10 行目において,ファイル out.txt を書き込み用に開いています.14 行目において,ファイル内データを 1 つずつ変数 x に読み込み,18 行目において,データ番号と読み込んだデータをファイルに出力し,20,21 行目において,各ファイルを閉じています.14 行目は,データを読み込み,それが EOF ( End of File,ファイルの終わり)で無い限り,while 文による繰り返しを継続するということを意味しています.
- map クラス
01 #include <stdio.h> 02 #include <iostream> 03 #include <map> 04 05 using namespace std; 06 07 int main() 08 { 09 printf("map クラス\n"); 10 map<string, int> a6; 11 a6.insert(pair<string, int>("suzuki", 40)); // a6["suzuki"] = 40; でも可 12 a6.insert(pair<string, int>("sato", 60)); // a6["sato"] = 60; でも可 13 a6.insert(pair<string, int>("yamada", 70)); // a6["yamada"] = 70; でも可 // 以下のような形で初期設定も OK // map<string, int> a6 {{"suzuki", 40}, {"sato", 60}, {"yamada", 70}}; 14 map<string, int>::iterator it = a6.find("suzuki"); 15 printf(" suzuki さんの得点:%d\n", it->second); 16 // 上の 2 行の代わりに下に示す 1 行でも可 17 // printf(" suzuki さんの得点:%d\n", a6["suzuki"]); 18 // map<string, int> b6; 19 // b6 = a6; a6 と b6 は,要素の値は同じでも別の配列 20 21 return 0; 22 }- C++ 標準ライブラリ内には,上で述べた vector クラス以外に,いくつかのクラスが定義されています.JavaScript や PHP の連想配列,Java の TreeMap や HashMap,Python の辞書型データなどのように,添え字ではなく,キーを使用して各要素を参照することができる複合データが存在しますので,ここでは,map クラスについて,簡単に紹介しておきます.ここで示すのは,文字列(名前)と int 型(得点)のペアを要素とした map です.14 行目~ 15 行目,または,17 行目に示すように,名前を指定して,その人の得点を得ることができます.このプログラムを実行すると,以下に示すような結果が得られます.
map クラス suzuki さんの得点:40
- また,18 行目~ 19 行目のような処理も可能ですが,map の場合,vector の場合と同様,代入によってすべての要素がコピーされるため,a6 と b6 は,要素の値は同じでも全く別の map クラスのオブジェクトとなります.
- 行列の加減乗(演算子のオーバーロード)
001 #include <stdio.h> 002 #include <iostream> 003 004 using namespace std; 005 006 /**********************/ 007 /* クラスMatrixの定義 */ 008 /**********************/ 009 class Matrix { /* 2次元行列 */ 010 int n; // 行の数 011 int m; // 列の数 012 double **mat; // 行列本体 013 public: 014 Matrix(int, int); // コンストラクタ(引数あり) 015 Matrix(const Matrix &); // 初期化のためのコンストラクタ 016 Matrix() {n = 0;} // コンストラクタ(引数無し) 017 ~Matrix() // デストラクタ 018 { 019 if (n > 0) { 020 for (int i1 = 0; i1 < n; i1++) 021 delete [] mat[i1]; 022 delete [] mat; 023 } 024 } 025 Matrix &operator= (const Matrix &); // =のオーバーロード 026 Matrix operator+ (const Matrix &); // +のオーバーロード 027 Matrix operator- (const Matrix &); // -のオーバーロード 028 Matrix operator* (const Matrix &); // *のオーバーロード 029 friend istream &operator >> (istream &, Matrix &); // >> のオーバーロード 030 friend ostream &operator << (ostream &, Matrix); // << のオーバーロード 031 }; 032 033 /*****************************/ 034 /*コンストラクタ(引数あり) */ 035 /*****************************/ 036 Matrix::Matrix(int n1, int m1) 037 { 038 n = n1; 039 m = m1; 040 mat = new double * [n]; 041 for (int i1 = 0; i1 < n; i1++) 042 mat[i1] = new double [m]; 043 } 044 045 /********************************/ 046 /* 初期化のためのコンストラクタ */ 047 /********************************/ 048 Matrix::Matrix(const Matrix &A) 049 { 050 n = A.n; 051 m = A.m; 052 mat = new double * [n]; 053 for (int i1 = 0; i1 < n; i1++) { 054 mat[i1] = new double [m]; 055 for (int i2 = 0; i2 < m; i2++) 056 mat[i1][i2] = A.mat[i1][i2]; 057 } 058 } 059 060 /*******************************/ 061 /* =のオーバーロード */ 062 /* A = B (A.operator=(B)) */ 063 /*******************************/ 064 Matrix& Matrix::operator= (const Matrix &B) 065 { 066 if (&B != this) { // 自分自身への代入を防ぐ 067 if (n > 0) { // 代入する前のメモリを解放 068 for (int i1 = 0; i1 < n; i1++) 069 delete [] mat[i1]; 070 delete [] mat; 071 } 072 n = B.n; 073 m = B.m; 074 mat = new double * [n]; // メモリの確保と代入 075 for (int i1 = 0; i1 < n; i1++) { 076 mat[i1] = new double [m]; 077 for (int i2 = 0; i2 < m; i2++) 078 mat[i1][i2] = B.mat[i1][i2]; 079 } 080 } 081 082 return *this; 083 } 084 085 /**********************/ 086 /* +のオーバーロード */ 087 /**********************/ 088 Matrix Matrix::operator + (const Matrix &B) 089 { 090 if (n != B.n || m != B.m) { 091 cout << "***error invalid data\n"; 092 exit(1); 093 } 094 095 Matrix C(n, m); 096 097 for (int i1 = 0; i1 < n; i1++) { 098 for (int i2 = 0; i2 < m; i2++) 099 C.mat[i1][i2] = mat[i1][i2] + B.mat[i1][i2]; 100 } 101 102 return C; 103 } 104 105 /**********************/ 106 /* -のオーバーロード */ 107 /**********************/ 108 Matrix Matrix::operator - (const Matrix &B) 109 { 110 if (n != B.n || m != B.m) { 111 cout << "***error invalid data\n"; 112 exit(1); 113 } 114 115 Matrix C(n, m); 116 117 for (int i1 = 0; i1 < n; i1++) { 118 for (int i2 = 0; i2 < m; i2++) 119 C.mat[i1][i2] = mat[i1][i2] - B.mat[i1][i2]; 120 } 121 122 return C; 123 } 124 125 /**********************/ 126 /* *のオーバーロード */ 127 /**********************/ 128 Matrix Matrix::operator* (const Matrix &B) 129 { 130 if (m != B.n) { 131 cout << "***error invalid data\n"; 132 exit(1); 133 } 134 135 Matrix C(n, B.m); 136 137 for (int i1 = 0; i1 < n; i1++) { 138 for (int i2 = 0; i2 < B.m; i2++) { 139 C.mat[i1][i2] = 0.0; 140 for (int i3 = 0; i3 < m; i3++) 141 C.mat[i1][i2] += mat[i1][i3] * B.mat[i3][i2]; 142 } 143 } 144 145 return C; 146 } 147 148 /********************************/ 149 /* 入力( >> のオーバーロード) */ 150 /********************************/ 151 istream &operator >> (istream &stream, Matrix &A) 152 { 153 printf("*** %d 行 %d 列の行列***\n", A.n, A.m); 154 for (int i1 = 0; i1 < A.n; i1++) { 155 printf("%d 行目のデータ\n", i1+1); 156 for (int i2 = 0; i2 < A.m; i2++) { 157 printf(" %d 列目の値は? ", i2+1); 158 stream >> A.mat[i1][i2]; 159 } 160 } 161 162 return stream; 163 } 164 165 /********************************/ 166 /* 出力( << のオーバーロード) */ 167 /********************************/ 168 ostream &operator << (ostream &stream, Matrix A) 169 { 170 for (int i1 = 0; i1 < A.n; i1++) { 171 for (int i2 = 0; i2 < A.m; i2++) 172 stream << " " << A.mat[i1][i2]; 173 stream << "\n"; 174 } 175 176 return stream; 177 } 178 179 int main() 180 { 181 // 182 // 行列の計算(演算子のオーバーロード) 183 // 184 int n, m, l, sw; 185 printf("計算方法( 0 : +, 1 : -, 2 : * ) "); 186 cin >> sw; 187 switch (sw) { 188 189 case 0: // + 190 { 191 printf("--- A+B ---\n"); 192 printf("n 行 m 列の n と m? "); 193 cin >> n >> m; 194 Matrix A(n, m), B(n, m); 195 cout << "Matrix A "; 196 cin >> A; 197 cout << "Matrix B "; 198 cin >> B; 199 cout << "Matrix (A+B)\n"; 200 cout << A+B; 201 break; 202 } 203 204 case 1: // - 205 { 206 printf("--- A-B ---\n"); 207 printf("n 行 m 列の n と m? "); 208 cin >> n >> m; 209 Matrix A(n, m), B(n, m); 210 cout << "Matrix A "; 211 cin >> A; 212 cout << "Matrix B "; 213 cin >> B; 214 cout << "Matrix (A-B)\n"; 215 cout << A-B; 216 break; 217 } 218 219 case 2: // * 220 { 221 cout << "--- A*B ---\n"; 222 printf("n 行 m 列の n と m( A )? "); 223 cin >> n >> m; 224 printf("行列 B の列数は? "); 225 cin >> l; 226 Matrix A(n, m), B(m, l); 227 cout << "Matrix A "; 228 cin >> A; 229 cout << "Matrix B "; 230 cin >> B; 231 cout << "Matrix (A*B)\n"; 232 cout << A*B; 233 break; 234 } 235 } 236 237 return 0; 238 }- 184 行目~ 235 行目
- 変数 x,y が,整数型や浮動小数点型のような基本型であれば,ほとんどの言語において,x と y の加減乗を,例えば,
x + y x - y x * y
- のような形で計算できます.行列やベクトルを使用する世界において,行列(ベクトル) A と B の加減乗を,例えば,
A + B A - B A * B
- のような形で計算できれば,非常に都合が良いと思います.Ruby や Python にはそのような機能が存在しますが,他の言語にはありません.しかし,C++ や Ruby では,演算子の多重定義(演算子のオーバーロード)という機能を利用することによって,上で述べたような演算を実現可能です.一度作成しておけば,それをコピーして,どこでも使用できるため,非常に便利だと思います.なお,ここでは定義していませんが,行列の逆行列を計算することによて,除算に対する多重定義を行うことも可能です.
- この部分は,switch 文を使用して,演算の種類を選択しています.もちろん,実際に使用する場合は,クラス Matrix ( 006 行目~ 177 行目)が定義されていさえすれば,行列どうしの加減乗を通常の演算と同じように実行できます.
- 009 行目~ 031 行目
- クラス Matrix の定義です.演算子のオーバーロードは,int 型などの基本型に対して定義することはできません.ここでは,Matrix クラス(ベクトルを含む)を定義し,そのオブジェクトの演算子をオーバーロードします.オーバーロードする演算子は,025 行目~ 030 行目に示すように,6 個の演算子です.
- クラスの関しては,後ほど(第7章)説明しますが,簡単に言えば,データとそのデータを処理するための関数の集まりです.クラス Matrix では,行列の行数 n,行列の列数 m,及び,行列本体 mat をデータとして定義しています.また,3 種のコンストラクタ,デストラクタ,及び,演算子のオーバーロードのための関数をそのメンバー(構成要素)として定義しています.
- 016 行目の関数 Matrix,017 行目~ 024 行目の関数 ~Matrix だけは,その内容も関数内で定義していますが,他の関数に関しては,関数の外側でその内容を定義しています.もちろん,クラス内で定義されている関数をクラス外で,逆に,クラス外で定義されている関数をクラス内で定義することも可能です.
- 関数 ~Matrix は,デストラクタと呼ばれる特殊な関数であり,その名前も「 ~クラス名」と決まっています.デストラクタは,生成されたクラスのオブジェクトが不必要になったとき呼ばれる関数であり,オブジェクトに対する後始末を行います.ここでは,new 演算子において確保した領域を開放しています.
- クラスの関しては,後ほど(第7章)説明しますが,簡単に言えば,データとそのデータを処理するための関数の集まりです.クラス Matrix では,行列の行数 n,行列の列数 m,及び,行列本体 mat をデータとして定義しています.また,3 種のコンストラクタ,デストラクタ,及び,演算子のオーバーロードのための関数をそのメンバー(構成要素)として定義しています.
- 036 行目~ 043 行目
- 関数 Matrix の定義です.Matrix という関数は,014 行目~ 016 行目に示すように,3 種類あります.C++ においては,引数(関数名の後ろの括弧内に記述された変数のリスト)の型や数が異なれば同じ名前の関数を定義でき(関数名の多重定義(関数名のオーバーロード)),関数を呼ぶとき,引数の型や数が同じ関数が自動的に選択されます.
- 関数 Matrix は,クラス名と同じ名前でなければならないコンストラクタという特殊な関数です.クラスのオブジェクトが定義されたとき,最初に呼ばれる関数であり,初期設定等を行います.このコンストラクタは,095 行目,115 行目などにおいて呼ばれ,行の数,列の数を設定すると共に,指定されたサイズの行列を定義します.また,016 行目に記述されたコンストラクタ(引数がない)は,ここでは使用されていませんが,例えば,
Matrix W;
- のように,W が Matrix クラスのオブジェクトであることだけを宣言したいような場合に呼ばれます.
- 関数 Matrix は,クラス名と同じ名前でなければならないコンストラクタという特殊な関数です.クラスのオブジェクトが定義されたとき,最初に呼ばれる関数であり,初期設定等を行います.このコンストラクタは,095 行目,115 行目などにおいて呼ばれ,行の数,列の数を設定すると共に,指定されたサイズの行列を定義します.また,016 行目に記述されたコンストラクタ(引数がない)は,ここでは使用されていませんが,例えば,
- 048 行目~ 058 行目
- このコンストラクタもここでは使用されていませんが,例えば,
Matrix W1 = W2;
- のように,Matrix W1 を Matrix W2 で初期化したいような場合に呼ばれます.このコンストラクタが無い状態で上で示すような初期化を行いますと,W2 の内容がコピーされて W1 に代入されます.しかし,行列本体 mat は new 演算子を使用して定義されているため,そのアドレスがコピーされるだけであり,W1 と W2 が同じ行列本体を指すことになってしまいます.このコンストラクタは,これを避けるために存在します.
- 引数内(括弧内)の A は,上の例における W2 に相当します.通常,ある変数を引数として渡す場合,その値がコピーされて渡されます.基本型の場合は大きな問題にはなりませんが,大きなサイズのオブジェクトを引数として渡す場合,それをコピーするために余分な時間がかかります.それを避ける一つの方法は,変数のアドレスを渡す方法ですが,その場合,変数を参照する方法が異なってしまいます.以上の点を避けるため,ここでは,変数の参照(別名)を渡しています( & 記号の意味).参照を渡す場合,アドレスを渡す場合と同様,関数内で変数の値を変更可能になりますが,const 指定によって,それを禁止しています.
- 064 行目~ 083 行目
- 代入演算子 = のオーバーロードです.例えば,
W1 = W2;
- のように,Matrix W2 を Matrix W1 に代入したいような場合に呼ばれます.このコンストラクタが無い状態で上で示すような代入を行いますと,初期化の場合と同様,W2 の内容がコピーされて W1 に代入されます.しかし,行列本体 mat は new 演算子を使用して定義されているため,そのアドレスがコピーされるだけであり,W1 と W2 が同じ行列本体を指すことになってしまいます.このコンストラクタは,これを避けるために存在します.
- 088 行目~ 103 行目
- 演算子 + のオーバーロードです.各要素どうしの和を計算しています.
- 108 行目~ 123 行目
- 演算子 - のオーバーロードです.各要素どうしの差を計算しています.
- 128 行目~ 146 行目
- 演算子 * のオーバーロードです.行列の乗算を計算しています.
- 151 行目~ 163 行目
- 演算子 >> のオーバーロードです.この演算子のオーバーロードを行うことによって,196 行目,198 行目などのように,「 cin >> A; 」と記述するだけで,行列に対する入力を行うことができるようになります.
- 168 行目~ 177 行目
- 演算子 << のオーバーロードです.この演算子のオーバーロードを行うことによって,200 行目などのように,「 cout << A+B; 」と記述するだけで,行列に対する出力を行うことができるようになります.
- 平均点以上の人数( 1 次元配列)
- Java
- 平均点以上の人数( 1 次元配列)
01 import java.io.*; 02 03 public class Test { 04 public static void main(String args[]) throws IOException 05 { 06 BufferedReader inp = new BufferedReader(new InputStreamReader(System.in)); 07 int m3; // 人数 08 System.out.printf("人数は? "); 09 m3 = Integer.parseInt(inp.readLine()); 10 int a3[] = new int [m3]; 11 // int a3[] = {1, 2, 3}; のような初期設定も可 12 // int b3[]; 13 // b3 = a3; a3 と b3 は同じ配列(a3 を変更すれば b3 も変化) 14 double mean3 = 0.0; 15 for (int i1 = 0; i1 < m3; i1++) { 16 System.out.printf(" %d 番目の人の点数は? ", i1+1); 17 a3[i1] = Integer.parseInt(inp.readLine()); 18 mean3 += a3[i1]; 19 } 20 mean3 /= m3; 21 int n3 = 0; 22 for (int i1 = 0; i1 < m3; i1++) { 23 if (a3[i1] >= mean3) 24 n3++; 25 } 26 System.out.printf(" 平均点( %f )以上は %d 人\n", mean3, n3); 27 } 28 }- 1 次元配列を利用したプログラムです.人数と各人の点数を入力し,平均点以上の人数を求めています.10 行目において,new 演算子を使用して 1 次元配列を定義していますが,その定義方法は,C++ のプログラムにおける new 演算子を使用した 1 次元配列の定義方法と非常に似ています.実際,a3 はポインタと見なせますので,12 行目~ 13 行目のような代入が可能になります.その結果,a3 と b3 は同じ配列になり,a3 を変更すれば b3 も変化することになります(逆も同様).また,11 行目のような初期化も可能です.
- 14 行目~ 20 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.
- 22 行目~ 25 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.
- 14 行目~ 20 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.
- 平均点以上のクラス数( 2 次元配列)
01 import java.io.*; 02 03 public class Test { 04 public static void main(String args[]) throws IOException 05 { 06 BufferedReader inp = new BufferedReader(new InputStreamReader(System.in)); 07 int m4; // クラス数 08 System.out.printf("クラス数は? "); 09 m4 = Integer.parseInt(inp.readLine()); 10 double mean4 = 0.0; // 全体の平均 11 double c_mean4[] = new double [m4]; // クラス毎の平均 12 int s_num4 = 0; // 全体の人数 13 int a4[][] = new int [m4][]; 14 // int a4[][] = new int [2][3]; 列の数が既知の場合 15 // int a4[][] = {{1, 2, 3}, {4, 5, 6}}; のような初期設定も可 16 for (int i1 = 0; i1 < m4; i1++) { 17 int n_m4; // クラス内の人数 18 System.out.printf(" クラス %d の人数は? ", i1+1); 19 n_m4 = Integer.parseInt(inp.readLine()); 20 a4[i1] = new int [n_m4]; 21 c_mean4[i1] = 0.0; 22 for (int i2 = 0; i2 < n_m4; i2++) { 23 System.out.printf(" クラス %d の %d 番目の人の点数は? ", i1+1, i2+1); 24 a4[i1][i2] = Integer.parseInt(inp.readLine()); 25 c_mean4[i1] += a4[i1][i2]; 26 } 27 mean4 += c_mean4[i1]; 28 s_num4 += n_m4; 29 c_mean4[i1] /= n_m4; // クラス毎の平均 30 } 31 mean4 /= s_num4; // 全体の平均 32 int n4 = 0; 33 for (int i1 = 0; i1 < m4; i1++) { 34 if (c_mean4[i1] >= mean4) 35 n4++; 36 } 37 System.out.printf(" 平均点( %f )以上のクラスは %d \n", mean4, n4); 38 // int b4[][]; 39 // b4 = a4; a4 と b4 は同じ配列(a4 を変更すれば b4 も変化) 40 // int c4[]; 41 // c4 = a4[1]; c4 は,a4 の 2 行目と同じ 1 次元配列 42 // (a4 の 2 行目を変更すれば c4 も変化) 43 } 44 }- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数を入力し,全体の平均点以上の平均点をとったクラス数を求めています.やはり,配列の定義方法は,C++ のプログラムにおける new 演算子を使用した 2 次元配列の定義方法と非常に似ています.まず,13 行目において m4 個 のint 型のポインタを記憶する領域を確保し,そのアドレスを a4 に記憶しています.次に,クラスの人数 n_m4 を入力した後,n_m4 個の int 型データを記憶する領域を確保し,そのアドレスを a4[i1] に記憶しています( 20 行目).このように,各行毎に列の数が異なる 2 次元配列を作成することができます.また,14 行目のように,行数と列数を同時に指定して宣言することも,15 行目のような方法で初期設定をすることも可能です.
- 16 行目の for 文によって,16 行目~ 30 行目がクラスの数だけ繰り返され,31 行目において,全体の平均点を求めています.内側のループ 22 行目~ 26 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a4[i1][i2] に保存し,29 行目において,対応するクラスの平均点を計算しています.
- a4 はポインタとみなせますので,38 行目~ 39 行目のような代入が可能です.その結果,a4 と b4 は同じ配列になり,a4 を変更すれば b4 も変化することになります(逆も同様).また,40 行目~ 41 行目のような代入を行うことによって,2 次元配列 a4 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.c4 は,a4 の 2 行目と同じ 1 次元配列になり,a4 の 2 行目を変更すれば c4 も変化します(逆も同様).しかし,a4 のデータ領域は必ずしも連続していませんので,C++ のプログラムの 2 次元配列に対する説明で述べたような,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- 16 行目の for 文によって,16 行目~ 30 行目がクラスの数だけ繰り返され,31 行目において,全体の平均点を求めています.内側のループ 22 行目~ 26 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a4[i1][i2] に保存し,29 行目において,対応するクラスの平均点を計算しています.
- ファイル入出力( ArrayList クラス)
01 import java.io.*; 02 import java.util.*; 03 04 public class Test { 05 public static void main(String args[]) throws IOException 06 { 07 System.out.printf("ファイル入力(ArrayList クラス)\n"); 08 BufferedReader in = new BufferedReader(new FileReader("data.txt")); 09 PrintStream out = new PrintStream(new FileOutputStream("out.txt")); 10 double mean5 = 0.0; 11 int m5 = 0; 12 String line; 13 ArrayList <Integer> a5 = new ArrayList <Integer> (); 14 while ((line = in.readLine()) != null) { 15 int x = Integer.parseInt(line); 16 a5.add(new Integer(x)); 17 mean5 += x; 18 m5++; 19 out.printf("%d %d\n", m5, x); 20 } 21 in.close(); 22 out.close(); 23 mean5 /= m5; 24 int n5 = 0; 25 for (int i1 = 0; i1 < m5; i1++) { 26 if (a5.get(i1) >= mean5) 27 n5++; 28 } 29 System.out.printf(" 平均点( %f )以上は %d 人\n", mean5, n5); 30 // ArrayList <Integer> b5; 31 // b5 = a5; a5 と b5 は同じ ArrayList(a5 を変更すれば b5 も変化) 32 // ArrayList <Integer> b5 = new ArrayList <Integer> (); 33 // for(int i1 = 0; i1 < 3; i1++) 34 // b5.add(new Integer(i1+1)); 35 // ArrayList <Integer> a5 = new ArrayList <Integer> (b5); 36 } 37 }- 今までの方法においては,データを入力する前に配列のサイズを決めておく必要がありました.例えば,ファイルにいくつかのデータが入っており,その数は未定だったとします.もちろん,今までの方法においても,十分大きなサイズの配列を準備するなど,解決方法がないわけではありませんが,データを入力するたびに,配列サイズが変化してくれればより使いやすいかもしれません.ここでは,java.util パッケージ内の ArrayList クラスを使用して,データ数が未知であるファイル内のデータを読み込み,平均値を求め,平均点以上のデータ数を出力しています.なお,ファイル data.txt には,1 行に 1 つずつのデータが入っているものとします.また,特に必要性はありませんが,データ番号と読み込んだデータをファイル out.txt に書き込んでいます.
- 08 行目において,ファイル data.txt を読み取り用に,また,09 行目において,ファイル out.txt を書き込み用に開いています.14 行目において,ファイル内データを 1 つずつ変数 x に読み込み,19 行目において,データ番号と読み込んだデータをファイルに出力し,21,22 行目において,各ファイルを閉じています.14 行目の while 文によって,データが無くなるまでデータを読み続けます.
- 13 行目において,Integer クラスのオブジェクトを要素とする ArrayList クラスのオブジェクト(拡張された配列と思ってください) a5 を定義しています.この時点では,a5 の要素数は 0 です.ArrayList では,要素の追加,削除,変更を容易に行えます.16 行目においては,入力されたデータを a5 に追加しています.18 行目において,入力されたデータを数えていますが,このようなことを行わなくても,「 a5.size() 」という記述によって,a5 に記憶されている要素数を知ることができます.
- 30 行目~ 31 行目のような代入を行うことも可能ですが,a5 と b5 は同じ ArrayList オブジェクトになり,a5 を変更すれば b5 も変化します(逆も同様).32 行目~ 35 行目に示すように,Collection オブジェクトの各要素を初期値とすることも可能です.この例では,Collection オブジェクトの一種である ArrayList オブジェクト b5 によって,a5 を初期設定しています.この場合は,単なる代入とは異なり,a5 と b5 は,要素の値は同じでも,全く別の ArrayList クラスのオブジェクトとなります.
- 08 行目において,ファイル data.txt を読み取り用に,また,09 行目において,ファイル out.txt を書き込み用に開いています.14 行目において,ファイル内データを 1 つずつ変数 x に読み込み,19 行目において,データ番号と読み込んだデータをファイルに出力し,21,22 行目において,各ファイルを閉じています.14 行目の while 文によって,データが無くなるまでデータを読み続けます.
- TreeMap クラス
01 import java.io.*; 02 import java.util.*; 03 04 public class Test { 05 public static void main(String args[]) throws IOException 06 { 07 System.out.printf("TreeMap クラス\n"); 08 TreeMap- java.util パッケージ内には,上で述べた ArrayList 以外に,いくつかのクラスが定義されています.C++ の map クラス,JavaScript や PHP の連想配列,Python の辞書型データなどのように,添え字ではなく,キーを使用して各要素を参照することができる複合データが存在しますので,ここでは,TreeMap クラスについて,簡単に紹介しておきます.ここで示すのは,文字列(名前)と int 型(得点)のペアを要素とした TreeMap です.12 行目に示すように,名前を指定して,その人の得点を得ることができます.TreeMap の場合も,ArrayList と同様,13 行目~ 14 行目のような代入を行うことも可能ですが,a6 と b6 は同じ TreeMap オブジェクトになり,a6 を変更すれば b6 も変化します(逆も同様).なお,上のプログラムを実行すると,以下に示すような結果が得られます.
TreeMap クラス suzuki さんの得点:40
- 平均点以上の人数( 1 次元配列)
- JavaScript
- 1 次元配列と 2 次元配列
- ここをクリックすれば,ブラウザ上で実行することができます.表示された画面のテキストエリアに,
30 60 50 40 50 70 90 10 30 20 50 80 90 10 30
- のようなデータを設定し(デフォルトとして設定済み),「 OK 」ボタンをクリックすると,上で設定したテキストエリアのデータの下に,以下に示すような実行結果が表示されます.上に示したデータにおいて,1 行目は 1 次元配列用のデータ(データの数が 3 ),2 行目以降が 2 次元配列用のデータになります(クラスの数が 3,各クラスの人数が 5 人,3 人,4 人).また,ページのソースを表示すれば,下に示した JavaScript のソースプログラムも表示可能です.
1 次元配列 平均点( 46.666666666666664 )以上は 2 人 2 次元配列 平均点( 47.5 )以上のクラスは 2
01 <!DOCTYPE HTML> 02 <HTML> 03 <HEAD> 04 <TITLE>配列</TITLE> 05 <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-8"> 06 <SCRIPT TYPE="text/javascript"> 07 /****************************/ 08 /* 配列に対するプログラム例 */ 09 /* coded by Y.Suganuma */ 10 /****************************/ 11 function run() { 12 // 13 // データの取得 14 // 15 let str = document.getElementById("tx").value; 16 let data = str.split("\n"); 17 // 18 // 1 次元配列 19 // 20 str += "\n1 次元配列\n"; 21 let st3 = data[0].split(" "); // 1 行目のデータ,点数 22 let a3 = new Array(); // サイズ未定 23 // let a3 = new Array(100); // サイズが100 24 // let a3 = new Array(1, "abc", 3.5); // 初期設定によって配列確保 25 // let b3 = a3; a3 と b3 は同じ配列(a3 を変更すれば b3 も変化) 26 let mean3 = 0.0; 27 for (let i1 = 0; i1 < st3.length; i1++) { 28 a3[i1] = parseInt(st3[i1]); 29 mean3 += a3[i1]; 30 } 31 mean3 /= st3.length; 32 let n3 = 0; 33 for (let i1 = 0; i1 < st3.length; i1++) { 34 if (a3[i1] >= mean3) 35 n3++; 36 } 37 str += (" 平均点( " + mean3 + " )以上は " + n3 + " 人\n"); 38 // 39 // 2 次元配列 40 // 41 str += "2 次元配列\n"; 42 let mean4 = 0.0; // 全体の平均 43 let s_num4 = 0; // 全体の人数 44 let c_mean4 = new Array(); // クラス毎の平均 45 let a4 = new Array(); 46 let k = 0; 47 for (let i1 = 0; i1 < data.length-1; i1++) { 48 if (data[i1+1].length > 0) { 49 a4[k] = new Array(); // a4[k] = {1, 2, 3}; のような初期設定も可 50 c_mean4[k] = 0.0; 51 let st4 = data[i1+1].split(" "); 52 for (let i2 = 0; i2 < st4.length; i2++) { 53 a4[k][i2] = parseInt(st4[i2]); 54 c_mean4[k] += a4[k][i2]; 55 } 56 mean4 += c_mean4[k]; 57 s_num4 += st4.length; 58 c_mean4[k] /= st4.length; // クラス毎の平均 59 k++; 60 } 61 } 62 mean4 /= s_num4; // 全体の人数 63 let n4 = 0; 64 for (let i1 = 0; i1 < data.length-1; i1++) { 65 if (c_mean4[i1] >= mean4) 66 n4++; 67 } 68 str += (" 平均点( " + mean4 + " )以上のクラスは " + n4 + "\n"); 69 // b4 = a4; a4 と b4 は同じ配列(a4 を変更すれば b4 も変化) 70 // c4 = a4[1]; c4 は,a4 の 2 行目と同じ 1 次元配列 71 // (a4 の 2 行目を変更すれば c4 も変化) 72 // 73 // 結果の設定 74 // 75 document.getElementById("tx").value = str; 76 } 77 </SCRIPT> 78 </HEAD> 79 <BODY STYLE="font-size:130%"> 80 <P STYLE="text-align:center"> 81 <INPUT TYPE="button" VALUE="OK" onClick="run()" STYLE="font-size:90%"><BR><BR> 82 <TEXTAREA TYPE="text" ID="tx" COLS="50" ROWS="10" STYLE="font-size: 100%"> 83 30 60 50 84 40 50 70 90 10 85 30 20 50 86 80 90 10 30 87 </TEXTAREA> 88 </P> 89 </BODY> 90 </HTML>- 15 行目~ 16 行目
- テキストエリアに設定された入力データを変数 str に取り入れ,それを改行で分離し,1 次元配列 data に記憶しています.上に示した入力例の場合は,data は,4 つの要素からなり,各行のデータが文字列として入っています.入力例の 1 行目は 1 次元配列用のデータ,2 行目~ 4 行目が 2 次元配列用のデータです.この例では,3 行から構成されているため,クラスの数は 3,各クラスの人数は 5 人,3 人,4 人となります.
- 20 行目~ 37 行目
- 1 次元配列を利用したプログラムです.21 行目においては,入力データの 1 行目が入っている data[0] をスペースで分離し,1 次元配列 str3 に文字列として記憶しています.これらのデータは,28 行目において,整数型に変換されて 1 次元配列 a3 に記憶されます.
- 22 行目において,new 演算子と Array オブジェクトを使用して,1 次元配列 a3 を定義しています.この定義方法では,初期の配列サイズは 0 になりますが,JavaScript においては,実行時に,配列要素の追加,削除,修正を容易にできます.この例では,28 行目において要素を追加しています.また,23 行目のようなサイズを指定した定義方法,24 行目のような初期値を設定した定義方法も可能です.初期設定の例に示してあるように,同じ配列内で異なる型のデータを利用可能ですが,誤りの原因になる可能性がありますので避けた方が良いと思います.
- 配列の定義方法は,型の指定はありませんが,C++ における new 演算子を使用した 1 次元配列の定義方法と非常に似ています.実際,a3 はポインタと見なせますので,25 行目のような代入が可能になります.その結果,a3 と b3 は同じ配列になり,a3 を変更すれば b3 も変化することになります(逆も同様).
- 26 行目~ 31 行目において,点数を配列 a3 に記憶すると共にそれらの和を計算し,その結果から平均値を計算しています.また,32 行目~ 36 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.なお,27 行目等で使用されている length は,配列の要素数を表しています.従って,st3.length は,配列 str3 の要素数になります.
- 22 行目において,new 演算子と Array オブジェクトを使用して,1 次元配列 a3 を定義しています.この定義方法では,初期の配列サイズは 0 になりますが,JavaScript においては,実行時に,配列要素の追加,削除,修正を容易にできます.この例では,28 行目において要素を追加しています.また,23 行目のようなサイズを指定した定義方法,24 行目のような初期値を設定した定義方法も可能です.初期設定の例に示してあるように,同じ配列内で異なる型のデータを利用可能ですが,誤りの原因になる可能性がありますので避けた方が良いと思います.
- 41 行目~ 71 行目
- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数から,全体の平均点以上の平均点をとったクラス数を求めています.2 次元配列は,45 行目,49 行目に示すように,配列の各要素を再度配列として定義することによって可能です.また,49 行目のコメントに書いたように,初期設定も可能です.
- 47 行目の for 文によって,48 行目~ 60 行目がクラスの数だけ繰り返され,62 行目において,全体の平均点を求めています.内側のループ 52 行目~ 55 行目では,(k + 1) 番目のクラスにおける各人の点数を a4[k][i2] に保存し,58 行目において,対応するクラスの平均点を計算しています.48 行目の if 文は,改行だけの行を除外するために存在します.また,同じ理由によって,変数 i1 をそのまま使用せず,変数 k を使用しています.
- a4 はポインタとみなせますので,69 行目のような代入が可能です.その結果,a4 と b4 は同じ配列になり,a4 を変更すれば b4 も変化することになります(逆も同様).また,70 行目のような代入を行うことによって,2 次元配列 a4 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.c4 は,a4 の 2 行目と同じ 1 次元配列になり,a4 の 2 行目を変更すれば c4 も変化します(逆も同様).しかし,a4 のデータ領域は必ずしも連続していませんので,C++ のプログラムの 2 次元配列に対する説明で述べたような,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- 47 行目の for 文によって,48 行目~ 60 行目がクラスの数だけ繰り返され,62 行目において,全体の平均点を求めています.内側のループ 52 行目~ 55 行目では,(k + 1) 番目のクラスにおける各人の点数を a4[k][i2] に保存し,58 行目において,対応するクラスの平均点を計算しています.48 行目の if 文は,改行だけの行を除外するために存在します.また,同じ理由によって,変数 i1 をそのまま使用せず,変数 k を使用しています.
- キーの利用
- JavaScript では,配列を添え字だけでなく,キーを使用して参照可能です.次のプログラムの 11 行目において,キー付き配列(連想配列)を定義しています.ここをクリックすれば,ブラウザ上で実行することができます.
01 <!DOCTYPE HTML> 02 <HTML> 03 <HEAD> 04 <TITLE>連想配列</TITLE> 05 <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-8"> 06 <LINK REL="stylesheet" TYPE="text/css" HREF="../../master.css"> 07 </HEAD> 08 <BODY CLASS="white"> 09 <H1 CLASS="center">連想配列</H1> 10 <SCRIPT TYPE="text/javascript"> 11 let color = {'red' : '赤', 'blue' : '青'}; 12 document.write(color['red'] + "<BR>\n"); 13 document.write(color['blue'] + "<BR>\n"); 14 // document.write(color[0] + "<BR>\n"); エラー 15 for (let english in color) 16 document.write(" " + english + " は " + color[english] + " です<BR>\n"); 17 </SCRIPT> 18 </BODY> 19 </HTML>
- 1 次元配列と 2 次元配列
- PHP
- 平均点以上の人数( 1 次元配列)
01 <?php 02 printf("人数は? "); 03 $m3 = intval(trim(fgets(STDIN))); 04 $a3 = array(); 05 // $a3 = array(1, "abc", 3.5); // 初期設定も可 06 // $b3 = $a3; $a3 と $b3 は値は同じでも別の配列 07 $mean3 = 0.0; 08 for ($i1 = 0; $i1 < $m3; $i1++) { 09 printf(" %d 番目の人の点数は? ", $i1+1); 10 $a3[$i1]= intval(trim(fgets(STDIN))); 11 $mean3 += $a3[$i1]; 12 } 13 $mean3 /= $m3; 14 $n3 = 0; 15 for ($i1 = 0; $i1 < $m3; $i1++) { 16 if ($a3[$i1] >= $mean3) 17 $n3++; 18 } 19 printf(" 平均点( %f )以上は %d 人\n", $mean3, $n3); 20 ?>- 1 次元配列を利用したプログラムです.人数と各人の点数を入力し,平均点以上の人数を求めています.04 行目において,array 関数を使用して 1 次元配列を定義しています.この定義方法では,初期の配列サイズは 0 になりますが,PHP においては,実行時に,配列要素の追加,削除,修正を容易にできます.この例では,10 行目において要素を追加しています.05 行目のように,初期設定も行えます.初期設定の例に示してあるように,同じ配列内で異なる型のデータを利用可能ですが,誤りの原因になる可能性がありますので避けた方が良いと思います.また,06 行目のような代入を行った場合,a3 と b3 は値は同じでも別の配列になります.C++ における new 演算子を使用した場合,Java,JavaScript,Ruby,Python,C#,VB などと異なりますので注意してください.
- 07 行目~ 13 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.15 行目~ 18 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.
- 平均点以上のクラス数( 2 次元配列)
01 <?php 02 printf("クラス数は? "); 03 $m4 = intval(trim(fgets(STDIN))); // クラス数 04 $mean4 = 0.0; // 全体の平均 05 $c_mean4 = array(); // クラス毎の平均 06 $s_num4 = 0; // 全体の人数 07 $a4 = array(); 08 for ($i1 = 0; $i1 < $m4; $i1++) { 09 printf(" クラス %d の人数は? ", $i1+1); 10 $n_m4 = intval(trim(fgets(STDIN))); // クラス内の人数 11 $a4[$i1] = array(); // $a4[$i1] = array(1, 2, 3); のような初期設定も可 12 $c_mean4[$i1] = 0.0; 13 for ($i2 = 0; $i2 < $n_m4; $i2++) { 14 printf(" クラス %d の %d 番目の人の点数は? ", $i1+1, $i2+1); 15 $a4[$i1][$i2] = intval(trim(fgets(STDIN))); 16 $c_mean4[$i1] += $a4[$i1][$i2]; 17 } 18 $mean4 += $c_mean4[$i1]; 19 $s_num4 += $n_m4; 20 $c_mean4[$i1] /= $n_m4; // クラス毎の平均 21 } 22 $mean4 /= $s_num4; // 全体の人数 23 $n4 = 0; 24 for ($i1 = 0; $i1 < $m4; $i1++) { 25 if ($c_mean4[$i1] >= $mean4) 26 $n4++; 27 } 28 printf(" 平均点( %f )以上のクラスは %d \n", $mean4, $n4); 29 // $b4 = $a4; $a4 と $b4 は値は同じでも別の配列 30 // $c4 = $a4[1]; // $c4 は $a4 の 2 行目と同じ値だが,別の 1 次元配列 31 ?>- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数を入力し,全体の平均点以上の平均点をとったクラス数を求めています.2 次元配列は,07 行目,11 行目に示すように,まず,配列を定義し,その配列の各要素を再び配列として定義することによって可能です.11 行目のコメントに記載してあるように,初期設定を行うこともできます.
- 08 行目の for 文によって,08 行目~ 21 行目がクラスの数だけ繰り返され,22 行目において,全体の平均点を求めています.内側のループ 13 行目~ 17 行目では,($i1 + 1) 番目のクラスにおける各人の点数を入力し,$a4[$i1][$i2] に保存し,20 行目において,対応するクラスの平均点を計算しています.
- 1 次元配列の場合と同様,29 行目のような代入を行った場合,$a4 と $b4 は値は同じでも別の配列になります.また,30 行目のような代入を行うことによって,2 次元配列 $a4 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.この場合も,$c4 は $a4 の 2 行目と同じ値ですが,全く別の 1 次元配列になります.これらの点は,C++ における new 演算子を使用する場合,Java,JavaScript,Ruby,Python,C#,VB などと異なることに注意してください.
- 08 行目の for 文によって,08 行目~ 21 行目がクラスの数だけ繰り返され,22 行目において,全体の平均点を求めています.内側のループ 13 行目~ 17 行目では,($i1 + 1) 番目のクラスにおける各人の点数を入力し,$a4[$i1][$i2] に保存し,20 行目において,対応するクラスの平均点を計算しています.
- ファイル入出力
01 <?php 02 printf("ファイル入出力\n"); 03 $in = fopen("data.txt", "rb"); 04 $out = fopen("out.txt", "wb"); 05 $mean5 = 0.0; 06 $m5 = 0; 07 $a5 = array(); 08 while ($x = fgets($in)) { 09 $a5[$m5] = intval(trim($x)); 10 $mean5 += $a5[$m5]; 11 $m5++; 12 fwrite($out, $m5." ".$a5[$m5-1]."\n"); 13 } 14 fclose($in); 15 fclose($out); 16 $mean5 /= $m5; 17 $n5 = 0; 18 for ($i1 = 0; $i1 < $m5; $i1++) { 19 if ($a5[$i1] >= $mean5) 20 $n5++; 21 } 22 printf(" 平均点( %f )以上は %d 人\n", $mean5, $n5); 23 ?>- 次に,ファイルからデータを入力する場合について考えてみます.ここでは,データ数が未知であるファイル data.txt 内のデータを読み込み,平均値を求め,平均点以上のデータ数を出力しています.なお,ファイル data.txt には,1 行に 1 つずつのデータが入っているものとします.また,特に必要性はありませんが,データ番号と読み込んだデータをファイル out.txt に書き込んでいます.なお,ファイルに対する入出力は,ファイルシステム関数を使用します.
- 03 行目において,ファイル data.txt を読み取り用に,また,04 行目において,ファイル out.txt を書き込み用に開いています.08 行目において,ファイル内データを 1 つずつ変数 $x に読み込み,12 行目において,データ番号と読み込んだデータをファイルに出力し,14,15 行目において,各ファイルを閉じています.09 行目では,07 行目で定義した配列 $a5 に,読み込んだデータを整数型に変換して記憶しています.11 行目において,入力されたデータを数えていますが,このようなことを行わなくても,「 count($a5) 」という記述によって,a5 に記憶されている要素数を知ることができます.
- キーの利用
- PHP では,配列を添え字だけでなく,キーを使用して参照可能です.次のプログラムの 03 行目において,キー付き配列(連想配列)を定義し,04 行目では,キーが "suzuki" である要素の値を出力しています.このプログラムを実行すると,次のような結果が得られます.
キーの利用 suzuki さんの得点:40
01 <?php 02 printf("キーの利用\n"); 03 $a6 = array('suzuki'=>40, 'sato'=>60, 'yamada'=>70); 04 printf(" suzuki さんの得点:%d\n", $a6['suzuki']); 05 ?>
- 平均点以上の人数( 1 次元配列)
- Ruby
- 平均点以上の人数( 1 次元配列)
01 printf("人数は? "); 02 m3 = Integer(gets()); # 人数 03 a3 = Array.new(); 04 #a3 = Array.new(3); # サイズを指定しても良い 05 #a3 = Array[1, "abc", 3.5]; # a3 = [1, "abc", 3.5]; でも良い. 06 #b3 = a3; #a3 と b3 は同じ配列(a3 を変更すれば b3 も変化) 07 mean3 = 0.0; 08 for i1 in (0...m3) 09 printf(" %d 番目の人の点数は? ", i1+1); 10 a3[i1] = Integer(gets()); 11 mean3 += a3[i1]; 12 end 13 mean3 /= Float(m3); 14 n3 = 0; 15 for i1 in (0...m3) 16 if (a3[i1] >= mean3) 17 n3 += 1; 18 end 19 end 20 printf(" 平均点( %f )以上は %d 人\n", mean3, n3);- 1 次元配列を利用したプログラムです.人数と各人の点数を入力し,平均点以上の人数を求めています.03 行目において,Array クラスのインスタンスとして 1 次元配列を定義しています.この定義方法では,初期の配列サイズは 0 になりますが,Ruby においては,実行時に,配列要素の追加,削除,修正を容易にできます.この例では,10 行目において要素を追加しています.04 行目のように配列のサイズを指定したり,05 行目のように初期設定を行うことも可能です.初期設定の例に示してあるように,同じ配列内で異なる型のデータを利用可能ですが,誤りの原因になる可能性がありますので避けた方が良いと思います.また,06 行目のような代入を行った場合,a3 と b3 は同じ配列となり,a3 を変更すれば b3 も変化します(逆も同様).
- 07 行目~ 13 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.平均値は,小数点以下まで求めたいため,Float 関数を使用して,整数型の変数 m3 を浮動小数点型に変換しています( 13 行目).(整数型 / 整数型) は,結果も整数型になり,小数点以下が切り捨てられますが,(浮動小数点型 / 整数型) や (整数型 / 浮動小数点型) の場合は,整数型の部分が浮動小数点型に変換され,結果も浮動小数点型になりますので,必ずしも必要ありません.
- 15 行目~ 19 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.
- 07 行目~ 13 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.平均値は,小数点以下まで求めたいため,Float 関数を使用して,整数型の変数 m3 を浮動小数点型に変換しています( 13 行目).(整数型 / 整数型) は,結果も整数型になり,小数点以下が切り捨てられますが,(浮動小数点型 / 整数型) や (整数型 / 浮動小数点型) の場合は,整数型の部分が浮動小数点型に変換され,結果も浮動小数点型になりますので,必ずしも必要ありません.
- 平均点以上のクラス数( 2 次元配列)
01 printf("クラス数は? "); 02 m4 = Integer(gets()); # クラス数 03 mean4 = 0.0; # 全体の平均 04 c_mean4 = Array.new(); # クラス毎の平均 05 s_num4 = 0; # 全体の人数 06 a4 = Array.new(); 07 #a4 = Array[[1, 2, 3], [10, 20, 30]]; # 全体の初期設定も可 08 for i1 in (0...m4) 09 printf(" クラス %d の人数は? ", i1+1); 10 n_m4 = Integer(gets()); # クラス内の人数 11 a4[i1] = Array.new(); 12 # a4[i1] = Array[1, 2, 3]; # 行毎の初期設定も可 13 c_mean4[i1] = 0.0; 14 for i2 in(0...n_m4) 15 printf(" クラス %d の %d 番目の人の点数は? ", i1+1, i2+1); 16 a4[i1][i2] = Integer(gets()); 17 c_mean4[i1] += a4[i1][i2]; 18 end 19 mean4 += c_mean4[i1]; 20 s_num4 += n_m4; 21 c_mean4[i1] /= Float(n_m4); # クラス毎の平均 22 end 23 mean4 /= Float(s_num4); # 全体の平均 24 n4 = 0; 25 for i1 in (0...m4) 26 if (c_mean4[i1] >= mean4) 27 n4 += 1; 28 end 29 end 30 printf(" 平均点( %f )以上のクラスは %d \n", mean4, n4); 31 #b4 = a4; # a4 と b4 は同じ配列(a4 を変更すれば b4 も変化) 32 #c4 = a4[1]; # c4 は,a4 の 2 行目と同じ 1 次元配列 33 # (a4 の 2 行目を変更すれば c4 も変化)- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数を入力し,全体の平均点以上の平均点をとったクラス数を求めています.2 次元配列は,06 行目,11 行目に示すように,まず,配列を定義し,その配列の各要素を再び配列として定義することによって可能です.また,07 行目のように,全体の初期設定を行うことも,12 行目のように,行毎の初期設定を行うことも可能です.
- 08 行目の for 文によって,08 行目~ 22 行目がクラスの数だけ繰り返され,23 行目において,全体の平均点を求めています.内側のループ 14 行目~ 18 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a4[i1][i2] に保存し,21 行目において,対応するクラスの平均点を計算しています.21 行目,23 行目において,変数 n_m4,s_num4 を浮動小数点型に変換しているのは,1 次元配列を使用したプログラム内で説明したとおりです.
- a4 はポインタとみなせますので,31 行目のような代入が可能です.その結果,a4 と b4 は同じ配列になり,a4 を変更すれば b4 も変化することになります(逆も同様).また,32 行目のような代入を行うことによって,2 次元配列 a4 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.c4 は,a4 の 2 行目と同じ 1 次元配列になり,a4 の 2 行目を変更すれば c4 も変化します(逆も同様).しかし,a4 のデータ領域は必ずしも連続していませんので,C++ のプログラムの 2 次元配列に対する説明で述べたような,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- 08 行目の for 文によって,08 行目~ 22 行目がクラスの数だけ繰り返され,23 行目において,全体の平均点を求めています.内側のループ 14 行目~ 18 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a4[i1][i2] に保存し,21 行目において,対応するクラスの平均点を計算しています.21 行目,23 行目において,変数 n_m4,s_num4 を浮動小数点型に変換しているのは,1 次元配列を使用したプログラム内で説明したとおりです.
- ファイル入出力
01 printf("ファイル入出力\n"); 02 inp = open("data.txt", "r"); 03 out = open("out.txt", "w"); 04 mean5 = 0.0; 05 m5 = 0; 06 a5 = Array.new(); 07 while x = inp.gets() 08 a5[m5] = Integer(x); 09 mean5 += a5[m5]; 10 m5 += 1; 11 out.printf("%d %d\n", m5, a5[m5-1]); 12 end 13 inp.close(); 14 out.close(); 15 mean5 /= Float(m5); 16 n5 = 0; 17 for i1 in (0...m5) 18 if (a5[i1] >= mean5) 19 n5 += 1; 20 end 21 end 22 printf(" 平均点( %f )以上は %d 人\n", mean5, n5);- 次に,ファイルからデータを入力する場合について考えてみます.ここでは,データ数が未知であるファイル data.txt 内のデータを読み込み,平均値を求め,平均点以上のデータ数を出力しています.なお,ファイル data.txt には,1 行に 1 つずつのデータが入っているものとします.また,特に必要性はありませんが,データ番号と読み込んだデータをファイル out.txt に書き込んでいます.なお,ファイル入出力のためには,IO クラス,または,File クラスを利用します.
- 02 行目において,ファイル data.txt を読み取り用に,また,03 行目において,ファイル out.txt を書き込み用に開いています.07 行目において,ファイル内データを 1 つずつ変数 x に読み込み,11 行目において,データ番号と読み込んだデータをファイルに出力し,13,14 行目において,各ファイルを閉じています.08 行目では,06 行目で定義した配列 a5 に,読み込んだデータを整数型に変換して記憶しています.10 行目において,入力されたデータを数えていますが,このようなことを行わなくても,「 a5.size() 」,または,「 a5.length() 」という記述によって,a5 に記憶されている要素数を知ることができます.
- 行列の加減乗(演算子のオーバーロード)
001 # 002 # 演算子のオーバーロード 003 # 004 class Matrix 005 006 def initialize(_n, _m) 007 @_n = _n; 008 @_m = _m; 009 @_mat = Array.new(@_n); 010 for i1 in (0...@_n) 011 @_mat[i1] = Array.new(@_m); 012 end 013 end 014 015 def input() 016 printf("*** %d 行 %d 列の行列***\n", @_n, @_m); 017 for i1 in (0...@_n) 018 printf("%d 行目のデータ\n", i1+1); 019 for i2 in (0...@_m) 020 printf(" %d 列目の値は? ", i2+1); 021 @_mat[i1][i2] = Float(gets()); 022 end 023 end 024 end 025 026 def output() 027 for i1 in (0...@_n) 028 for i2 in (0...@_m) 029 printf(" %f", @_mat[i1][i2]); 030 end 031 printf("\n"); 032 end 033 end 034 035 def col() 036 return @_m; 037 end 038 039 def mat() 040 return @_mat; 041 end 042 043 def set(i, j, v) 044 @_mat[i][j] = v; 045 end 046 047 def +(obj) 048 c = Matrix.new(@_n, @_m); 049 for i1 in (0...@_n) 050 for i2 in (0...@_m) 051 v = @_mat[i1][i2] + (obj.mat)[i1][i2]; # v = @_mat[i1][i2] + obj._mat[i1][i2]; 052 c.set(i1, i2, v); # c._mat[i1][i2] = v; 053 end 054 end 055 return c; 056 end 057 058 def -(obj) 059 c = Matrix.new(@_n, @_m); 060 for i1 in (0...@_n) 061 for i2 in (0...@_m) 062 v = @_mat[i1][i2] - (obj.mat)[i1][i2]; # v = @_mat[i1][i2] - obj._mat[i1][i2]; 063 c.set(i1, i2, v); # c._mat[i1][i2] = v; 064 end 065 end 066 return c; 067 end 068 069 def *(obj) 070 m = obj.col(); # m = obj._m; 071 c = Matrix.new(@_n, m); 072 for i1 in (0...@_n) 073 for i2 in (0...m) 074 v = 0.0; 075 for i3 in (0...@_m) 076 v += @_mat[i1][i3] * (obj.mat)[i3][i2]; # v += @_mat[i1][i3] * obj._mat[i3][i2]; 077 end 078 c.set(i1, i2, v); # c._mat[i1][i2] = v; 079 end 080 end 081 return c; 082 end 083 # attr_reader("_m"); # attr_reader("_m", "_mat"); 084 # attr_accessor("_mat"); # attr_writer("_mat"); 085 end 086 087 printf("計算方法( 0 : +, 1 : -, 2 : * ) "); 088 sw = Integer(gets()); # 計算方法 089 case sw 090 when 0 # + 091 printf("--- A+B ---\n"); 092 printf("n 行 m 列の n と m? "); 093 str = gets(); 094 x = str.split(" "); 095 n = Integer(x[0]); 096 m = Integer(x[1]); 097 a = Matrix.new(n, m) 098 b = Matrix.new(n, m) 099 printf("Matrix A \n"); 100 a.input(); 101 printf("Matrix B \n"); 102 b.input(); 103 printf("Matrix (A+B)\n"); 104 c = a + b; 105 c.output(); 106 when 1 # - 107 printf("--- A-B ---\n"); 108 printf("n 行 m 列の n と m? "); 109 str = gets(); 110 x = str.split(" "); 111 n = Integer(x[0]); 112 m = Integer(x[1]); 113 a = Matrix.new(n, m) 114 b = Matrix.new(n, m) 115 printf("Matrix A \n"); 116 a.input(); 117 printf("Matrix B \n"); 118 b.input(); 119 printf("Matrix (A-B)\n"); 120 c = a - b; 121 c.output(); 122 when 2 # - 123 printf("--- A*B ---\n"); 124 printf("n 行 m 列の n と m( A )? "); 125 str = gets(); 126 x = str.split(" "); 127 n = Integer(x[0]); 128 m = Integer(x[1]); 129 a = Matrix.new(n, m) 130 printf("行列 B の列数は? "); 131 l = Integer(gets()); 132 b = Matrix.new(m, l) 133 printf("Matrix A \n"); 134 a.input(); 135 printf("Matrix B \n"); 136 b.input(); 137 printf("Matrix (A*B)\n"); 138 c = a * b; 139 c.output(); 140 end 141 # 142 # Matrix クラスの利用 143 # 144 printf("***Matrix クラスの利用***\n"); 145 require 'matrix' 146 a = Matrix[[1.0, 1.0], [1.0, 2.0]] 147 b = Matrix[[2.0, -1.0], [-1.0, 1.0]] 148 print a, "\n" 149 # => Matrix[[1.0, 1.0], [1.0, 2.0]] 150 print b, "\n" 151 # => Matrix[[2.0, -1.0], [-1.0, 1.0]] 152 print "a+b ", a+b, "\n" 153 # => a+b Matrix[[3.0, 0.0], [0.0, 3.0]] 154 print "a-b ", a-b, "\n" 155 # => a-b Matrix[[-1.0, 2.0], [2.0, 1.0]] 156 print "a*b ", a*b, "\n" 157 # => a*b Matrix[[1.0, 0.0], [0.0, 1.0]] 158 print "a/a ", a/a, "\n" 159 # => a/a Matrix[[1.0, 0.0], [0.0, 1.0]] 160 print "a*2.0 ", a*2.0, "\n" 161 # => a*2.0 Matrix[[2.0, 2.0], [2.0, 4.0]] 162 print "a/2.0 ", a/2.0, "\n" 163 # => a/2.0 Matrix[[0.5, 0.5], [0.5, 1.0]]- 087 行目~ 140 行目
- 変数 x,y が,整数型や浮動小数点型のような基本型であれば,ほとんどの言語において,x と y の加減乗を,例えば,
x + y x - y x * y
- のような形で計算できます.行列やベクトルを使用する世界において,行列(ベクトル) A と B の加減乗を,例えば,
A + B A - B A * B
- のような形で計算できれば,非常に都合が良いと思います.Python においては,NumPy の matrix クラスを利用して,行列の演算を簡単に実行できます.しかし,C++ や Ruby では,演算子の再定義(演算子のオーバーロード)という機能を利用することによって,上で述べたような演算を実現可能です.除算に対しても,逆行列を利用することによって,演算子のオーバーロードが可能ですが,ここでは割愛します.一度作成しておけば,それをコピーして,どこでも使用できるため,非常に便利だと思います.なお,Ruby では,Matrix クラスやVector クラスを利用することによって,演算子のオーバーロードを使用しなくても,行列やベクトルの演算を簡単に実行することが可能です.
- この部分は,case 文を使用して,演算の種類を選択しています.もちろん,実際に使用する場合は,クラス Matrix ( 004 行目~ 085 行目)が定義されていさえすれば,行列どうしの加減乗を通常の演算と同じように実行できます.変数 a,b,c は,行列を表していますので,大文字で A,B,C と記述したいのですが,Ruby においては,大文字で始まる変数は定数とみなされるため,小文字で記述しています.
- クラスの関しては,後ほど(第7章)説明しますが,簡単に言えば,データとそのデータを処理するための関数の集まりです.クラス Matrix では,行列の行数 @_n,行列の列数 @_m,及び,行列本体 @_mat をデータとして定義し,それらに関わる 9 種類の関数を定義しています.
- 006 行目~ 013 行目
- 048 行目,059 行目などのように,クラスのインスタンスを生成すると最初に呼ばれる関数(関数名は,initialize と決まっている)であり,C++ や Java におけるコンストラクタに相当します.ここでは,行の数,列の数を設定すると共に,指定されたサイズの行列を定義しています.
- 015 行目~ 024 行目
- 100 行目,102 行目等で使用されており,行列に対する入力を行うための関数です.
- 026 行目~ 033 行目
- 105 行目,121 行目等で使用されており,行列に対する出力を行うための関数です.
- 035 行目~ 037 行目
- 070 行目で使用されており,行列の列数を取得するための関数です.一般に,クラス内で定義された @ で始まる変数を,クラスに定義された関数以外から参照することはできませんが,083 行目のように,attr_reader を使用すれば,070 行目のコメントに記述したような方法で変数 @_m の値を読むことができるようになります.その場合は,この関数は必要ありません.
- 039 行目~ 041 行目
- 051 行目,062 行目,076 行目で使用されており,行列本体を取得するための関数です.一般に,クラス内で定義された @ で始まる変数を,クラスに定義された関数以外から参照することはできませんが,083 行目のように,attr_reader を使用すれば,051 行目,062 行目,076 行目のコメントに記述したような方法で変数 @_mat の値を読むことができるようになります.その場合は,この関数は必要ありません.
- 043 行目~ 045 行目
- 052 行目,063 行目,078 行目で使用されており,行列の要素に値を設定するための関数です.一般に,クラス内で定義された @ で始まる変数を,クラスに定義された関数以外から参照することはできませんが,084 行目の後半に記述したように,attr_writer を使用すれば,052 行目,063 行目,078 行目のコメントに記述したような方法で変数 @_mat の値を変更することができるようになります.その場合は,この関数は必要ありません.なお,変数 @_mat は,051 行目,062 行目,076 行目で読み,052 行目,063 行目,078 行目で値を変更しています.このように,読み書きを行う場合は,084 行目の前半に記述したように,attr_accessor を利用した方が簡単です.
- 047 行目~ 056 行目
- 演算子 + のオーバーロードです.各要素どうしの和を計算しています.
- 058 行目~ 067 行目
- 演算子 - のオーバーロードです.各要素どうしの差を計算しています.
- 069 行目~ 082 行目
- 演算子 * のオーバーロードです.行列の乗算を計算しています.
- 144 行目~ 163 行目
- Matrix クラスの使用例です.行列の加減乗除を実行します.乗算は行列 B を右から乗じ,除算は行列 B の逆行列を右から乗じます.実数と行列との乗算,除算も可能です.
- 平均点以上の人数( 1 次元配列)
- Python
- 平均点以上の人数( 1 次元配列,list )
01 # -*- coding: UTF-8 -*- 02 m1 = int(input("(list)人数は? ")) 03 a1 = list() 04 #a1 = [1, "abc", 3.5] # 初期設定も可 05 #b1 = a1 # a1 と b1 は同じ配列(a1 を変更すれば b1 も変化) 06 #c1 = copy.copy(a1) # a1 と c1 は同じ値の異なる配列 07 mean1 = 0.0 08 for i1 in range(0, m1) : 09 print(" ", i1+1, sep=' ', end='') 10 a1.append(int(input(" 番目の人の点数? "))) 11 mean1 += a1[i1] 12 mean1 /= m1 13 n1 = 0 14 for i1 in range(0, m1) : 15 if (a1[i1] >= mean1) : 16 n1 += 1 17 print(" 平均点(", mean1, ")以上は", n1, "人")- 1 次元配列を利用したプログラムです.人数と各人の点数を入力し,平均点以上の人数を求めています.03 行目において,リスト型( list )を使用して 1 次元配列(と似た構造)を定義しています.この定義方法では,初期の配列サイズは 0 になりますが,リスト型においては,実行時に,配列要素の追加,削除,修正が可能であり,現時点における要素数は,「 len(a1) 」という記述によって知ることができます(後に述べる array オブジェクトについても同様).この例では,10 行目において要素を追加しています.04 行目のように初期設定を行うことも可能です.初期設定の例に示してあるように,同じ配列内で異なる型のデータを利用可能ですが,誤りの原因になる可能性がありますので避けた方が良いと思います.また,05 行目のような代入を行った場合,a1 と b1 は同じ配列となり,a1 を変更すれば b1 も変化します(逆も同様).ただし,06 行目のように,a1 の浅いコピーを c1 に代入した場合は,a1 と c1 は同じ値の異なる配列となります.
- 07 行目~ 12 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.13 行目~ 16 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.
- 平均点以上のクラス数( 2 次元配列,list )
01 # -*- coding: UTF-8 -*- 02 m2 = int(input("(list)クラス数は? ")) # クラス数 03 mean2 = 0.0 # 全体の平均 04 c_mean2 = list() # クラス毎の平均 05 s_num2 = 0 # 全体の人数 06 a2 = list() 07 #a2 = [[1, 2, 3], [4, 5, 6]] # 全体の初期設定も可 08 #b2 = a2 # a2 と b2 は同じ配列(a2 を変更すれば b2 も変化) 09 #c2 = copy.copy(a2) # a2 と c2 は同じ配列(a2 を変更すれば c2 も変化) 10 #d2 = copy.deepcopy(a2) # a2 と d2 は同じ値の異なる配列 11 #e2 = a2[1] # a2 と e2 は同じ配列(a2 を変更すれば e2 も変化) 12 for i1 in range(0, m2) : 13 print(" クラス", i1+1, "の人数は? ", sep=' ', end='') 14 n_m2 = int(input()) # クラス内の人数 15 a2.append(list()) 16 # a2.append([1, 2, 3]) # 行毎の初期設定も可 17 c_mean2.append(0.0) 18 for i2 in range(0, n_m2) : 19 print(" クラス", i1+1, "の", i2+1, "番目の人の点数は? ", sep=' ', end='') 20 a2[i1].append(int(input())) 21 c_mean2[i1] += a2[i1][i2] 22 mean2 += c_mean2[i1] 23 s_num2 += n_m2; 24 c_mean2[i1] /= n_m2 # クラス毎の平均 25 mean2 /= s_num2 # 全体の平均 26 n2 = 0 27 for i1 in range(0, m2) : 28 if (c_mean2[i1] >= mean2) : 29 n2 += 1 30 print(" 平均点(", mean2, ")以上のクラスは", n2)- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数を入力し,全体の平均点以上の平均点をとったクラス数を求めています.リスト型( list )を使用して 2 次元配列を定義しています.2 次元配列は,06 行目,15 行目に示すように,まず,配列を定義し,その配列の要素を配列として定義することによって定義可能です.また,07 行目のように,全体の初期設定を行うことも,16 行目のように,行毎の初期設定を行うことも可能です.
- a2 はポインタとみなせますので,08 行目のような代入が可能です.その結果,a2 と b2 は同じ配列になり,a2 を変更すれば b2 も変化することになります(逆も同様).09 行目のように,a2 の浅いコピーを c2 に代入した場合も,同じ配列になります.ただし,10 行目のように,a2 の深いコピーを d2 に代入した場合は,a2 と d2 は同じ値の異なる配列となります.また,11 行目のような代入を行うことによって,2 次元配列 a2 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.e2 は,a2 の 2 行目と同じ 1 次元配列になり,a2 の 2 行目を変更すれば e2 も変化します(逆も同様).しかし,a2 のデータ領域は必ずしも連続していませんので,C++ のプログラムの 2 次元配列に対する説明で述べたような,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- 12 行目の for 文によって,12 行目~ 24 行目がクラスの数だけ繰り返され,25 行目において,全体の平均点を求めています.内側のループ 18 行目~ 21 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a2[i1][i2] に保存し,24 行目において,対応するクラスの平均点を計算しています.
- a2 はポインタとみなせますので,08 行目のような代入が可能です.その結果,a2 と b2 は同じ配列になり,a2 を変更すれば b2 も変化することになります(逆も同様).09 行目のように,a2 の浅いコピーを c2 に代入した場合も,同じ配列になります.ただし,10 行目のように,a2 の深いコピーを d2 に代入した場合は,a2 と d2 は同じ値の異なる配列となります.また,11 行目のような代入を行うことによって,2 次元配列 a2 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.e2 は,a2 の 2 行目と同じ 1 次元配列になり,a2 の 2 行目を変更すれば e2 も変化します(逆も同様).しかし,a2 のデータ領域は必ずしも連続していませんので,C++ のプログラムの 2 次元配列に対する説明で述べたような,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- 平均点以上の人数( 1 次元配列,array )
01 # -*- coding: UTF-8 -*- 02 from array import * 03 m3 = int(input("(array)人数は? ")) 04 a3 = array("i") 05 #a3 = array("i", [1, 2, 3]) # 初期設定も可 06 #b3 = a3 # a3 と b3 は同じ配列(a3 を変更すれば b3 も変化) 07 #c3 = copy.copy(a3) # a3 と c3 は同じ値の異なる配列 08 mean3 = 0.0 09 for i1 in range(0, m3) : 10 print(" ", i1+1, sep=' ', end='') 11 a3.append(int(input(" 番目の人の点数? "))) 12 mean3 += a3[i1] 13 mean3 /= m3 14 n3 = 0 15 for i1 in range(0, m3) : 16 if (a3[i1] >= mean3) : 17 n3 += 1 18 print(" 平均点(", mean3, ")以上は", n3, "人")- array オブジェクトを使用して,1 次元配列を実現しています.その内容は,list を使用した場合とほとんど同じですが,配列の定義方法が多少異なっています.array オブジェクトは,基本的な値(文字( bytes 型),整数,浮動小数点数)の配列を扱いますので,配列内では同じデータ型だけを扱うことが可能であり,04 行目に示すように,扱うデータ型を指定してやる必要があります(この例の場合は,整数型).なお,05 行目に示すように,初期設定も可能です.
- 平均点以上のクラス数( 2 次元配列,array )
01 # -*- coding: UTF-8 -*- 02 from array import * 03 m4 = int(input("(array)クラス数は? ")) # クラス数 04 mean4 = 0.0 # 全体の平均 05 c_mean4 = array("f") # クラス毎の平均 06 s_num4 = 0 # 全体の人数 07 a4 = list() 08 #a4 = [array("i", [1, 2, 3]), array("i", [4, 5, 6])] # 全体の初期設定も可 09 #b4 = a4 # a4 と b4 は同じ配列(a4 を変更すれば b4 も変化) 10 #c4 = copy.copy(a4) # a4 と c4 は同じ配列(a4 を変更すれば c4 も変化) 11 #d4 = copy.deepcopy(a4) # a4 と d4 は同じ値の異なる配列 12 #e4 = a4[1] # a4 と e4 は同じ配列(a4 を変更すれば e4 も変化) 13 for i1 in range(0, m4) : 14 print(" クラス", i1+1, "の人数は? ", sep=' ', end='') 15 n_m4 = int(input()) # クラス内の人数 16 a4.append(array("i")) 17 c_mean4.append(0.0) 18 for i2 in range(0, n_m4) : 19 print(" クラス", i1+1, "の", i2+1, "番目の人の点数は? ", sep=' ', end='') 20 a4[i1].append(int(input())) 21 c_mean4[i1] += a4[i1][i2] 22 mean4 += c_mean4[i1] 23 c_mean4[i1] /= n_m4 # クラスの平均 24 s_num4 += n_m4; 25 mean4 /= s_num4 26 n4 = 0 27 for i1 in range(0, m4) : 28 if (c_mean4[i1] >= mean4) : 29 n4 += 1 30 print(" 平均点(", mean4, ")以上のクラスは", n4)- array オブジェクトを使用して,2 次元配列を実現しています.その内容は,list を使用した場合とほとんど同じですが,配列の定義方法が多少異なっています.array オブジェクトを使用して 2 次元配列を定義するためには,07 行目,16 行目のような方法をとるか,行列全体を 08 行目のような形で初期設定してやる必要があります.
- 平均点以上の人数( 1 次元配列,NumPy )
01 # -*- coding: UTF-8 -*- 02 import numpy as np 03 m5 = int(input("(NumPy)人数は? ")) 04 a5 = np.empty(m5) 05 #a5 = np.array([1, 2, 3], np.int) # np.array([1, 2, 3]) でも可 06 #a5 = np.array([1, 2, 3], np.float) # np.array([1.0, 2.0, 3.0]) でも可 07 #b5 = a5 # a5 と b5 は同じ配列(a5 を変更すれば b5 も変化) 08 #c5 = copy.copy(a5) # a5 と c5 は同じ値の異なる配列 09 mean5 = 0.0 10 for i1 in range(0, m5) : 11 print(" ", i1+1, sep=' ', end='') 12 a5[i1] = int(input(" 番目の人の点数? ")) 13 mean5 += a5[i1] 14 mean5 /= m5 15 n5 = 0 16 for i1 in range(0, m5) : 17 if (a5[i1] >= mean5) : 18 n5 += 1 19 print(" 平均点(", mean5, ")以上は", n5, "人")- NumPy の array クラスを使用して,1 次元配列を実現しています.その内容は,list を使用した場合とほとんど同じですが,配列の定義方法が多少異なっています.NumPy の配列は,C/C++ の配列と同様,メモリの連続領域上に確保されます.また,各要素の型はすべて同じで,かつ,多次元配列における各次元ごとの要素数が等しくなければなりません.このことによって,より高速な処理が可能になっています.
- 04 行目において,要素数が m5 であり,すべての要素の値が不定である配列 a4 を定義しています.05 行目のように,初期設定を行うことも可能です.要素が整数型の場合はデータ型を指定する必要がありませんが,整数型以外の場合は,06 行目に示すように,小数点を付加するか(浮動小数点型の場合),または,データ型を指定する必要があります.
- 平均点以上のクラス数( 2 次元配列,NumPy )
01 # -*- coding: UTF-8 -*- 02 import numpy as np 03 m6 = int(input("(NumPy)クラス数は? ")) # クラス数 04 n_m6 = int(input("クラス内の人数は? ")) # クラス内の人数 05 mean6 = 0.0 # 全体の平均 06 s_num6 = m6 * n_m6 # 全体の人数 07 c_mean6 = np.zeros(m6, np.float) # クラス毎の平均 08 a6 = np.empty((m6,n_m6)) 09 #a6 = np.array([[1, 2, 3], [4, 5, 6]]) # 全体の初期設定も可 10 #b6 = a6 # a6 と b6 は同じ配列(a6 を変更すれば b6 も変化) 11 #c6 = copy.copy(a6) # a6 と c6 は同じ値の異なる配列 12 #e6 = a6[1] # a6 と e6 は同じ配列(a6 を変更すれば e6 も変化) 13 for i1 in range(0, m6) : 14 print(" クラス", i1+1) 15 for i2 in range(0, n_m6) : 16 print(" ", i2+1, "番目の人の点数は? ", sep=' ', end='') 17 a6[i1][i2] = int(input()) 18 c_mean6[i1] += a6[i1][i2] 19 mean6 += c_mean6[i1] 20 c_mean6[i1] /= n_m6 # クラスの平均 21 mean6 /= s_num6 22 n6 = 0 23 for i1 in range(0, m6) : 24 if (c_mean6[i1] >= mean6) : 25 n6 += 1 26 print(" 平均点(", mean6, ")以上のクラスは", n6)- NumPy の array クラスを使用して,2 次元配列を実現しています.その内容は,list を使用した場合とほとんど同じですが,配列の定義方法が多少異なっています.07 行目では,すべての要素の値が 0.0 である 1 次元配列を定義しています(浮動小数点型).また,08 行目では,m6 行 n_m6 列のすべての要素の値が不定である 2 次元配列を定義しています(整数型).なお,09 行目のような初期設定も可能です.
- a6 はポインタとみなせますので,10 行目のような代入が可能です.その結果,a6 と b6 は同じ配列になり,a6 を変更すれば b6 も変化することになります(逆も同様).11 行目のように,a6 の浅いコピーを c6 に代入すると,a6 と c6 は同じ値の異なる配列となります.この点は,先に述べたリスト型や array オブジェクトを使用した場合と異なりますので注意してください.また,12 行目のような代入を行うことによって,2 次元配列 a6 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.e6 は,a6 の 2 行目と同じ 1 次元配列になり,a6 の 2 行目を変更すれば e6 も変化します(逆も同様).a6 のデータ領域は連続していますが,C++ のプログラムの 2 次元配列に対する説明で述べたような,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- ファイル入出力( array,NumPy )
01 # -*- coding: UTF-8 -*- 02 from array import * 03 import numpy as np 04 # array 05 a7 = [array("i", [0, 0, 0]), array("i", [0, 0, 0])] 06 f_i = open('array.txt', 'r') 07 f_o = open('out1.txt', 'w') 08 str = f_i.read() 09 f_i.close() 10 s1 = str.split("\n") 11 for i1 in range(0, 2) : 12 s2 = s1[i1].split(" ") 13 f_o.write(s1[i1] + "\n"); 14 for i2 in range(0, 3) : 15 a7[i1][i2] = int(s2[i2]) 16 print(a7) 17 f_o.close() 18 # Numpy 19 a8 = np.empty((2,3)) 20 a8 = np.loadtxt('array.txt') 21 np.savetxt('out2.txt', a8) 22 print(a8)- 05 行目~ 17 行目
- 次に,ファイルからデータを入力する場合について考えてみます.ここでは,ファイル array.txt に,
1 2 3 4 5 6
- のようなデータが保存されていたとします.
- この例では,array オブジェクトを使用して定義された 2 行 3 列の配列 a7 にデータを読み込んでいます.06 行目において,ファイル array.txt を読み取り専用で開き,08 行目において,ファイル内のデータすべてを変数 str に読み込んでいます.10 行目では,str に保存されたデータを改行で分離し,配列 s1 に各行のデータを記憶しています.12 行目では,各行のデータを半角スペースで分離し,配列 s2 に記憶しています.最後に,s2 に記憶されたデータを整数型に変換して a7 に記憶しています( 15 行目).また,07 行目において書き込み用に開いたファイル out1.txt に,13 行目において,読み込んだデータと同じデータを書き込んでいます.なお,ファイル入出力も参考にしてください.
- 19 行目~ 22 行目
- 上で使用したファイルと同じものから,NumPy を使用して読み込み,読み込んだデータをファイル out2.txt に出力している例です.
- 辞書型
- ここでは,辞書型(マッピング型,dict )を利用して,配列に似た構造を実現しています.辞書型においては,03 行目,または,04 行目のような初期設定が可能です.辞書型を使用すれば,05 行目に示すように,キーを利用して対応する値を得ることが可能になります.06 行目のような代入を行えば,a9 と b9 は同じ辞書になり,a9 を変更すれば b9 も変化します.
辞書型 suzuki さんの得点: 40
01 # -*- coding: UTF-8 -*- 02 print("辞書型") 03 a9 = {"suzuki" : 40, "sato" : 60, "yamada" : 70} 04 #a9 = dict(suzuki = 40, sato = 60, yamada = 70) 05 print(" suzuki さんの得点:", a9.get("suzuki")) 06 #b9 = a9 # a9 と b9 は同じ辞書(a9 を変更すれば b9 も変化) - 行列の演算
01 # -*- coding: UTF-8 -*- 02 from array import * 03 import numpy as np 04 # list 05 x1 = [[1, 2], [3, 4]] 06 y1 = [[2, 0], [0, 2]] 07 print("list x1", x1, "y1", y1) 08 print("x1+y1", x1 + y1) 09 #print(x1 - y1) サポート無し 10 #print(x1 * y1) サポート無し 11 # array 12 x2 = [array("f", [1, 2]), array("f", [3, 4])] 13 y2 = [array("f", [2, 0]), array("f", [0, 2])] 14 print("arrayt x2", x2, "y2", y2) 15 print("x2+y2", x2 + y2) 16 #print(x2 - y2) サポート無し 17 #print(x2 * y2) サポート無し 18 # NumPy ( array ) 19 x3 = np.array([[1.0, 2.0], [3.0, 4.0]]) 20 y3 = np.array([[2.0, 0.0], [0.0, 2.0]]) 21 print("np.array") 22 print(x3, "x3") 23 print(y3, "y3") 24 print(x3 + y3, "x3+y3") 25 print(x3 - y3, "x3-y3") 26 print(x3 * y3, "x3*y3") 27 # NumPy ( matrix ) 28 x4 = np.matrix([[1.0, 2.0], [3.0, 4.0]]) 29 y4 = np.matrix([[2.0, 0.0], [0.0, 2.0]]) 30 print("np.matrix") 31 print(x4, "x4") 32 print(y4, "y4") 33 print(x4 + y4, "x4+y4") 34 print(x4 - y4, "x4-y4") 35 print(x4 * y4, "x4*y4")- 行列の演算(加減乗)を実行してみます.まず,リスト型( list ),及び,array オブジェクトに対しては,減算,乗算は定義されていません.加算を行うと,行列の連結が実行されます.この例の場合は,4 行 2 列の行列になります.
- NumPy の array クラス,及び,matrix クラスの場合は,加算,減算は,要素どうしの演算になります.array クラスにおいては,乗算も要素どうしの演算になりますが,matrix クラスでは,数学における行列の乗算と同じ結果になります.このプログラム内の出力文による出力結果は以下のようになります.
list x1 [[1, 2], [3, 4]] y1 [[2, 0], [0, 2]] x1+y1 [[1, 2], [3, 4], [2, 0], [0, 2]] arrayt x2 [array('f', [1.0, 2.0]), array('f', [3.0, 4.0])] y2 [array('f', [2.0, 0.0]), array('f', [0.0, 2.0])] x2+y2 [array('f', [1.0, 2.0]), array('f', [3.0, 4.0]), array('f', [2.0, 0.0]), array('f', [0.0, 2.0])] np.array [[ 1. 2.] [ 3. 4.]] x3 [[ 2. 0.] [ 0. 2.]] y3 [[ 3. 2.] [ 3. 6.]] x3+y3 [[-1. 2.] [ 3. 2.]] x3-y3 [[ 2. 0.] [ 0. 8.]] x3*y3 np.matrix [[ 1. 2.] [ 3. 4.]] x4 [[ 2. 0.] [ 0. 2.]] y4 [[ 3. 2.] [ 3. 6.]] x4+y4 [[-1. 2.] [ 3. 2.]] x4-y4 [[ 2. 4.] [ 6. 8.]] x4*y4
- 平均点以上の人数( 1 次元配列,list )
- C#
- 平均点以上の人数( 1 次元配列)
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 Console.Write("人数は? "); 08 int m3 = int.Parse(Console.ReadLine()); 09 int[] a3 = new int [m3]; 10 // int[] a3 = new int [] {1, 2, 3}; のような初期設定も可 11 // int[] a3 = new[] {1, 2, 3}; 12 // int[] a3 = {1, 2, 3}; 13 // int[] b3; 14 // b3 = a3; a3 と b3 は同じ配列(a3 を変更すれば b3 も変化) 15 double mean3 = 0.0; 16 for (int i1 = 0; i1 < m3; i1++) { 17 Console.Write(" " + (i1+1) + " 番目の人の点数は? "); 18 a3[i1] = int.Parse(Console.ReadLine()); 19 mean3 += a3[i1]; 20 } 21 mean3 /= m3; 22 int n3 = 0; 23 for (int i1 = 0; i1 < m3; i1++) { 24 if (a3[i1] >= mean3) 25 n3++; 26 } 27 Console.WriteLine(" 平均点( " + mean3 + " )以上は " + n3 + " 人"); 28 } 29 }- 1 次元配列を利用したプログラムです.人数と各人の点数を入力し,平均点以上の人数を求めています.09 行目において,new 演算子を使用して 1 次元配列を定義していますが,その定義方法は,Java における定義方法と非常に似ています.実際,a3 はポインタと見なせますので,14 行目のような代入が可能になります.その結果,a3 と b3 は同じ配列になり,a3 を変更すれば b3 も変化することになります(逆も同様).また,10 行目~ 12 行目のような初期化も可能です.
- 15 行目~ 21 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.
- 22 行目~ 26 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.
- 15 行目~ 21 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.
- 平均点以上のクラス数( 2 次元配列)
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 Console.Write("クラス数は? "); 08 int m4 = int.Parse(Console.ReadLine()); // クラス数 09 double mean4 = 0.0; // 全体の平均 10 double[] c_mean4 = new double [m4]; // クラス毎の平均 11 int s_num4 = 0; // 全体の人数 12 int[][] a4 = new int [m4][]; 13 14 // int[][] a4 = new int [2][3]; // この記述は許されない 15 // int[][] a4 = new int[][] { // 行毎に列数が変わっても良い 16 // new int[] {10, 20, 30}, 17 // new int[] {40, 50, 60} 18 // }; 19 // int[][] a4 = new int [2][]; 20 // a4[0] = new int[] {10, 20, 30}; 21 // a4[1] = new int[] {40, 50, 60}; 22 23 // int[,] a4 = {{10, 20, 30}, {40, 50, 60}}; // 以下のような方法も可能 24 // int[,] a4 = new int[,] {{10, 20, 30}, {40, 50, 60}}; 25 // int[,] a4 = new[,] {{10, 20, 30}, {40, 50, 60}}; 26 // int[,] a4 = new int [2,3]; // 初期設定を行わない 27 28 for (int i1 = 0; i1 < m4; i1++) { 29 Console.Write(" クラス " + (i1+1) +" の人数は? "); 30 int n_m4 = int.Parse(Console.ReadLine()); // クラス内の人数 31 a4[i1] = new int [n_m4]; 32 c_mean4[i1] = 0.0; 33 for (int i2 = 0; i2 < n_m4; i2++) { 34 Console.Write(" クラス " + (i1+1) + " の " + (i2+1) + " 番目の人の点数は? "); 35 a4[i1][i2] = int.Parse(Console.ReadLine()); 36 c_mean4[i1] += a4[i1][i2]; 37 } 38 mean4 += c_mean4[i1]; 39 s_num4 += n_m4; 40 c_mean4[i1] /= n_m4; // クラス毎の平均 41 } 42 mean4 /= s_num4; // 全体の平均 43 int n4 = 0; 44 for (int i1 = 0; i1 < m4; i1++) { 45 if (c_mean4[i1] >= mean4) 46 n4++; 47 } 48 Console.WriteLine(" 平均点( " + mean4 + " )以上のクラスは " + n4); 49 // int b4[][]; 50 // b4 = a4; a4 と b4 は同じ配列(a4 を変更すれば b4 も変化) 51 // int c4[]; 52 // c4 = a4[1]; c4 は,a4 の 2 行目と同じ 1 次元配列 53 // (a4 の 2 行目を変更すれば c4 も変化) 54 // 上記の処理は,int[,] a4; の形で宣言したときは不可能 55 } 56 }- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数を入力し,全体の平均点以上の平均点をとったクラス数を求めています.やはり,配列の定義方法は,Java における定義方法と非常に似ています.まず,12 行目において m4 個 のint 型のポインタを記憶する領域を確保し,そのアドレスを a4 に記憶しています.次に,クラスの人数 n_m4 を入力した後,n_m4 個の int 型データを記憶する領域を確保し,そのアドレスを a4[i1] に記憶しています( 31 行目).このように,各行毎に列の数が異なる 2 次元配列を作成することができます.また,14 行目のように,行数と列数を同時に指定して宣言することも,15 行目~ 18 行目,19 行目~ 21 行目のような方法で初期設定をすることも可能です.
- C# では,23 行目~ 26 行目のような形で配列を定義することが可能です.このようにすると,C/C++ の配列のように,連続した領域に確保され,計算速度の向上が期待されます.しかし,参照方法が異なり( a4[i,j] ),各行毎に列数を変えたり,また,各行を 1 次元配列として参照するようなことはできなくなります.
- 28 行目の for 文によって,29 行目~ 40 行目がクラスの数だけ繰り返され,42 行目において,全体の平均点を求めています.内側のループ 33 行目~ 37 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a4[i1][i2] に保存し,40 行目において,対応するクラスの平均点を計算しています.
- a4 はポインタとみなせますので,49 行目~ 50 行目のような代入が可能です.その結果,a4 と b4 は同じ配列になり,a4 を変更すれば b4 も変化することになります(逆も同様).また,51 行目~ 52 行目のような代入を行うことによって,2 次元配列 a4 の各行(この例では 2 行目)を 1 次元配列として扱うことが可能です.c4 は,a4 の 2 行目と同じ 1 次元配列になり,a4 の 2 行目を変更すれば c4 も変化します(逆も同様).しかし,a4 のデータ領域は必ずしも連続していませんので,C++ のプログラムの 2 次元配列に対する説明で述べたような,行をまたいだ領域を 1 次元配列として扱うようなことはできません.
- C# では,23 行目~ 26 行目のような形で配列を定義することが可能です.このようにすると,C/C++ の配列のように,連続した領域に確保され,計算速度の向上が期待されます.しかし,参照方法が異なり( a4[i,j] ),各行毎に列数を変えたり,また,各行を 1 次元配列として参照するようなことはできなくなります.
- ファイル入出力( List クラス)
01 using System; 02 using System.IO; 03 using System.Collections.Generic; 04 05 class Program 06 { 07 static void Main() 08 { 09 double mean5 = 0.0; 10 int m5 = 0; 11 StreamWriter ot = new StreamWriter("out.txt"); 12 string[] lines = File.ReadAllLines("data.txt"); 13 Lista5 = new List (); 14 foreach (string line in lines) { 15 int x = int.Parse(line); 16 a5.Add(x); 17 mean5 += x; 18 m5++; 19 ot.WriteLine(m5 + " " + x); 20 } 21 ot.Close(); 22 mean5 /= m5; // mean5 /= a5.Count; 23 int n5 = 0; 24 for (int i1 = 0; i1 < m5; i1++) { 25 if (a5[i1] >= mean5) 26 n5++; 27 } 28 Console.WriteLine(" 平均点( " + mean5 + " )以上は " + n5 + " 人"); 29 // List <int> b5; 30 // b5 = a5; a5 と b5 は同じ List(a5 を変更すれば b5 も変化) 31 } 32 } - 今までの方法においては,データを入力する前に配列のサイズを決めておく必要がありました.例えば,ファイルにいくつかのデータが入っており,その数は未定だったとします.もちろん,今までの方法においても,十分大きなサイズの配列を準備するなど,解決方法がないわけではありませんが,データを入力するたびに,配列サイズが変化してくれればより使いやすいかもしれません.ここでは,List クラスを使用して,データ数が未知であるファイル内のデータを読み込み,平均値を求め,平均点以上のデータ数を出力しています.なお,ファイル data.txt には,1 行に 1 つずつのデータが入っているものとします.また,特に必要性はありませんが,データ番号と読み込んだデータをファイル out.txt に書き込んでいます.
- 11 行目において,ファイル out.txt を書き込み用に開き,12 行目において,ファイル data.txt 内の全てのデータを配列 lines(配列の各要素は,1 行分のデータ)に読み込んでいます.13 行目において,int 型データを要素とする List クラスのオブジェクト(拡張された配列と思ってください) a5 を定義しています.この時点では,a5 の要素数は 0 です.
- 14 行目において,配列 lines 内の要素を一つずつ取り出し,変数 line に代入しています.15 行目~ 16 行目において,line を整数に変換し,a5 に追加しています.18 行目において,入力されたデータを数えていますが,このようなことを行わなくても,「 a5.Count 」という記述によって,a5 に記憶されている要素数を知ることができます.また,19 行目において,データ番号と読み込んだデータをファイルに出力しています.
- 29 行目~ 30 行目のような代入を行うことも可能ですが,a5 と b5 は同じ List オブジェクトになり,a5 を変更すれば b5 も変化します(逆も同様).
- 11 行目において,ファイル out.txt を書き込み用に開き,12 行目において,ファイル data.txt 内の全てのデータを配列 lines(配列の各要素は,1 行分のデータ)に読み込んでいます.13 行目において,int 型データを要素とする List クラスのオブジェクト(拡張された配列と思ってください) a5 を定義しています.この時点では,a5 の要素数は 0 です.
- Dictionary クラス
01 using System; 02 using System.Collections.Generic; 03 04 class Program 05 { 06 static void Main() 07 { 08 Dictionary- C++ の map クラス,JavaScript や PHP の連想配列,Python の辞書型データなどのように,添え字ではなく,キーを使用して各要素を参照することができる複合データが存在しますので,ここでは,Dictionary クラスについて,簡単に紹介しておきます.ここで示すのは,文字列(名前)と int 型(得点)のペアを要素とした Dictionary です.12 行目に示すように,名前を指定して,その人の得点を得ることができます.Dictionary の場合も,List と同様,13 行目~ 14 行目のような代入を行うことも可能ですが,a6 と b6 は同じ Dictionary オブジェクトになり,a6 を変更すれば b6 も変化します(逆も同様).なお,上のプログラムを実行すると,以下に示すような結果が得られます.
suzuki さんの得点:40
- 平均点以上の人数( 1 次元配列)
- VB
- 平均点以上の人数( 1 次元配列)
01 Module Test 02 Sub Main() 03 Console.Write("人数は? ") 04 Dim m3 As Integer = Integer.Parse(Console.ReadLine()) 05 Dim a3(m3-1) As Integer 06 ' Dim a3(n) As Integer 要素数は n + 1 07 ' Dim a3() As Integer = {1, 2, 3} のような初期設定も可 08 ' Dim a3(2) As Integer = {1, 2, 3} 要素数指定の初期設定は不可 09 ' Dim b3(m3-1) As Integer 10 ' b3 = a3 a3 と b3 は同じ配列(a3 を変更すれば b3 も変化) 11 Dim mean3 As Double = 0.0 12 For i1 As Integer = 0 To m3-1 13 Console.Write(" " & (i1+1) & " 番目の人の点数は? ") 14 a3(i1) = Integer.Parse(Console.ReadLine()) 15 mean3 += a3(i1) 16 Next 17 mean3 /= m3 18 Dim n3 As Integer = 0 19 For i1 As Integer = 0 To m3-1 20 If a3(i1) >= mean3 Then 21 n3 += 1 22 End If 23 Next 24 Console.WriteLine(" 平均点( " & mean3 & " )以上は " & n3 & " 人") 25 End Sub 26 End Module- 1 次元配列を利用したプログラムです.人数と各人の点数を入力し,平均点以上の人数を求めています.05 行目において,1 次元配列を定義しています.括弧内の値 m3 - 1 は,配列のサイズではなく,添え字の最大値であることに注意してください.従って,この定義によって,配列のサイズは m3 となります.a3 はポインタと見なせますので,10 行目のような代入が可能になります.その結果,a3 と b3 は同じ配列になり,a3 を変更すれば b3 も変化することになります(逆も同様).また,07 行目のような初期化も可能です.
- 11 行目~ 17 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.
- 18 行目~ 23 行目において,各人の点数を平均点と比較し,平均点以上の人数を求めています.これも,各人の点数が配列に保存されているからこそ可能な処理です.たった,これだけのプログラムですが,配列の利用と 2 つの繰り返し文を必要としています.
- 11 行目~ 17 行目において,人数分の点数を入力し,それを配列に記憶すると共にそれらの和を計算し,平均値を計算しています.
- 平均点以上のクラス数( 2 次元配列)
01 Module Test 02 Sub Main() 03 Console.Write("クラス数は? ") 04 Dim m4 As Integer = Integer.Parse(Console.ReadLine()) ' クラス数 05 Dim mean4 As Double = 0.0 ' 全体の平均 06 Dim c_mean4(m4-1) As Double ' クラス毎の平均 07 Dim s_num4 As Integer = 0 ' 全体の人数 08 Dim a4(m4-1, 100) As Integer 09 ' Dim a4(,) As Integer = {{1, 2, 3}, {4, 5, 6}} 10 ' Dim a4(,) As Integer = New Integer(,) {{1, 2, 3}, {4, 5, 6}} でも可 11 ' Dim v1(2,3) As Integer = {{1, 2, 3}, {4, 5, 6}} 要素数指定の初期設定は不可 12 For i1 As Integer = 0 To m4-1 13 Console.Write(" クラス " & (i1+1) & " の人数は? ") 14 Dim n_m4 As Integer = Integer.Parse(Console.ReadLine()) ' クラス内の人数 15 c_mean4(i1) = 0.0 16 For i2 As Integer = 0 To n_m4-1 17 Console.Write(" クラス " & (i1+1) & " の " & (i2+1) & " 番目の人の点数は? ") 18 a4(i1, i2) = Integer.Parse(Console.ReadLine()) 19 c_mean4(i1) += a4(i1, i2) 20 Next 21 mean4 += c_mean4(i1) 22 s_num4 += n_m4 23 c_mean4(i1) /= n_m4 ' クラス毎の平均 24 Next 25 mean4 /= s_num4 ' 全体の平均 26 Dim n4 As Integer = 0 27 For i1 As Integer = 0 To m4-1 28 If c_mean4(i1) >= mean4 29 n4 += 1 30 End If 31 Next 32 ' Dim b4(,) As Integer = a4 ' b4 は a4 と同じ配列 33 Console.WriteLine(" 平均点( " & mean4 & " )以上のクラスは " & n4) 34 End Sub 35 End Module- 2 次元配列を利用したプログラムです.クラス数,各クラスの人数,及び,各人の点数を入力し,全体の平均点以上の平均点をとったクラス数を求めています.クラス数を入力した後,06 行目で 1 次元配列,また,08 行目で 2 次元配列を定義しています.この定義によって,許容される各クラスの人数は 101 人になります.また,09 行目~ 10 行目のような方法で初期設定をすることも可能です.なお,各行毎に列数を変えたり,また,各行を 1 次元配列として参照するようなことはできません.
- 12 行目の for 文によって,13 行目~ 23 行目がクラスの数だけ繰り返され,25 行目において,全体の平均点を求めています.内側のループ 16 行目~ 20 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a4(i1,i2) に保存し,23 行目において,対応するクラスの平均点を計算しています.
- a4 はポインタとみなせますので,32 行目のような代入が可能です.その結果,a4 と b4 は同じ配列になり,a4 を変更すれば b4 も変化することになります(逆も同様).
- 12 行目の for 文によって,13 行目~ 23 行目がクラスの数だけ繰り返され,25 行目において,全体の平均点を求めています.内側のループ 16 行目~ 20 行目では,(i1 + 1) 番目のクラスにおける各人の点数を入力し,a4(i1,i2) に保存し,23 行目において,対応するクラスの平均点を計算しています.
- ファイル入出力( List クラス)
01 Imports System.IO 02 Imports System.Collections.Generic 03 04 Module Test 05 Sub Main() 06 Dim a5 As New List(Of Integer) 07 Dim inp As StreamReader = New StreamReader("data.txt") 08 Dim ot As StreamWriter = new StreamWriter("out.txt") 09 Dim mean5 As Double = 0.0 10 Dim m5 As Integer = 0 11 Do While Not inp.EndOfStream 12 Dim x As Integer = Integer.Parse(inp.ReadLine()) 13 a5.Add(x) 14 mean5 += x 15 m5 += 1 16 ot.WriteLine(m5 & " " & x) 17 Loop 18 inp.Close() 19 ot.Close() 20 mean5 /= m5 ' mean5 /= a5.Count 21 Dim n5 As Integer = 0 22 For i1 As Integer = 0 To m5-1 23 if a5(i1) >= mean5 Then 24 n5 += 1 25 End If 26 Next 27 ' Dim b5 As New List(Of Integer) 28 ' b5 = a5 29 Console.WriteLine(" 平均点( " & mean5 & " )以上は " & n5 & " 人") 30 End Sub 31 End Module- 今までの方法においては,データを入力する前に配列のサイズを決めておく必要がありました.例えば,ファイルにいくつかのデータが入っており,その数は未定だったとします.もちろん,今までの方法においても,十分大きなサイズの配列を準備するなど,解決方法がないわけではありませんが,データを入力するたびに,配列サイズが変化してくれればより使いやすいかもしれません.ここでは,List クラスを使用して,データ数が未知であるファイル内のデータを読み込み,平均値を求め,平均点以上のデータ数を出力しています.なお,ファイル data.txt には,1 行に 1 つずつのデータが入っているものとします.また,特に必要性はありませんが,データ番号と読み込んだデータをファイル out.txt に書き込んでいます.
- 06 行目において,Integer 型データを要素とする List クラスのオブジェクト(拡張された配列と思ってください) a5 を定義しています.07 行目において,ファイル data.txt を入力用に開き,データの入力を終了した時点で,18 行目において閉じています.11 行目によって,データが無くなるまで 12 行目~ 16 行目を繰り返し,ファイルから読み込んだデータを a5 に追加しています( 13 行目).15 行目において,入力されたデータを数えていますが,このようなことを行わなくても,「 a5.Count 」という記述によって,a5 に記憶されている要素数を知ることができます.また,08 行目において,出力用に開いたファイル out.txt に,16 行目において,データ番号と読み込んだデータを出力しています.
- 27 行目~ 28 行目のような代入を行うことも可能ですが,a5 と b5 は同じ List オブジェクトになり,a5 を変更すれば b5 も変化します(逆も同様).
- 06 行目において,Integer 型データを要素とする List クラスのオブジェクト(拡張された配列と思ってください) a5 を定義しています.07 行目において,ファイル data.txt を入力用に開き,データの入力を終了した時点で,18 行目において閉じています.11 行目によって,データが無くなるまで 12 行目~ 16 行目を繰り返し,ファイルから読み込んだデータを a5 に追加しています( 13 行目).15 行目において,入力されたデータを数えていますが,このようなことを行わなくても,「 a5.Count 」という記述によって,a5 に記憶されている要素数を知ることができます.また,08 行目において,出力用に開いたファイル out.txt に,16 行目において,データ番号と読み込んだデータを出力しています.
- 平均点以上の人数( 1 次元配列)