
- リテラル
- 文字列およびバイト列リテラル
- 文字列リテラルおよびバイト列リテラル( bytes 型リテラル)は,対応する一重引用符「 ' 」,または,二重引用符「 " 」で囲まれます.Python においては,二つの引用符は同じ意味になります.また,バイト列リテラルに対しては,常に b や B が接頭します.文字列リテラルおよびバイト列リテラルは,C/C++ における文字列定数と似ていますが,C/C++ においては,いずれも二重引用符で囲んだ文字列定数として扱われます.また,C/C++ における文字定数(一重引用符)と文字列定数(二重引用符)との区別はありません.なお,バイト列リテラルは ASCII 文字のみを含むことができます.
>>> "文字列" '文字列' >>> '文字列' '文字列' >>> b"abc" b'abc' >>> b"文字列" # エラー( ASCII 文字だけ可能)
- 文字列中の \ が付加された \n などの文字は,文字列を表示する際,エスケープシーケンスとしての機能を発揮します( \n は改行機能).バックスラッシュ \ をそのまま表示させたい場合は,バックスラッシュ \ によってエスケープしてやる必要があります(これらは,C/C++ においても同様).また,文字ごとにエスケープ処理を行いたくない場合は,文字 r または R を接頭させることによって,バックスラッシュをリテラル文字として扱うことができます.なお,print() はオブジェクトを表示するための組み込み関数です.Python においては,文字列,数値,数値の集まり,など,ほとんどのものをオブジェクトと呼びます.ここでは,文字列を表します.
>>> print("a\nbc") a bc >>> print("a\\nbc") a\nbc >>> print(r"a\nbc") a\nbc- 文字列は,+ 演算子を使用して連結させることができ,* 演算子で反復(このような機能,必要?)させることができます.また,文字列リテラルをスペースで区切って並べると,それらは自動的に連結されます.
>>> 2 * "abc" + "efg" + "hij" 'abcabcefghij' >>> 2 * "abc" "efg" "hij" 'abcefghijabcefghij'
- 複数行に亘る文字列は,対応する 3 連の引用符 ''',または,""" によって可能です.
>>> """ ... abc ... def ... ghi ... """ '\nabc\ndef\nghi\n'
- 上の例に示すように,行末の改行は文字列に含まれますが,行末に \ を付加することによって改行を含まない内容にすることも可能です.
>>> """\ ... abc\ ... def ... ghi\ ... """ 'abcdef\nghi'
- エスケープシーケンス
- Python において使用できるエスケープシーケンスは以下の通りです.
Seq. 説明 \newline 行末に \ を記述するとその行の改行が無視される \\ バックスラッシュ(円記号) \' 一重引用符(シングル クォーテーション) \" 二重引用符(ダブル クォーテーション) \a ベル \b バック スペース \f 改ページ \n 行送り \r 復帰 \t 水平タブ \v 垂直タブ \ooo 8進表記による ASCII 文字 \xhh 16進表記による ASCII 文字 - 以下に示すエスケープシーケンスは,文字列に対してだけ有効です.
\N{name} Unicode データベース中で name という名前の文字 \uxxxx 16-bit の十六進値 xxxx を持つ文字 \Uxxxxxxxx 32-bit の十六進値 xxxxxxxx を持つ文字
- 数値リテラル
- 数値リテラルには 3 種類あります.整数( integer ),浮動小数点数( floating point number ),及び,虚数( imaginary number )です.複素数リテラルは存在しませんが,複素数は実数と虚数の和として作れます.また,数値リテラルには符号が含まれていないことに注意してください.-10 のような数値は,実際には単項演算子 (unary operator) - とリテラル 10 を組み合わせたものとして処理されます.
- 整数リテラルは,10 進数,8 進数 0ohhhh,16 進数 0xhhhh,または,2 進数 0bhhhh を使用して表現できます( o,x,b は大文字でも良い).なお,値がメモリ上に収まるかどうかという問題を除けば,整数リテラルには長さの制限がありません.
>>> 15 15 >>> 0xf 15 >>> 0o17 15 >>> 0b1111 15
- 真偽値も整数リテラルの一種であり,False と True の値をとります.真偽値を表すブール型は整数型の派生型であり,ほとんどの状況でそれぞれ 0 と 1 のように振る舞います.
>>> True True >>> False False >>> 10 + True 11 >>> 10 + False 10
- 浮動小数点数リテラルの取りうる値の範囲は実装に依存します.なお,数値はすべて 10 進数であり,仮数部と指数部を使用して表現する場合,その基数は常に 10 となります.
>>> 12345.01 12345.01 >>> 1234501e-2 12345.01
- 虚数リテラルは,aj ( aJ )のように表現し,実数部が 0.0 の複素数を表します.実数部がゼロでない複素数を生成するには,( 3 + 4j ) のように虚数リテラルに浮動小数点数を加算するか,または,組み込み関数 complex() を使用します.
>>> 3.14j # 3.14J でも良い 3.14j >>> 2.5 + 3.14j (2.5+3.14j) >>> complex(2.5, 3.14) (2.5+3.14j) >>> complex(2.5, 3.14).real # 実数部の参照(参照だけ可能) 2.5 >>> complex(2.5, 3.14).imag # 虚数部の参照(参照だけ可能) 3.14
- 数値リテラルには 3 種類あります.整数( integer ),浮動小数点数( floating point number ),及び,虚数( imaginary number )です.複素数リテラルは存在しませんが,複素数は実数と虚数の和として作れます.また,数値リテラルには符号が含まれていないことに注意してください.-10 のような数値は,実際には単項演算子 (unary operator) - とリテラル 10 を組み合わせたものとして処理されます.
- 文字列およびバイト列リテラル
- 変数
- C/C++ において,変数は,数値や文字を記憶するメモリ内の特定の領域に着けられた名前です.リテラルとは異なり,あらかじめそこに記憶されるデータが常に決まっているわけではありません.しかし,データの型(整数,浮動小数点数,文字列等)により,必要とする領域の大きさや表現方法が異なりますので,ある変数が示す領域に任意のデータを記憶するわけにはいきません.そこで,C/C++ においては,前もって,その領域に記憶すべきデータの型( type )を指定してやる必要があります.これを,変数の型宣言と言います. 例えば,x を整数( int 型の数値)を記憶する変数としたとき,
int x = 10;
- のような方法で型宣言を行います.ただし,「 = 10 」の部分は,変数 x にその初期値として 10 を記憶するための記述であり,必要がなければ書く必要はありません.その際は,整数を記憶する際に必要な領域だけが確保されます.一度型宣言を行うと,関数内で宣言した場合は関数内のその宣言以降,関数外で宣言した場合は関数外の他の位置で変数 x を再び宣言したり,他の型の値を代入したりすることはできなくなります.例えば,
int x = 10; x = 20; x = 1.3; x = "abc";
- において,2 行目は正しい文ですが,3 行目に対しては警告が発生され,4 行目はエラーになります.
- しかし,Python においては,代入または入力したデータによって,その変数の型が決まります.ただし,Python の場合は,変数が示す場所(アドレス)にデータ自身が記憶されているわけではなく,変数はデータ(オブジェクト)が記憶されている場所への参照(場所のアドレス)を表しています.従って,C/C++ のように,変数の型という表現は不適切ですが,今後,混乱が生じない範囲で使用していきます.例えば,下の例において,a は整数リテラル 10 への参照(整数型の変数),また,c は複素数リテラルへの参照(複素数型の変数)を表す変数となります.このように,Python における変数は,a は整数リテラル 10 のアドレス,また,c は複素数リテラル 1 + 2j のアドレスを表しているように見えますので,C/C++ におけるポインタと似ています.また,3 行目のように,変数 a に,先に代入した値と異なる型(文字列)の値を記憶することも可能であり,この時点で,変数 a は文字列型の変数となります.
>>> a = 10 >>> c = complex(1, 2) >>> a = "abc"
- 変数に対してその型を宣言しなくてはならないという規則は,非常に面倒なように感じられるかと思いますが,他の場所で別の目的に使用していた変数の値を誤って変更してしまったなどの誤りを防いでくれます.特に,複数の人で作成する大規模なプログラムの場合,同じ変数名を使用しないように管理することはほとんど不可能です.この様な点からも,Python のようなインタプリータ言語は,大規模なプログラム作成には不向きです.
- 識別子(名前)
- 識別子とは,変数,関数,クラス等の名前に相当します.ASCII 範囲では,C/C++ と同様,アルファベット,下線 _,及び,数字(先頭の文字を除く)を利用できます.ただし,下線 _ から始まる識別子には,以下に示すように,特別な意味がある場合があります( * の部分は,任意の文字列).
- _* from module import * で import されません.また,対話インタプリタでは,直前に行われた評価の結果を記憶するために識別子「 _ 」が使われます.
- __*__ システムで定義された (system-defined) 名前です.
- __* そのクラスのプライベートな名前とみなされ,コードが生成される前により長い形式に変換されます.
- _* from module import * で import されません.また,対話インタプリタでは,直前に行われた評価の結果を記憶するために識別子「 _ 」が使われます.
- また,以下に示す識別子は,Python 言語におけるキーワード (keyword) として使われ,通常の識別子として使うことはできません.
False class finally is return None continue for lambda try True def from nonlocal while and del global not with as elif if or yield assert else import pass break except in raise
- 識別子とは,変数,関数,クラス等の名前に相当します.ASCII 範囲では,C/C++ と同様,アルファベット,下線 _,及び,数字(先頭の文字を除く)を利用できます.ただし,下線 _ から始まる識別子には,以下に示すように,特別な意味がある場合があります( * の部分は,任意の文字列).
- 代入文等
- 代入文
- 代入は,基本的に C/C++ と同じような形で行いますが,複数同時の代入( multiple assignment )が可能な点が大きく異なっています(このような機能,必要?).例えば,以下に示す代入文によって,変数 x には 10,変数 y には 12 が代入されます.プログラムを読みにくくする原因ともなりかねません.特別な場合を除き,使用しない方が良いと思います.
>>> x, y = 10, 3 * 4 >>> print(x, y) 10 12
- Python のほとんどのデータは,オブジェクトです.変数が示す場所(アドレス)にデータ自身が記憶されているわけではなく,変数はデータ(オブジェクト)が記憶されている場所への参照(場所のアドレス)を表しています.代入においては,データをコピー(新しく生成)してそのデータに対する参照を代入しているのか,または,データそのものはすでに存在するものを使用し,そのデータに対する参照を代入しているのかといった違いに注意する必要があります.ここでは,整数や浮動小数点数などの基本的なデータについて調べてみます.
# 整数の場合,文字列の場合も同じ 01 >>> a = 10 02 >>> b = 10 03 >>> a == b, a is b 04 (True, True) 05 >>> b = a 06 >>> a == b, a is b 07 (True, True) 08 >>> b = 20 09 >>> a == b, a is b 10 (False, False) 11 >>> a, b 12 (10, 20) # 浮動小数点数の場合,虚数(複素数)の場合も同じ 13 >>> c = 1.2 14 >>> d = 1.2 15 >>> c == d, c is d 16 (True, False) 17 >>> d = c 18 >>> c == d, c is d 19 (True, True) 20 >>> d = 1.3 21 >>> c == d, c is d 22 (False, False) 23 >>> c, d 24 (1.2, 1.3)
- 代入とは,= 記号の右辺で得られた結果を左辺で指定した変数が示す領域に記憶することです.01,02 行目においては,整数リテラル 10 が変数 a,b が示す領域に記憶されます.03,04 行目を見ると,値の比較( == 演算子による比較)においても,オブジェクトの比較( is 演算子による比較)においても,両者は等しくなっています.このことは,整数リテラル 10 が記憶領域のいずれかの場所にただ一つだけ記憶されており,変数 a,b はそのオブジェクトへの参照を表している(オブジェクトのアドレス表している)ようにみえます.つまり,変数 a,b は,C/C++ におけるポインタと非常に似ています.
- 従って,変数 b の値を変数 a に代入しても( 05 行目),その結果は変わりません.また,変数 b の値を変更すると( 08 行目),変数 b は異なる整数リテラル 20 を指すことになり,両者はいずれの比較においても異なってきます( 09,10 行目).当然,変数 b の値を変更しても,変数 a の値は変化しません( 11,12 行目).以上の点から,下に示すような関係が考えられます.
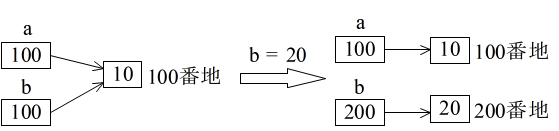
- しかし,浮動小数点の場合は多少異なってきます.変数 c や d がポインタであることに違いはないのですが,13 行目~ 16 行目から明らかなように,全く同じ値のリテラルであっても,異なる場所に記憶されている(異なるオブジェクトである)ことを意味します(下の左図).ただし,変数 d を変数 c に代入すれば,整数の場合と同じような状態になります( 17 行目~ 19 行目,下の右図).
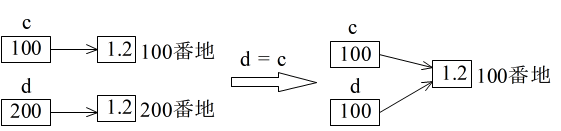
- 従って,変数 b の値を変数 a に代入しても( 05 行目),その結果は変わりません.また,変数 b の値を変更すると( 08 行目),変数 b は異なる整数リテラル 20 を指すことになり,両者はいずれの比較においても異なってきます( 09,10 行目).当然,変数 b の値を変更しても,変数 a の値は変化しません( 11,12 行目).以上の点から,下に示すような関係が考えられます.
- 代入とは,= 記号の右辺で得られた結果を左辺で指定した変数が示す領域に記憶することです.01,02 行目においては,整数リテラル 10 が変数 a,b が示す領域に記憶されます.03,04 行目を見ると,値の比較( == 演算子による比較)においても,オブジェクトの比較( is 演算子による比較)においても,両者は等しくなっています.このことは,整数リテラル 10 が記憶領域のいずれかの場所にただ一つだけ記憶されており,変数 a,b はそのオブジェクトへの参照を表している(オブジェクトのアドレス表している)ようにみえます.つまり,変数 a,b は,C/C++ におけるポインタと非常に似ています.
- del 文
- オブジェクトを削除します.下に示す例においては,a,b qお削除しているため,a (や b )を参照できないため,エラーになっています.
>>> a, b, c = 10, 20, 30 >>> a, b, c (10, 20, 30) >>> del a, b >>> a, b, c Traceback (most recent call last): File "%lt;stdin>", line 1, in <module> NameError: name 'a' is not defined
- import 文
- モジュールを取り込みます.以下の例においては,math モジュールをいくつかの方法で取り込み,math モジュール内のメソッドを呼ぶ方法の変化を表しています.
>>> import math # math モジュールの取り込み >>> math.sqrt(2) 1.4142135623730951 >>> import math as ma # math モジュールを ma というモジュール名として取り込む >>> ma.sqrt(2) 1.4142135623730951 >>> from math import sqrt, fabs # math モジュールからメソッド sqrt,fabs を取り込む >>> sqrt(2) 1.4142135623730951 >>> fabs(-10) 10.0 >>> from math import * # math モジュールからすべてのメソッドを取り込む >>> sqrt(2) 1.4142135623730951 >>> pow(2, 10) 1024.0
- pass 文
- 何も行わない文です.
>>> a = 10 >>> def func(x) : pass ... >>> func(a) >>> if a == 10: ... pass ... else: ... print("test") ... >>>
- 代入文
- 数値演算
- Python には以下に示すような数値演算を行うための演算子が存在します.なお,C/C++ と同様,代入と加算を同時に行う演算子 += など,-=,*=,・・・ も可能です.ただし,C/C++ とは異なり,インクリメント演算子 ++,デクリメント演算子 -- や条件演算子 = ? : が存在しないことに注意してください.
- C/C++ においては,/ 演算子による除算の結果は,除数及び被乗数の型によって決まります.両者とも整数型であれば小数点以下が切り捨てられます.また,% 演算子は,除数,被乗数,共に整数の場合に対してだけ使用可能です.浮動小数点数演算における剰余を計算するためには,fmod / fmod を使用します.
>>> a = 10 >>> a += 5 # a = a + 5 と同じ >>> a 15 >>> a / 2 7.5 >>> a // 2 7
- ここまでの学習を終えたところで,2 つのデータを与えると,乗算と除算の結果を出力するという簡単なプログラムを書いてみましょう.まず,C/C++ のプログラムによって,その構造を見てみましょう.07 行目~ 08 行目において 2 つのデータを入力し,10 行目~ 11 行目において積と商を計算し,13 行目においてその結果を出力しています.以下に示すプログラムをコンパイルした後,実行し,コマンドプロンプト上から 2 つのデータを入力すれば,コマンドプロンプト上にその結果が表示されるはずです.
01 #include <stdio.h> 02 03 int main() 04 { 05 // データの入力 06 double x, y; 07 printf("2つのデータを入力して下さい "); 08 scanf("%lf %lf", &x, &y); 09 // 乗算と除算 10 double mul = x * y; 11 double div = x / y; 12 // 結果の出力 13 printf("乗算=%f 除算=%f\n", mul, div); 14 15 return 0; 16 }- Python においても,その基本は同じです.入出力の方法が,多少,異なっている程度です.
01 # -*- coding: UTF-8 -*- 02 ############################ 03 # 2つのデータの乗算と除算 # 04 # coded by Y.Suganuma # 05 ############################ 06 # データの入力 07 str = input("2つのデータを入力して下さい ") 08 a = str.split() 09 x = int(a[0]) 10 y = int(a[1]) 11 # 和と差の計算 12 mul = x * y 13 div = x / y 14 # 結果の出力 15 print("乗算=", mul, "除算=", div)- 01 行目
- この例のように,1 行目か 2 行目にあるコメントが正規表現 coding[=:]\s*([-\w.]+) にマッチする場合,コメントはエンコード宣言(プログラムを記述する文字コードの宣言)として処理されます.
- 02 行目~ 05 行目
- プログラム全体に対する注釈(コメント)です.Python の注釈は, # から行末までという形で表現します.複数行にわたるコメントは,""" ,または,''' を使用して,以下に示すような形式でも表現できます.
""" 2つのデータの乗算と除算 # coded by Y.Suganuma # """
- 注釈は,プログラムの該当する部分における処理内容を説明するのに使用され,人間がプログラムを読む際,理解しやすくするためのものであり,コンパイラ等によって特別な処理はされません.プログラムを実行するのはコンピュータですが,プログラムを書いたり修正したりするのは人間です.従って,プログラムを書く際に最も注意すべきことは,いかに読み易く,かつ,分かり易いプログラムを書くかという点です.できるだけ多くの注釈を入れておいて下さい.そのことにより,他の人がプログラムを理解しやすくなると共に,プログラム上のエラーも少なくなるはずです.
- 07 行目
- コマンドプロンプト上でデータを変数に入力(標準入力から入力)するためには,組み込み関数 input を使用します.関数は,外部から与えられたデータに基づき,何らかの処理を行いその結果を返します.関数にデータを与える方法の一つが引数です(この例において,input の後ろの括弧内に書かれた部分).input において引数を記述すると,それが末尾の改行を除いて標準出力に書き出され,入力された 1 行を読み込み,文字列として返します(末尾の改行を除去).
- Python のようなインタプリタでは,C++ のような型宣言を行う必要がありません.変数にデータを代入することによって,その変数の型が決まります.変数 str には,文字列が代入されていますので,str の型は文字列型になります.なお,これらの文には,一つの文の終わりにセミコロン「 ; 」が付加してありませんが,付加しても構いません.
- Python のようなインタプリタでは,C++ のような型宣言を行う必要がありません.変数にデータを代入することによって,その変数の型が決まります.変数 str には,文字列が代入されていますので,str の型は文字列型になります.なお,これらの文には,一つの文の終わりにセミコロン「 ; 」が付加してありませんが,付加しても構いません.
- 08 行目
- 07 行目において,2 つのデータを半角スペースで区切った 1 行分のデータが,文字列として変数 str に記憶されます.そこで,これらのデータを,文字列型に対する関数 split を使用して分離します.分離されたデータは,リスト( list )として返されます.ここでは,a[0] と a[1] に入力した 2 つのデータが文字列として入ります.
- 09 行目~ 10 行目
- 組み込み関数 int を利用して,文字列を整数に変換しています.なお,Python においては,整数値の大きさに制限はありません.
- 12 行目~ 13 行目
- これらの文では,見て明らかなように,乗算と除算の計算をし,結果を変数 mul と div に代入しています.変数 x,及び,y に対しては,それらの値が参照されているだけですので,09 行目~ 10 行目で記憶された値がそのまま保たれています.なお,2 番目( y )の値として 0 を入力しない( 0 で割ることになる)ようにしてください.
- 15 行目
- 組み込み関数 print を使用して,結果を出力しています.print においては,引数として渡されたデータが半角スペースで区切って順番に出力され,最後に改行が出力されます.その際,mul や div の値が自動的に文字列に変換されます.なお,12 ~ 13 行目を削除し,15 行目の mul 及び div を,(x * y) 及び (x / y) と記述しても構いません.
- このプログラムを実行し,8 と 3 を,
2つのデータを入力して下さい 8 3- のように入力すると(下線部が入力する部分),以下のような結果が得られます.ここで,整数どうしの除算であっても,小数点以下まで計算されることに注意してください.C/C++ のプログラムとの大きな違いは,まず,除算の結果が,小数点以下が切り捨てられ 2 になることです.また,C/C++ のプログラムの場合,小数点があるデータを入力するとエラーになってしまいます.
乗算= 24 除算= 2.6666666666666665
- 01 行目
- C/C++ との大きな違いの一つは,虚数に対応する型が存在し,複素数に対する演算が,以下に示すように,簡単に行えることです.しかし,C++ においても,complex クラスを使用すれば,プログラム例に示すように簡単に実現できます.
#****************************/ #* 複素数の計算 */ #* coded by Y.Suganuma */ #****************************/ # -*- coding: UTF-8 -*- x1 = complex(1.0, 2.0) x2 = complex(3.0) x3 = complex(0, 2) print ("x1:" + str(x1) + ",x2:" + str(x2) + ",x3:" + str(x3)) print("x1 + x2 = " + str(x1 + x2)) print("x1 - x2 = " + str(x1 - x2)) print("x1 * x2 = " + str(x1 * x2)) print("abs(x1) = " + str(abs(x1))) print("x1 の共役複素数 = " + str(x1.conjugate()))- (出力)
x1:(1+2j),x2:(3+0j),x3:2j x1 + x2 = (4+2j) x1 - x2 = (-2+2j) x1 * x2 = (3+6j) abs(x1) = 2.23606797749979 x1 の共役複素数 = (1-2j)
- 比較と論理演算
- Python には以下に示すような比較演算子が存在します.これらの演算子は,オブジェクト(データ)の値同士を比較します.
< : より小さい a < b > : より大きい a > b <= : 以下 a <= b >= : 以上 a >= b == : 等しい a == b != : 等しくない a != b
- また,以下に示すような比較演算も可能です.
is : 同じオブジェクト a is b is not : 同じオブジェクトではない a is not b
- 以上述べた演算子を利用して,以下に示すような論理演算が可能です.
式1 or 式2 : 論理和(式1 または 式2 が True であれば True,そうでなければ False) 式1 and 式2 : 論理積(式1 及び 式2 が True であれば True,そうでなければ False) not 式 : 否定(式 が False であれば True,そうでなければ False)
- C/C++ とは異なり,例えば,「 x < y < z 」が「 x < y and y < z 」とほぼ等価になることに注意してください.
>>> (3 < 2) and (2 < 5) False >>> 3 < 2 < 5 False >>> 3 < 4 < 5 True
- ビット単位の演算
- Python には,整数に対して,以下に示すようなビット単位の演算を行う演算子が存在します.なお,C/C++ と同様,>>=,・・・等の演算も可能です.
<< : 左にビットシフト a << 3 >> : 右にビットシフト a >> 3 & : ビットごとの論理積 x & y | : ビットごとの論理和 x | y ^ : ビットごとの排他的論理和 x ^ y ~ : 1 の補数( 0 と 1 の逆転) ~x
- 分岐
- if 文
- if 文の一般形式は以下に示すとおりです.式i を順に評価していき,式i が True であれば 文i を実行し,他の部分は実行しません.いずれも True でなく.else 以下が記述されていた場合は,else の後の文を実行します.いずれの文も複数の文から構成されていても構いませんが,スペースまたはタブを使用して,同じレベルの字下げを行う必要があります.ただし,文が一つの文である場合は,コロンの後ろに記述しても構いません.C/C++ における else if 文とほとんど同じです.
- なぜ,「 else if 」でなくて「 elf 」なのでしょうか.多くの人が使い慣れていると共に誰でも理解しやすい「 else if 」で十分なのではないでしょうか.Python では,他にも,スライスや除算の記号「 * 」に対する繰り返し機能の付加など,記号に特別の機能を持たせるようなことを多く行っています.記述のしやすさや自分の好みに重点を置き,理解しやすさを軽視してコンパイラを設計しているとしか思えません.スライスに関しては,FORTRAN における DO 文の仕様「 DO 10 k = 1, 10, 2 」を思い出します.なぜ,この仕様が生き残らなかったのか考えて欲しいと思います.
if 式1 : 文1 [elif 式2 : 文2] ・・・・・ [elif 式n : 文n] [else : 文]
- 例えば,以下のようにして使用します.
# -*- coding: UTF-8 -*- a = int(input("データを入力してください ")) # 標準入力から 1 行入力 if a < 0 : print("負") elif a == 0 : print("0") else : print("正")
- if 文の一般形式は以下に示すとおりです.式i を順に評価していき,式i が True であれば 文i を実行し,他の部分は実行しません.いずれも True でなく.else 以下が記述されていた場合は,else の後の文を実行します.いずれの文も複数の文から構成されていても構いませんが,スペースまたはタブを使用して,同じレベルの字下げを行う必要があります.ただし,文が一つの文である場合は,コロンの後ろに記述しても構いません.C/C++ における else if 文とほとんど同じです.
- if 文
- 繰り返し
- while 文
while 式 : 文1 [else : 文2]
- while 文は,式を評価し,式が True である限り 文1 の実行を繰り返します.式が False になり,else 以下が記述されていた場合は 文2 を実行し,また,記述されていなかった場合は何も行わず,繰り返しを終了します.いずれの文も複数の文から構成されていても構いませんが,スペースまたはタブを使用して,同じレベルの字下げを行う必要があります.ただし,文が一つの文である場合は,コロンの後ろに記述しても構いません.C/C++ における while 文とほとんど同じですが,C/C++ には,else 以下の部分がありません.
- 文1 の実行の途中で break 文が実行されると,文1 の残りの部分を実行せず,現在実行中の while 文から抜け出します( else 以下は実行されない).また,文1 の実行の途中で continue 文が実行されると,文1 の残りの部分を実行せず,式の真偽評価に移ります.
- 例えば,以下に示す内容のスクリプトファイルを実行すると,正のデータが入力されるまで入力を促すことが繰り替えされるはずです.また,0 を入力しても while 文から抜け出しますが,else に対応する箇所は実行されません.
- 文1 の実行の途中で break 文が実行されると,文1 の残りの部分を実行せず,現在実行中の while 文から抜け出します( else 以下は実行されない).また,文1 の実行の途中で continue 文が実行されると,文1 の残りの部分を実行せず,式の真偽評価に移ります.
# -*- coding: UTF-8 -*- a = -1 b = 0 while a <= 0 : a = int(input("data? ")) if a == 0 : break else : b = 1 / a print(b)- 次は,入力されたデータの内,負のデータの最大値を求めるためのプログラムです.99999 を入力するとプログラムを終了します.単なる最大値を求める場合は組み込み関数 max を使用すれば簡単に求めることができますが,この例のように,条件付きの最大値に関してはプログラムを書かざるを得ません.
# -*- coding: UTF-8 -*- sw = 0 x = 0 while x != 99999 : x = int(input("データを入力してください ")) if x < 0 and (sw == 0 or x > max) : max = x sw = 1 print(" 最大値 = " + str(max))
- for 文
for 変数 in イテラブルオブジェクト : 文1 [else : 文2]
- for 文は,イテラブルオブジェクト内の要素が順に変数に代入され,要素が空になるまで,文1 が繰り返し実行されます.要素が空になり,else 以下が記述されていた場合は 文2 を実行し,また,記述されていなかった場合は何も行わず,繰り返しを終了します.いずれの文も複数の文から構成されていても構いませんが,スペースまたはタブを使用して,同じレベルの字下げを行う必要があります.ただし,文が一つの文である場合は,コロンの後ろに記述しても構いません.C++ における範囲 for 文と似た機能を持ち,他の言語にも同じような機能がありますので,使いやすい文だと思います.range 型によってほとんど同じような記述が可能ですが,通常の for 文の形式が使用できないのには,多少の抵抗を感じます.なお,iterable object (イテラブルオブジェクト)とは,リスト,タプル,range など,構成要素を一度に一つずつ返すことができるオブジェクトです.
- 文1 の実行の途中で break 文が実行されると,文1 の残りの部分を実行せず,現在実行中の for 文から抜け出します( else 以下は実行されない).また,文1 の実行の途中で continue 文が実行されると,文1 の残りの部分を実行せず,次の要素による 文1 の実行に移ります.
- 例えば,以下に示すいずれの方法においても,希望する出力が得られるはずです.
- 文1 の実行の途中で break 文が実行されると,文1 の残りの部分を実行せず,現在実行中の for 文から抜け出します( else 以下は実行されない).また,文1 の実行の途中で continue 文が実行されると,文1 の残りの部分を実行せず,次の要素による 文1 の実行に移ります.
>>> for x in [1, 2, 3] : # list ... print(x) ... 1 2 3 >>> for x in (1, 2, 3) : # tuple ... print(x) ... 1 2 3 >>> for x in range(1, 4) : # range ... print(x) ... 1 2 3
- while 文
- with 文
- with 文は,ブロックの実行をコンテキストマネージャによって定義されたメソッドでラップするために使われます.コンテキストマネージャは,コードブロックを実行するために必要な入り口および出口の処理を扱います.簡単に言えば,ブロックの実行を,簡単かつ安全に実行させるための文です.代表的な使い方として,様々なグローバル情報の保存および更新,リソースのロックとアンロック,ファイルのオープンとクローズなどが挙げられます.
- 次に示すのは,ファイルのオープンとクローズの例です.with ブロックに入る際にファイルがオープンされ,ブロックを出ると自動的にファイルがクローズされます.
>>> with open("test.txt", "r") as f : ... a = f.read() ... >>> a '10 20 30\n菅沼義昇\n' >>> f.closed True # 既にクローズされている
- with 文は,ブロックの実行をコンテキストマネージャによって定義されたメソッドでラップするために使われます.コンテキストマネージャは,コードブロックを実行するために必要な入り口および出口の処理を扱います.簡単に言えば,ブロックの実行を,簡単かつ安全に実行させるための文です.代表的な使い方として,様々なグローバル情報の保存および更新,リソースのロックとアンロック,ファイルのオープンとクローズなどが挙げられます.
- try 文
- try 文は,例外処理を行うための文です.以下の例は,while 文で挙げた例と同じように,適切な値が入力されるまで,入力を促すことが繰り返されます.
# -*- coding: UTF-8 -*- while True : try : x = int(input("整数を入力して下さい: ")) break except ValueError : print(" 不適切なデータです!") print(x)
- C/C++ における配列
- C/C++ の配列と 1 : 1 に対応するデータ型が存在しないなど,大きな違いはありますが,Python にも,配列のように複合データを扱うためのデータ型が存在します.この節では,配列の必要性と,配列など,C/C++ における複合データの取り扱いについて説明します.Python の複合データを理解するためにも必要だと思いますが,C/C++ との関係に興味のない方はこの節を読み飛ばしてください.
- 単純な変数を使用して複数のデータを記憶しておきたい場合,記憶したいデータの数だけ変数を用意する必要があります.データの数が少なく,かつ,その数が前もって分かっているような場合は通常の変数によって対応できますが,データ数が多くなり,かつ,その数が前もって分からないような場合はほとんど不可能です.そこで,登場するのが,配列( array )変数という考え方です.数学的な例えをすれば,通常の変数はスカラー変数であり,配列変数はベクトルに対応します(行列等に対応する配列変数も存在しますが,それについては,後ほど述べます).配列変数を定義し,その各要素(ベクトルの各要素)にデータを記憶しておけば上の問題を解決できることになります.
- ある変数がスカラー(単純変数)でなく,配列変数であることを定義するためには,例えば,以下のように記述します.
- 単純な変数を使用して複数のデータを記憶しておきたい場合,記憶したいデータの数だけ変数を用意する必要があります.データの数が少なく,かつ,その数が前もって分かっているような場合は通常の変数によって対応できますが,データ数が多くなり,かつ,その数が前もって分からないような場合はほとんど不可能です.そこで,登場するのが,配列( array )変数という考え方です.数学的な例えをすれば,通常の変数はスカラー変数であり,配列変数はベクトルに対応します(行列等に対応する配列変数も存在しますが,それについては,後ほど述べます).配列変数を定義し,その各要素(ベクトルの各要素)にデータを記憶しておけば上の問題を解決できることになります.
int x[10]; // 要素の数 10 の部分は定数である必要がある
- このように定義することにより,変数 x は 10 個の要素を持った配列変数( 10 次元のベクトル)とみなされ,この場合は,10 個の整数を記憶するために 80( 8×10 )バイトの連続した領域が確保されます.なお,基本的に,要素の数は定数でなければなりません.
- 配列の各要素を参照するためには,ベクトルの場合と同様に,x[i] のように記述すればよいことになります.ただし,添え字 i は,ベクトルとは異なり,上のように定義した場合,0 から 9 まで変化します.従って,
x[5] = 3.0; y = x[3];
- と書くと,配列 x の 6 番目の要素( 5 番目でないことに注意)に値 3.0 が代入され,4 番目の要素に記憶されている値が変数 y に代入されます.また,整数などの数値だけでなく,文字列も複数の文字(データ)の集まりですので,配列によって表現可能です.
- ポインタと配列とは非常に深い関係があります.例えば,
int x[4] = {100, 200, 300, 400}; int *y; // int y[4]; と宣言した場合は,y = x; は実行できない- のような宣言がなされていたとして,以下の説明を行います.100 ~ 400 は,各要素に記憶される値の初期値です.このとき,配列変数 x に対しては,下図の左に示すようなイメージを浮かべると理解しやすいと思います.つまり,x がポインタ変数であり,この変数の値が,連続した領域にある 4 つの変数 x[0],x[1],x[2],及び,x[3] の先頭アドレスを指しているというイメージです.従って,ポインタ変数 x の値を同じポインタ変数である y に代入,つまり,
y = x; または y = &(x[0]);
- という文を実行してやれば,下図の右に示すように,変数 x と変数 y はほとんど同じものになります.例えば,y[2] は x[2] と同じ箇所を参照することになります.ただし,厳密には,全く同じではありません.例えば,「y++」などの演算は可能ですが,「x++」は不可能です.なお,++ は,インクリメント演算子ですが,Python には存在しません.

- 2 次元以上の配列に対しても,1 次元の場合と同様に,ポインタを介して参照等が可能です.例えば,2 次元配列として下のような宣言がなされていたとします.このとき,配列とポインタの関係は,概念的に,下図の左側のような関係になります.
int x[3][2] = {{100, 200}, {300, 400}, {500, 600}};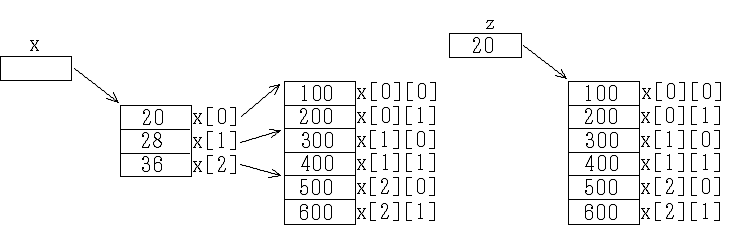
- まず,実際にデータが記憶される場所として,x[0][0] から x[2][1] の連続した 6 個の領域がとられます(この例では,それらが,20 番地からの領域であるとしています).添え字が最も右側から変化していることに注意して下さい(この点は,3 次元以上の配列の場合も同様です).次に,x[0] から x[2] のポインタを要素とする配列があり,その各要素は,配列の各行の値が保存されている場所の先頭を指しています.変数 x は,このポインタ配列の先頭を指していることになります.
- 配列に対し連続的な領域が確保されていますので,上図の右に示すように,2 次元の配列を 1 次元の配列として処理することも可能です.例えば,
int *z = (int *)x; // z = &x[0][0]; でも良い
- のような処理をすれば,z[3] と x[1][1] が同じ場所を指すことになります.一般に,x[i][j] と z[(i×k) + j] は,同じ場所を指すことになります.ただし,k は,配列変数 x の宣言における列の数です(上の例では 2 ).
- 配列においては,データの数を定数で指定しなければなりません.そのため,必要なデータ数が,問題によって異なるような場合は,大きめのサイズの配列を準備しておかなければなりません.しかし,C++ では,new 演算子を使用して,以下に示すように,メモリの動的確保を行うことが可能です(計算時間の犠牲は伴う).new 演算子は,指定された型のデータを指定された数だけ記憶できる領域を確保し,そのアドレスを返します.
int *x = new int [n]; // 要素の数 n は変数でも構わない

- 2 次元以上の配列も同様にして確保できます.例えば,2 行 3 列(行や列の数は変数でも構わない)の配列を確保するためには,以下のように記述します.この結果,概念的には,上図に示すような領域が確保されます(配列のように,データ領域が連続した領域になるとは限らない).なお,上で述べた変数 x や変数 pd は,配列と同様の方法で各要素を参照することができます.
double** pd = new double* [2]; for (i1 = 0; i1 < 2; i1++) pd[i1] = new double [3];
- 上で述べた方法においても,プログラムの実行中にデータの数が n より多くなった場合は対応できなくなります.それを解決する方法の一つが C++ 標準ライブラリ内の多くのクラスです.Python には,上で述べた配列と同じものはなく,C++ 標準ライブラリ内のクラスに似たものだけが存在します.Python の複合データはシーケンス型,集合型,マッピング型(辞書型)に分類されますが,C++ 内のクラスを,このような形で分類し,正確に対応させることはできません.シーケンス型に対しては,添え字 [ ] で参照可能であることから見ると,string クラス,array クラス,vector クラス,tuple クラス(添え字での参照は不可)などが対応します.また,ハッシュを使用している点から見ると,集合型に対しては,unordered_map クラス,unordered_multimap クラス,unordered_set クラス,unordered_multiset クラスなどが対応します.さらに,キーと値を別々に扱う点では,マッピング型(辞書型)に対しては,map クラス,multimap クラス,unordered_map クラス,unordered_multimap クラスが対応します.forward_list クラス(単方向リス)や list クラス(双方向リスト)は,シーケンシャルアクセスだけが可能である点から,シーケンス型に似ていますが,取り扱い方法はかなり異なっています.なお,map クラス,multimap クラス,set クラス,multiset クラスは,二分木として実装されており,データが追加・削除されるたびに,自動的にソートされます.
- 上で述べた C++ のクラスと Python の複合データとの違いは,Python の複合データにおいては,複数の型のデータを同じ変数に保存できる点です.C++ の場合は,tuple クラスを除き,同じ型のデータだけを記憶できます.誤りの原因となりやすいので,一つ複合データ内には同じ型のデータだけを記憶するようにした方が良いと思います.
- C/C++ の配列と 1 : 1 に対応するデータ型が存在しないなど,大きな違いはありますが,Python にも,配列のように複合データを扱うためのデータ型が存在します.この節では,配列の必要性と,配列など,C/C++ における複合データの取り扱いについて説明します.Python の複合データを理解するためにも必要だと思いますが,C/C++ との関係に興味のない方はこの節を読み飛ばしてください.
- 1 次元配列
- ここでは,C/C++ の配列と似たリスト型( list ),array モジュール(数値配列),及び,numpy.ndarray モジュールについて説明します.リストは,一般的に同種の項目の集まりを格納するために使われます.C++ における C++ 標準ライブラリ内の vector クラスと似ていますが,vector とは異なり,異なる型のオブジェクトを要素として持つことができます.しかし,誤りの原因となりやすく,避けた方が良いと思います.
- array モジュールでは,基本的な値(文字( bytes 型),整数,浮動小数点数)の配列をコンパクトに表現できるオブジェクト型を定義しています.要素の型に制限があることを除けば,リストとまったく同じように振る舞います.C++ 標準ライブラリ内にある array クラスと似ています(要素の型を,文字,整数,または,浮動小数点数とした場合).array クラスと同様,オブジェクト生成時に要素の型を指定します( 1 文字の型コードを使用).ただし,array モジュールでは,リストと同じように,要素の追加・削除等を行えますが,array クラスでは,C/C++ における通常の配列と同様,宣言時に大きさが決まってしまいます.
- numpy.ndarray モジュールでは,C/C++ の配列と同様,メモリの連続領域上に確保されます.また,各要素の型はすべて同じで,かつ,各次元ごとの要素数が等しくなければなりません.このことによって,より高速な処理が可能になっています.
- 以下に示すのは,リスト,array モジュール(数値配列),及び,numpy.ndarray モジュールによる 1 次元配列の生成や処理の基本を示したプログラム例です.いずれの方法においても,問題なく,1 次元配列が生成されています.

- array モジュールでは,基本的な値(文字( bytes 型),整数,浮動小数点数)の配列をコンパクトに表現できるオブジェクト型を定義しています.要素の型に制限があることを除けば,リストとまったく同じように振る舞います.C++ 標準ライブラリ内にある array クラスと似ています(要素の型を,文字,整数,または,浮動小数点数とした場合).array クラスと同様,オブジェクト生成時に要素の型を指定します( 1 文字の型コードを使用).ただし,array モジュールでは,リストと同じように,要素の追加・削除等を行えますが,array クラスでは,C/C++ における通常の配列と同様,宣言時に大きさが決まってしまいます.
01 #****************************/ 02 #* 1 次元配列 */ 03 #* coded by Y.Suganuma */ 04 #****************************/ 05 # -*- coding: UTF-8 -*- 06 from array import * 07 import numpy as np 08 # リスト 09 print ("リスト") 10 a1 = [] 11 a2 = list() 12 print(" 空のリスト a1: " + str(a1) + ",a2: " + str(a2)) 13 14 a3 = [1, 2, 3] 15 print(" 角括弧とカンマの使用 a3: " + str(a3)) 16 17 a4 = list("abcd") 18 a5 = list(("a", "b", "c", "d")) 19 print(" list(iterable) の使用 a4: " + str(a4) + ",a5: " + str(a5)) 20 21 a6 = [x for x in "abcd"] 22 print(" リスト内包表記の使用 a6: " + str(a6)) 23 24 a6.append('e') 25 del a6[1:3] # a6[1],a6[2] を削除 26 print(" 追加と削除 a6: " + str(a6)) 27 # array モジュール 28 print("array モジュール") 29 print(" タイプコード " + typecodes) 30 b1 = array("i", [1, 2, 3]) 31 print(" b1: " + str(b1)) 32 b1.append(4) 33 b1.remove(2) # 値が 2 である要素を削除 34 print(" 追加と削除 b1: " + str(b1)) 35 # numpy.ndarray モジュール 36 print("numpy.ndarray モジュール") 37 c1 = np.array([1, 2, 3]) 38 print(" c1: " + str(c1)) 39 c2 = np.array([1.5, 2, 3]) # np.array([1, 2, 3]], np.float) と同じ 40 print(" c2: " + str(c2))- (出力)
リスト 空のリスト a1: [],a2: [] 角括弧とカンマの使用 a3: [1, 2, 3] list(iterable) の使用 a4: ['a', 'b', 'c', 'd'],a5: ['a', 'b', 'c', 'd'] リスト内包表記の使用 a6: ['a', 'b', 'c', 'd'] 追加と削除 a6: ['a', 'd', 'e'] array モジュール タイプコード bBuhHiIlLqQfd b1: array('i', [1, 2, 3]) 追加と削除 b1: array('i', [1, 3, 4]) numpy.ndarray モジュール c1: [1 2 3] c2: [ 1.5 2. 3. ]- 何人かの試験の点数を入力し,平均点以下の人数を求めるプログラムについて考えてみます.平均点以下の人数を求めるためには,全員のデータを入力し,平均値を計算した後,それを各人の点数と比較する必要があります.そのためには,入力した各人の点数をどこかに記憶しておく必要があります.そこで,配列が必要になってきます.
01 #****************************/ 02 #* 平均点以下の人数 */ 03 #* coded by Y.Suganuma */ 04 #****************************/ 05 # -*- coding: UTF-8 -*- 06 # データの入力 07 x = list() 08 n = int(input("人数は? ")) 09 for i1 in range(n) : 10 x.append(int(input(str(i1+1) + " 番目の人に点数は? "))) 11 """ 12 # 入力を終了したいときは,改行だけを入力 13 n = 0 14 a = input("1 番目の人に点数は? ") 15 while len(a) > 0 : 16 x.append(int(a)) 17 n += 1 18 a = input(str(n+1) + " 番目の人に点数は? ") 19 # 半角スペースで区切って 1 行で入力 20 a = input(" 各人に点数は? ").split() 21 n = len(a) 22 for i1 in range(n) : 23 x.append(int(a[i1])) 24 """ 25 # 平均点の計算 26 mean = 0.0 27 for i1 in range(n) : 28 mean += x[i1] 29 mean /= n 30 # 平均点以下の人数をカウント 31 ct = 0 32 for i1 in range(n) : 33 if x[i1] <= mean : 34 ct += 1 35 # 結果の出力 36 print("結果: " + str(ct) + " 人")- 07 行目~ 10 行目
- データを入力している部分です.人数 n を入力( 08 行目)した後,各人の点数を入力しています( 09 行目~ 10 行目).09 行目の for 文は,range 型によって,0 ~ (n-1) までの値が変数 i1 に順に代入され,n 回繰り返されます.この例では,リストを使用していますが,他の型を使用しても構いません.また,リストでは,要素の数をプログラム実行中に動的に変化させることができるため,人数を前もって入力せず,入力を終了したい時点で改行だけを入力する方法( 13 行目~ 18 行目),または,1 行に全てのデータを半角スペースで区切って入力する方法( 20 行目~ 23 行目)でも構いません.なお,C++ においても,vector クラス等を使用する,十分大きな配列を準備しておく,等の方法を使用すれば同じ方法で記述可能です.なお,15,21 行目の len(s) は,オブジェクト s の長さ(要素の数)を返す組み込み関数です.
- 26 行目~ 29 行目
- 平均点を計算しています.26 行目の初期設定を忘れないでください.
- 31 行目~ 34 行目
- 平均点以下の人数を数えています.平均点を求める場合と同様,31 行目の初期設定を忘れないでください.
- 07 行目~ 10 行目
- ここでは,C/C++ の配列と似たリスト型( list ),array モジュール(数値配列),及び,numpy.ndarray モジュールについて説明します.リストは,一般的に同種の項目の集まりを格納するために使われます.C++ における C++ 標準ライブラリ内の vector クラスと似ていますが,vector とは異なり,異なる型のオブジェクトを要素として持つことができます.しかし,誤りの原因となりやすく,避けた方が良いと思います.
- 多次元配列
- 以下に示すのは,リスト,array モジュール(数値配列),及び,numpy.ndarray モジュールによる 2 次元配列の生成やその性質を調べたプログラムです.15,18 行目( 28,31 行目,38,41 行目)において,2 次元配列の 1 行目及び 2 行目を変数 a2 及び a3(b2 及び b3,c2 及び c3)に代入しています.いずれの変数も,3 要素の 1 次元配列としてみなせますが,2 次元配列と独立した 1 次元配列ではありません.C++ 風に言えば,2 次元配列における各行のアドレスを各変数に代入しているとみなせます.従って,2 次元配列の各行と対応する各変数は同じ場所を指していることになります.そこで,1 次元配列の値を変更すれば,出力結果からも明らかなように,対応する 2 次元配列の値も変化します(逆も同様).numpy.ndarray モジュールの場合,連続した領域に確保されるため,38 行目の c2 の要素数は,C/C++ のように,6 であっても良さそうに思えますが,そうはなっていません.
01 #****************************/ 02 #* 2 次元配列 */ 03 #* coded by Y.Suganuma */ 04 #****************************/ 05 # -*- coding: UTF-8 -*- 06 from array import * 07 import numpy as np 08 # リスト 09 print ("リスト") 10 #a1 = [[], []] 11 #a1[0] = [1, 2, 3] 12 #a1[1] = [4, 5, 6] 13 a1 = [[1, 2, 3], [4, 5, 6]] # 上の 3 行でも可 14 a1[1][0] = 10; 15 a2 = a1[0] # 要素数 3 の 1 次元配列 16 a2[1] = 100 17 #a2[3] = 1000 # error(index out of range) 18 a3 = a1[1] # 要素数 3 の 1 次元配列 19 print(" 2 次元配列 a1: " + str(a1)) 20 print(" 1 次元配列 a2: " + str(a2) + ",a3: " + str(a3)) 21 # array モジュール 22 print("array モジュール") 23 #b1 = [array("i", []), array("i", [])] 24 #b1[0] = [1, 2, 3] 25 #b1[1] = [4, 5, 6] 26 b1 = [array("i", [1, 2, 3]), array("i", [4, 5, 6])] # 上の 3 行でも可 27 b1[1][0] = 10; 28 b2 = b1[0] # 要素数 3 の 1 次元配列 29 b2[1] = 100 30 #b2[3] = 1000 # error(index out of range) 31 b3 = b1[1] # 要素数 3 の 1 次元配列 32 print(" 2 次元配列 b1: " + str(b1)) 33 print(" 1 次元配列 b2: " + str(b2) + ",b3: " + str(b3)) 34 # numpy.ndarray モジュール 35 print("numpy.ndarray モジュール") 36 c1 = np.array([[1, 2, 3], [4, 5, 6]]) 37 c1[1][0] = 10; 38 c2 = c1[0] # 要素数 3 の 1 次元配列 39 c2[1] = 100 40 #c2[3] = 1000 # error(index out of range) 41 c3 = c1[1] # 要素数 3 の 1 次元配列 42 print("2 次元配列 c1: ") 43 print(str(c1)) 44 print("1 次元配列 c2: " + str(c2) + ", c3: " + str(c3))- (出力)
リスト 2 次元配列 a1: [[1, 100, 3], [10, 5, 6]] 1 次元配列 a2: [1, 100, 3],a3: [10, 5, 6] array モジュール 2 次元配列 b1: [array('i', [1, 100, 3]), array('i', [10, 5, 6])] 1 次元配列 b2: array('i', [1, 100, 3]),b3: array('i', [10, 5, 6]) numpy.ndarray モジュール 2 次元配列 c1: [[ 1 100 3] [ 10 5 6]] 1 次元配列 c2: [ 1 100 3], c3: [10 5 6]- 複数のクラスに対して試験を行ったとします.全体の平均を求めた後,各クラス毎に平均点以下の人数を出力するプログラムです.どのような方法でも記述可能ですが,ここでは,プログラム例 4.1 と同様,リストを使い,各行にクラス全員の点を半角で区切って入力し,入力が終了した時点で改行だけを入力するといった方法で記述してみます.いずれにしろ,全員の平均点を求めた後でないと,平均点以下の人数を計算できませんので,2 次元配列が必要になってきます.例えば,2 クラス存在し,クラス1 の人数が 3 人,クラス2 の人数が 2 人の場合は,メッセージに対して以下に示すような順で入力します.3 行目は改行だけです.点数は適当に変えてください.
10 20 30\n 40 50\n \n
01 #****************************/ 02 #* 平均点以下の人数 */ 03 #* coded by Y.Suganuma */ 04 #****************************/ 05 # -*- coding: UTF-8 -*- 06 # データの入力 07 x = list() # 各人の点数 08 n = 0 # クラスの数 09 m = list() # 各クラスの人数 10 mm = 0; # 全体の人数 11 mean = 0; # 全体の平均 12 13 a = input("1 番目のクラスにおける各人の点数は?(半角スペースで区切る) ").split() 14 while len(a) > 0 : 15 m.append(len(a)) # クラスの人数 16 x.append(list()) # 2 次元配列の生成 17 mm += m[n] # 全体の人数 18 for i1 in range(m[n]) : 19 x[n].append(int(a[i1])) 20 mean += x[n][i1] # 全体の平均 21 n += 1 22 a = input(str(n+1) + " 番目のクラスにおける各人の点数は? ").split() 23 # 平均点の計算 24 mean /= mm 25 # 平均点以下の人数のカウントと出力 26 for i1 in range(n) : 27 ct = 0 28 for i2 in range(m[i1]) : 29 if x[i1][i2] <= mean : 30 ct += 1 31 print("クラス" + str(i1+1) + " における平均点以下の人数: " + str(ct) + " 人")- 07,16 行目
- これらによって,2 次元配列を実現しています.
- 09 行目
- 各クラスの人数を 28 行目で必要としますので,リストを使用して保存しています.
- 27 行目
- 変数 ct の初期設定を,この位置でしなければならない点に注意してください.
- 07,16 行目
- 以下に示すのは,リスト,array モジュール(数値配列),及び,numpy.ndarray モジュールによる 2 次元配列の生成やその性質を調べたプログラムです.15,18 行目( 28,31 行目,38,41 行目)において,2 次元配列の 1 行目及び 2 行目を変数 a2 及び a3(b2 及び b3,c2 及び c3)に代入しています.いずれの変数も,3 要素の 1 次元配列としてみなせますが,2 次元配列と独立した 1 次元配列ではありません.C++ 風に言えば,2 次元配列における各行のアドレスを各変数に代入しているとみなせます.従って,2 次元配列の各行と対応する各変数は同じ場所を指していることになります.そこで,1 次元配列の値を変更すれば,出力結果からも明らかなように,対応する 2 次元配列の値も変化します(逆も同様).numpy.ndarray モジュールの場合,連続した領域に確保されるため,38 行目の c2 の要素数は,C/C++ のように,6 であっても良さそうに思えますが,そうはなっていません.
- 連想配列
- キーとそれに結びついた値のペアで構成される配列を連想配列と呼びます.Python におけるマッピング型(辞書型,mapping 型)は.ハッシュ可能な値であるキーと任意のオブジェクトのペアから構成されます.キーは,ほぼ,任意の値ですが,ハッシュ可能でない値,つまり,リストや辞書など変更可能な型はキーとして使用できません.C++ の C++ 標準ライブラリ内の map クラスや unordered_map クラスと似ていますが,map や unordered_map とは異なり,異なる型のオブジェクトを要素として持つことができます.以下に示すのは,辞書型の基本的な使用法です.
#****************************/ #* 連想配列 */ #* coded by Y.Suganuma */ #****************************/ # -*- coding: UTF-8 -*- # 生成 #x = {"aaa" : 10, "ddd" : 20, "ccc" : 30} x = dict(aaa = 10, ddd = 20, ccc = 30) print(x) # 参照 print(" キー ccc に対する値: " + str(x['ccc'])) # 追加 x['bbb'] = 1 print(" キー bbb に対する値 1 を追加: " + str(x)) # 削除 del x['aaa'] print(" キー aaa に対する値を削除: " + str(x))- (出力)
{'ccc': 30, 'aaa': 10, 'ddd': 20} キー ccc に対する値: 30 キー bbb に対する値 1 を追加: {'bbb': 1, 'ccc': 30, 'aaa': 10, 'ddd': 20} キー aaa に対する値を削除: {'bbb': 1, 'ccc': 30, 'ddd': 20}
- キーとそれに結びついた値のペアで構成される配列を連想配列と呼びます.Python におけるマッピング型(辞書型,mapping 型)は.ハッシュ可能な値であるキーと任意のオブジェクトのペアから構成されます.キーは,ほぼ,任意の値ですが,ハッシュ可能でない値,つまり,リストや辞書など変更可能な型はキーとして使用できません.C++ の C++ 標準ライブラリ内の map クラスや unordered_map クラスと似ていますが,map や unordered_map とは異なり,異なる型のオブジェクトを要素として持つことができます.以下に示すのは,辞書型の基本的な使用法です.
- 代入と複製
- 代入文に対する説明の箇所で,整数型や浮動小数点型の代入について考えてみました.ここでは,リストのオブジェクトを代入する場合について考えてみます.下に示すプログラムの 02 ~ 03 行目,または,04 行目,いずれの方法で初期設定(代入)を行っても,05 行目のように y の要素を変更した場合,変化するのは y の要素だけです.つまり,値は同じでも,x と y は,全く別のオブジェクトになります.この関係のイメージは,下図のようになります.
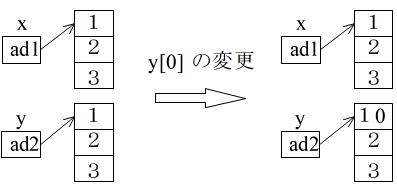
01 # -*- coding: UTF-8 -*- 02 x = [1, 2, 3] 03 y = [1, 2, 3] 04 # x, y = [1, 2, 3], [1, 2, 3] 05 y[0] = 10 06 print(x, y) # [1, 2, 3] [10, 2, 3]
- しかし,下に示すプログラムの 02 ~ 03 行目,または,04 行目,いずれか方法で代入を行った場合,05 行目のように y の要素を変更した場合,対応する x の要素も変化します.これは,これらの方法で代入を実行した場合,オブジェクトに対する参照(アドレス)がコピーされ,同じオブジェクトを指すことになっているからです.C/C++ 風に言えば,同じオブジェクトに対するポインタがコピーされ代入されたことになります.この関係のイメージは,下図のようになります.

01 # -*- coding: UTF-8 -*- 02 x = [1, 2, 3] 03 y = x 04 # x = y = [1, 2, 3] 05 y[0] = 10 06 print(x, y) # [10, 2, 3] [10, 2, 3]
- これを避けるためには,04 行目に示すように,copy メソッドを使用し,x が参照しているオブジェクトのコピー(浅いコピー)を新たに生成し,それに対する参照を y に代入することです.04 行目の処理は,copy モジュールを使用した 02,05 行目の処理と同等です.この処理によって,最初に示した代入文と同じような状態になり,y の値を変更しても x の値は変化しません.
01 # -*- coding: UTF-8 -*- 02 # import copy 03 x = [1, 2, 3] 04 y = x.copy() # y = x[:] と同じ 05 # y = copy.copy(x) 06 y[0] = 10 07 print(x, y) # [1, 2, 3] [10, 2, 3]
- しかし,浅いコピーにおいては,オブジェクト内に存在するオブジェクトに対しては,その参照(下図における ad11 と ad12 の部分,アドレス)をコピーしているだけですので,以下に示す 2 次元のリスト(配列)のような場合は,上と同じ問題が発生します( y[0][0] の変更で,x[0][0] も変化する).
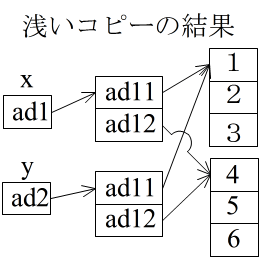
01 # -*- coding: UTF-8 -*- 02 x = [[1, 2, 3], [4, 5, 6]] 03 y = x.copy() 04 y[0][0] = 10 05 print(x,y) # [[10, 2, 3], [4, 5, 6]] [[10, 2, 3], [4, 5, 6]]
- 1 次元のリスト(配列)の場合であっても,各要素がクラスのオブジェクトである場合は,同じような問題が発生します.クラスに関しては,後ほど説明しますが,簡単に言えば,クラスとはデータ(変数)とそれを処理する関数(メソッド)の集まりです.例えば,以下に示す例において,04 行目~ 06 行目がクラス Example の定義であり( 1 つの変数だけを持ったクラス),
Example(n)
- のような記述により,クラス内の変数の値が n である Example クラスのオブジェクトが生成されます.従って,08 行目の x は,3 つの Example クラスのオブジェクトを要素とするリスト(配列)になります.
- クラスのオブジェクトを要素とした場合,各要素にはオブジェクトに対するアドレスが記憶されています.浅いコピーは,x の各要素の値(アドレス,参照)をコピーして新しい配列 y を生成します.その際,各要素に記憶されているアドレスが指すオブジェクト自身はコピーされません.そのため,x と y の各要素は,同じオブジェクトを指すことになります.y[1] のように,新しいオブジェクト(のアドレス)を代入した場合( 10 行目),x はその影響を受けませんが,y[2] のような変更( 11 行目)は,x[2] と y[2] が同じオブジェクトを指しているため,x[2] の値も変化します.
01 # -*- coding: UTF-8 -*- 02 import copy 03 04 class Example : 05 def __init__(self, x) : 06 self.x = x 07 08 x = [Example(1), Example(2), Example(3)] 09 y = copy.copy(x) 10 y[1] = Example(4) 11 y[2].x = 5 12 print(x[0].x, x[1].x, x[2].x) # 1 2 5 13 print(y[0].x, y[1].x, y[2].x) # 1 4 5
- 以上の問題を避けるためには,オブジェクト内に存在するオブジェクトに対しても,浅いコピーと同じ処理を行ってやることです.それが,深いコピーです.下の図は,2 次元配列に対するイメージですが,その下に示すプログラムは,上で述べたクラスのオブジェクトを要素とするリストに対する問題を,深いコピーで解決した結果です.
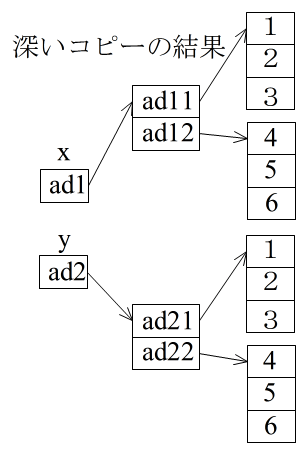
01 # -*- coding: UTF-8 -*- 02 import copy 03 04 class Example : 05 def __init__(self, x) : 06 self.x = x 07 08 x = [[1, 2, 3], [4, 5, 6]] 09 y = copy.deepcopy(x) 10 y[0][0] = 10 11 print(x, y) # [[1, 2, 3], [4, 5, 6]] [[10, 2, 3], [4, 5, 6]] 12 13 x = [Example(1), Example(2), Example(3)] 14 y = copy.deepcopy(x) 15 y[1] = Example(4) 16 y[2].x = 5 17 print(x[0].x, x[1].x, x[2].x) # 1 2 3 18 print(y[0].x, y[1].x, y[2].x) # 1 4 5
- 関数とその性質
- 定義とデフォルト引数
- ここでは,関数の定義方法について,例を使用しながら説明していきます.まず,最初は,最も基本的な関数です.3 つのデータを受け取り,それらの和を返す関数です.以下に示すような内容のファイル test.py を作成し,Window のコマンドプロンプト上で,
py -3 test.py [data] # [ ] 内はオプション
- と入力すれば結果が得られるはずです.関数は,本来,独立したプログラムです.しかし,関数を test.py 内に記述すると,関数内からその外側の(メインプログラム内の)変数を参照できてしまいます.そのため,関数は,別のファイル function.py 内に記述し,import 文で組み込んでいます( 08 行目).
01 # -*- coding: UTF-8 -*- 02 def func(s1, s2 = 20, s3 = 30) : 03 """example of function""" 04 s = s1 + s2 + s3 05 s1 = 100 06 return s ---------------------------------- 07 # -*- coding: UTF-8 -*- 08 from function import func 09 import sys 10 print(func.__doc__) 11 p1 = 10 12 print("sum = ", func(p1)) # func(s1 = 10) or func(10) でも可 13 print("p1 = ", p1) 14 print("sum = ", func(p1, s2 = 50)) # func(10, 50) でも可 15 print(len(sys.argv), sys.argv[0]) 16 #print(len(sys.argv), sys.argv[0], sys.argv[1]) # オプションを付加した場合- 02 行目
- 関数の定義は,キーワード def で始まり,関数名 func の後ろの括弧の中に仮引数のリスト(この例では,s1,s2,s3 )が並びます.これらの仮引数は,関数を呼び出す際にも,実引数として,同じ位置,同じ順番で記述する必要がありますので,位置指定引数と呼ばれます.なお,変数名は異なっても構いません( 12,14 行目において,p1 が s1 に対応).
- 引数に対しては,それらが省略されたときの値,つまり,デフォルト値を設定することができます(デフォルト引数,C++ にも,同様の機能).この例では,引数 s2 及び s3 に対して設定しています.その結果,12 行目では s2 及び s3 を省略,また,14 行目では s3 を省略していますが,正しく計算されています.なお,最初または中間にある位置指定引数,例えば,s1 または s2 に対してだけデフォルト値を設定することはできません.なお,Python には,関数名の多重定義機能はありません.
- 引数に対しては,それらが省略されたときの値,つまり,デフォルト値を設定することができます(デフォルト引数,C++ にも,同様の機能).この例では,引数 s2 及び s3 に対して設定しています.その結果,12 行目では s2 及び s3 を省略,また,14 行目では s3 を省略していますが,正しく計算されています.なお,最初または中間にある位置指定引数,例えば,s1 または s2 に対してだけデフォルト値を設定することはできません.なお,Python には,関数名の多重定義機能はありません.
- 03 行目
- 関数の本体を記述する文の最初の行は文字列リテラルにすることもできます.その場合,この文字列は関数のドキュメンテーション文字列と呼ばれ,変数 __doc__ によって参照できます( 10 行目参照).
- 05 行目
- 先に述べたように,関数は,本来,独立したプログラムです.しかし,関数における処理をする際に何らかの情報が欲しい場合があります.その情報を引き渡す手段が引数です(外部からの情報を必要としない場合は引数を記述しなくて良い).基本的に,実引数の値がコピーされて,仮引数に渡されます.従って,実引数と仮引数は全く独立した変数(値)ですので,この例の場合,変数 s1 の値を変更しても,変数 p1 の値は変化しません( 13 行目に対する出力結果参照).この点は,実引数と仮引数の変数名が同じである場合も同様です.
- 06 行目
- return 文は,関数を呼び出した先に結果を返すための文です.この例の場合は,s1,s2,s3 の和が戻され,12,14 行目の結果となります.なお,結果を戻さない場合は必要ありません.
- 08 行目
- function モジュール内にある関数 func を取り込んでいます.
- 09 行目
- 15,16 行目のために必要です.
- 12,14 行目
- Python では,引数の渡し方として,「 s1 = 10 」「 s2 = 50 」のような形をとることができますが,関数は独立したプログラムであるべきなのに,関数の仮引数の名前を使用するといった仕様はいかがなものでしょうか.
- 15,16 行目
- 変数 sys.argv には,C/C++ 風に言えば,main 関数の引数に対する情報が入っています.プログラムを実行する際,何らかの付加的情報を必要とする場合があります.そのようなとき,上に示した使用方法における [ ] 内の data のように,その情報を記述可能です.これらの情報は,変数 sys.argv に入れられて渡されます.オプションを記述しなかった場合( 15 行目)は,実行したファイル名だけが入っています.test.py の実行時に,
py -3 test.py data
- のように,data というオプションを付加すると,変数 sys.argv のサイズは 2 となり,そのオプションも渡されます( 16 行目と一番最後の出力).
- 02 行目
- (出力)
example of function sum = 60 p1 = 10 sum = 90 1 test.py #2 test.py data
- 次の例では,引数にリストを用い,引数 lt のデフォルト値が [] (空のリスト)に設定されています.このプログラムを実行すると,次のような結果が得られます.明らかに奇異に感じると思います.これは,リストに対してデフォルトを設定した場合,それが評価されるのは最初に関数が呼ばれたときだけだからです.
[1] [1, 2] [1, 2, 3]
# -*- coding: UTF-8 -*- def func(a, lt = []) : lt.append(a) return lt ---------------------------------- # -*- coding: UTF-8 -*- from function import func print(func(1)) print(func(2)) print(func(3))
- しかし,次の例を見てください.上と全く同じようなプログラムです.異なるのは,引数がリストではなく整数型になっているだけです.この場合は,期待したように,常に,引数 a の値に sum のデフォルト値 0 が加えられた結果が出力されます.このように,変数の型によって異なる行動を行うような方法は使用すべきではありません.もちろん,Python の仕様も変更すべきです.少なくとも,上のプログラムにおいては,デフォルト値を設定すべきではありません.
# -*- coding: UTF-8 -*- def func(a, sum = 0) : sum += a return sum ---------------------------------- # -*- coding: UTF-8 -*- from function import func print(func(1)) print(func(2)) print(func(3))
- 様々な引数
- 上で述べたように,引数として渡した変数の値を関数内で変化させても,その影響は関数を呼んだ側には現れません.しかし,場合によっては,そのようなことをしたい場合があります.C/C++ には,アドレス渡し,参照渡しなどの方法がありますが,Python では,どのようにしたら良いのでしょうか.
- C/C++ において配列を引数とするとそのアドレスが渡るため,関数内で配列の要素の値を変更すると,関数を呼んだ側においても対応する値が変化します.Python においても,デフォルト引数の例で示したプログラム例からも明らかなように,リストを引数とすると,関数内での変更が関数を呼んだ側にも反映されます.次に示すプログラム例においては,整数型( int 型),浮動小数点数型( float 型),複素数型( complex 型),リスト型,及び,numpy.ndarray モジュールによる配列を引数としています.関数内では,いずれの引数に対しても変更を加えています.関数内( 09 行目),及び,関数を呼んだ後( 19 行目)の出力結果は,
a: 10 b: 3.13 c: (5+6j) x:[10, 2, 3] y:[ 1 10 3] a: 1 b: 1.5 c: (1+2j) x:[10, 2, 3] y:[ 1 10 3]
- のようになります.関数内では全ての変数の値が変化しているのに,関数を呼んだ後のメインプログラム内では,整数型,浮動小数点数型,及び,複素数型の基本型変数は変化していませんが,他の二つの変数は,関数内で修正したように変化しています.この点は,後に述べるクラスのオブジェクトを引数にした場合も同様です.
01 # -*- coding: UTF-8 -*- 02 import numpy as np 03 def func(a, b, c, x, y) : 04 a = 10 05 b = 3.13 06 c = complex(5, 6) 07 x[0] = a 08 y[1] = a 09 print("a: " + str(a) + " b: " + str(b) + " c: " + str(c) + " x:" + str(x) + " y:" + str(y)) ---------------------------------- 10 # -*- coding: UTF-8 -*- 11 import numpy as np 12 from function import func 13 a = 1 14 b = 1.5 15 c = complex(1, 2) 16 x = [1, 2, 3] 17 y = np.array([1, 2, 3]) 18 func(a, b, c, x, y) 19 print("a: " + str(a) + " b: " + str(b) + " c: " + str(c) + " x:" + str(x) + " y:" + str(y))
- 上で述べたように,引数として渡した変数の値を関数内で変化させても,その影響は関数を呼んだ側には現れません.しかし,場合によっては,そのようなことをしたい場合があります.C/C++ には,アドレス渡し,参照渡しなどの方法がありますが,Python では,どのようにしたら良いのでしょうか.
- 引数と関数名
- Python においては,関数も一つのオブジェクトです.従って,関数(のアドレス)を他の変数に代入すれば,その変数は関数と同じように使用できます( 14,15 行目).また,関数(のアドレス)を関数の引数としても使用可能です( 16,17 行目).
01 # -*- coding: UTF-8 -*- 02 def add(s1, s2) : 03 s = s1 + s2 04 return s 05 def sub(s1, s2) : 06 s = s1 - s2 07 return s 08 def add_sub(fun, s1, s2) : 09 s = fun(s1, s2) 10 return s ---------------------------------- 11 # -*- coding: UTF-8 -*- 12 from function import add, sub, add_sub 13 print(add(2, 3)) # 5 14 kasan = add 15 print(kasan(2, 3)) # 5 16 print(add_sub(add, 2, 3)) # 5 17 print(add_sub(sub, 2, 3)) # -1
- 可変個の引数
- 可変個の引数を受け取る関数を定義することもできます.以下の例においては,2 個の引数を利用しています.送られてきた引数は,例に見るように,タプルとして処理されます.*var の後ろにも引数を設定することができますが,key = value という形をとるキーワード引数だけが許されます.また,位置指定引数に対するデフォルト引数は使用できません(引数を省略しなければ,問題ない).
# -*- coding: UTF-8 -*- def func(*var, p) : print(var, p) # (10, 20) 30 を出力 ---------------------------------- # -*- coding: UTF-8 -*- from function import func func(10, 20, p = 30) # func(10, 20, 30) はエラー
- 上と同様,可変個のキーワード引数を持つ関数を定義することも可能です.以下の例( 2 つのキーワード引数を使用)に見るように,key は辞書型データとして処理されます.
# -*- coding: UTF-8 -*- def func(**key) : print(key) # {'key1': 10, 'key2': 20} を出力 ---------------------------------- # -*- coding: UTF-8 -*- from function import func func(key1 = 10, key2 = 20)- 位置指定引数,可変個の引数,及び,可変個のキーワード引数すべてを持つ関数を定義することも可能です.ただし,引数の順番は,下に示す例のように決まっています.
# -*- coding: UTF-8 -*- def func(p1, p2, *var, **key) : print(p1, p2) # 1 5 を出力 print(var) # (100, 200) を出力 print(key) # {'key1': -1, 'key2': -2} を出力 ---------------------------------- # -*- coding: UTF-8 -*- from function import func func(1, 5, 100, 200, key1 = -1, key2 = -2)- なぜ,このような仕様が必要なのでしょうか.プログラムを分かり難くするだけではないかと思います.下に示すプログラム例のように,タプル型や辞書型のオブジェクトを引数に設定すれば済む内容ではないでしょうか.そのようにすれば,デフォルト引数を除き,引数の順番に制限を付ける必要もありません(下のプログラム例では,引数の順番を,意図的に変更しています).
def func(p1, key, var, p2 = 5) : print(p1, p2) # 1 5 を出力 print(var) # (100, 200) を出力 print(key) # {'key1': -1, 'key2': -2} を出力 ---------------------------------- # -*- coding: UTF-8 -*- from function import func var_m = (100, 200) # タプル型 key_m = {'key1': -1, 'key2': -2} # 辞書型 func(1, key_m, var_m) # 4 つ目の引数は省略
- ローカル変数とグローバル変数
- 一般に,関数内で定義された変数は,関数内だけで有効です.しかし,場合によっては,複数の関数内で特定の変数を参照したい場合があります.この様な変数をグローバル変数( global variable ),また,関数内だけで有効な変数をローカル変数( local variable )と呼びます.基本的に,関数外で変数を定義すれば,その変数はグローバル変数となり,関数内からもその変数を参照・変更可能となります.下の例における 13 行目の変数 a が相当します.
- ただし,関数内においてグローバル変数を修正する場合は十分注意する必要があります.04 行目が存在しなければ,03,05 行目は,グローバル変数 a の値を出力します.しかし,04 行目によって,グローバル変数と同じ名前の新しいローカル変数が定義されたとみなされます.従って,03 行目は,未定義の変数 a の出力とみなされエラーになります.
- 関数 func1 のような形で,関数内でグローバル変数の値を修正しようとすれば,新しいローカル変数の定義とみなされ,グローバル変数の値は変更されません.関数内においてグロ-バル変数の値を修正するためには,08 行目のような宣言が必要です.もしこの宣言がなければ,a は新しいローカル変数とみなされ,関数 func1 の場合と同様,09 行目でエラーになってしまいます.
- ただし,関数内においてグローバル変数を修正する場合は十分注意する必要があります.04 行目が存在しなければ,03,05 行目は,グローバル変数 a の値を出力します.しかし,04 行目によって,グローバル変数と同じ名前の新しいローカル変数が定義されたとみなされます.従って,03 行目は,未定義の変数 a の出力とみなされエラーになります.
01 # -*- coding: UTF-8 -*- 02 def func1() : 03 # print(str(a) + " in func1") エラー 04 a = 20 05 print(str(a) + " in func1") 06 07 def func2() : 08 global a # 記述しないとエラー 09 print(str(a) + " in func2") 10 a *= 10 11 print(str(a) + " in func2") 12 13 a = 10 14 print(a) 15 func1() 16 print(a) 17 func2() 18 print(a)
- 上のプログラムを実行すると以下のような出力が得られます.
10 20 in func1 10 10 in func2 100 in func2 100
- このように分かり難い変数の有効範囲を許して良いのでしょうか.「関数から,引数を利用する以外,外部の変数を一切参照できない.どうしても必要ならば,メインプログラム内でグローバル宣言を行い,その変数をどこからでも参照可能にする.」といった仕様ではだめでしょうか?
- 一般に,関数内で定義された変数は,関数内だけで有効です.しかし,場合によっては,複数の関数内で特定の変数を参照したい場合があります.この様な変数をグローバル変数( global variable ),また,関数内だけで有効な変数をローカル変数( local variable )と呼びます.基本的に,関数外で変数を定義すれば,その変数はグローバル変数となり,関数内からもその変数を参照・変更可能となります.下の例における 13 行目の変数 a が相当します.
- 定義とデフォルト引数
- ジェネレータ関数
- ジェネレータは,イテレータ(順番にオブジェクトの要素を取り出すための演算子)を作成するための簡潔なツールです.簡単にジェネレータを生成したいときは,ジェネレータ式を利用できます.ジェネレータ式は,丸括弧を使用し,以下のような形になります.なお,引数が一つである関数の引数とする場合は,丸括弧を省略できます.C/C++ には,直接対応するような機能はありませんが,簡単に記述することができます.
(式 for 式 in イテラブルオブジェクト) # for を多重に使用しても良い
- これだけでは分かり難いかと思いますので,いくつかの例を挙げておきます.まず,最初は,0 の 2 乗から 9 の 2 乗までを取り出すためのジェネレータ式です.ここで,next() は,イテレータの次の要素を取得するための組み込み関数です.
>>> g = (pow(x, 2) for x in range(10)) >>> list(g) [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> next(g) 0 >>> next(g) 1 >>> next(g) 4 ・・・・・ >>> list(g) # 要素を取り出した後は空 [] >>> sum(pow(x, 2) for x in range(10)) # 2 乗の和 285
- 次は,3 次元ベクトル x と y の内積の例です.ここで,zip() は,複数のイテラブル( iterable,構成要素を一度に一つずつ返すことができるオブジェクト)から,それぞれの要素を集めたイテレータを作成するための組み込み関数です.
>>> x = [1, 2, 3] >>> y = [4, 5, 6] >>> sum(x1 * y1 for x1, y1 in zip(x, y)) 32
- 以下に示す例における page は,1 行毎のデータが入っているリストです.この例では,page 内に含まれる単語を集め,集合型のデータ unique_words を生成しています.集合型では,同じデータは無視されますので,unique_words は,page に含まれる異なる単語の集合となります.
>>> page = ["aaa bbb ccc aaa", "aaa bbb ccc", "bbb aaa aaa"] >>> unique_words = set(word for line in page for word in line.split()) >>> unique_words {'aaa', 'ccc', 'bbb'}- 今まで述べた Python におけるジェネレータ関数による記述は分かりやすいでしょうか.Python においては,if 文や for 文において,必ず字下げすることを義務づけています.その目的の一つは,プログラムの分かりやすさだと思います.しかし,上に示したジェネレータ関数による記述はこの点に反しています.全体的に,Python は,記述の容易さに重点を置くあまり,分りやすさを犠牲にしているのではないでしょうか.プログラムにとって最も重要なことは,「読みやすく,理解しやすい」ことだと思います.是非,この点に力を入れてコンパイラの設計を行って欲しいと思います.
- ジェネレータ関数は,通常の関数のように書かれますが,何らかのデータを返すときには yield 文が使われます.ジェネレータ関数が開始されると,最初の yield 式まで処理して一時停止し,呼び出し元へ yield 式で与えた値を返します.ここで言う一時停止とは,ローカル変数の束縛,命令ポインタや内部の評価スタック,そして例外処理を含むすべてのローカル状態が保持されることを意味します.再度,ジェネレータ関数が呼び出されて実行を再開した時,ジェネレータ関数は,yield 式がただの外部呼び出しであったかのように処理を継続します.以下に示す例では,指定した位置から,データを逆方向にイテレートしています.
>>> def reverse(data, start) : ... for index in range(start, -1, -1) : ... yield data[index] ... >>> data1 = "abcde" >>> n = reverse(data1, 2) >>> next(n) 'c' >>> next(n) 'b' >>> for char in reverse(data1, 2) : ... print(char) ... c b a
- クラスの定義
- 大きなプログラムの場合,その部分的な機能の修正のため,他の機能に対応する部分も理解し,かつ,場合によってはそれらの一部も修正するなど,プログラム全体にわたって理解し,かつ,修正をしなければならないとしたら,大変なことになります.そこで,プログラムのモジュール化が非常に重要になります.各機能毎にモジュール化し,
- そのモジュール内部における詳細な処理を知らなくても,適当なインターフェースを介してデータを渡し,また,インターフェースを介して希望する結果が得られる.
- モジュールとのやりとりは,インターフェースを介してのみ可能であり,モジュールの外部から,そのモジュール内の処理を直接コントロールすることはできないし,また,コントロールする必要がない.
- そのモジュール内部における詳細な処理を知らなくても,適当なインターフェースを介してデータを渡し,また,インターフェースを介して希望する結果が得られる.
- ようにしておけば,各モジュールは他のモジュールの影響を受けにくくなり,対応する機能の修正はそのモジュールの修正だけで済みます.ある意味では,各モジュールをブラックボックス化するわけです.
- このモジュール化の一つの実現方法が関数です.引数を付けて関数を呼ぶというインターフェースによって,関数内部の処理の詳細を知らなくても結果を得ることができます.また,ローカル変数の存在により,関数外部から関数内部の処理を直接コントロールすることは基本的に不可能です.
- このように,関数もモジュール化の強力な手段ですが,それは,アルゴリズムに重点を置いたブラックボックス化です.しかし,場合によっては,データに重点を置いたブラックボックス化が必要になる場合があります.それが,まさに,クラスです.クラスでは,データとそれを扱う関数を一つにまとめ,特定のインターフェース(クラス内で宣言された関数など)を介してのみ,その内部にアクセスできるようにすることが可能です.このような処理をデータの抽象化と呼び,抽象データ型の変数(つまり,あるクラス型として宣言された変数)をインスタンス(オブジェクト,データとそれを操作する手続き-関数-をひとまとめにしたもの)と呼びます.
- クラスは,その定義の方法から見て,ユーザーが新たに定義する変数の型と考えても良いと思います.新しい変数の型を定義すれば,その型の操作方法も必要になります.例えば,実部と虚部という 2 つのデータからなる複素数に対応する型をクラスによって定義したとします.すると,単純な加算ですら,既存の方法,つまり,int 型や float 型と同じような方法を使用することができません.従って,定義した変数の加算をどのようにして実行するかについても定義してやる必要が出てきます.そこで,クラスの定義には,単にデータだけでなく,そのデータを取り扱う方法を記述した関数が必要になってくるわけです.
- C++ の用語で言えば,通常のクラス( class )のメンバー(変数及び関数)は public であり,どこからでも参照可能です.メンバー関数(クラス内で定義された関数であり,メソッドと呼ぶ)はすべて仮想関数です.メソッドの宣言では,生成されたインスタンス自身を表す第一引数 self を明示しなければなりません.この引数は,メソッド呼び出しの際に暗黙の引数として渡されます.一般的に,「 self.var 」の形でメソッドの内側で定義される変数 var は,インスタンス変数と呼ばれ,各インスタンス固有の値を持つことが可能です.また,メソッドの外側で宣言され,かつ,self がつかないクラス変数は,そのクラスのすべてのインスタンスで同じ値を持ちます.
- インスタンス変数,C++ で言えばメンバー変数に,必ず self を付けさせるという仕様はいかがなものでしょうか.確かに,インスタンス変数を明確にし,誤ったローカル変数の使用を防ぐという意味では良いかもしれません.しかし,self が付加されるために,式が長くなり,見にくくなるという欠点があります.
- このモジュール化の一つの実現方法が関数です.引数を付けて関数を呼ぶというインターフェースによって,関数内部の処理の詳細を知らなくても結果を得ることができます.また,ローカル変数の存在により,関数外部から関数内部の処理を直接コントロールすることは基本的に不可能です.
01 # -*- coding: UTF-8 -*- 02 class Example : 03 """A simple example of class""" # クラスの説明 04 c_var = 12345 # クラス変数 05 def func(self, a) : # def __init__(self, a) : 06 self.i_var = a # インスタンス変数 ---------------------------------- 07 # -*- coding: UTF-8 -*- 08 from function import Example 09 print(Example.__doc__) # クラスの説明の表示 10 x = Example() # Example クラスのインスタンス(オブジェクト)の生成 11 x.func(10) # Example.func(x, 10) と等価 12 y = Example() 13 y.func(20) 14 z = Example() 15 z.func(30) 16 print("最初の状態 x,y,z") 17 print(Example.c_var, x.c_var, x.i_var) 18 print(Example.c_var, y.c_var, y.i_var) 19 print(Example.c_var, z.c_var, z.i_var) 20 print("***w に x を代入***") 21 w = x 22 print("w の値変更 x,y,z,w") 23 w.c_var = 100 24 w.i_var = 40 25 print(Example.c_var, x.c_var, x.i_var) 26 print(Example.c_var, y.c_var, y.i_var) 27 print(Example.c_var, z.c_var, z.i_var) 28 print(Example.c_var, w.c_var, w.i_var) 29 print("x の値変更 x,y,z,w") 30 xf = x.func # 関数に対するポインタ,普通の関数でもOK 31 xf(50) 32 x.c_var = 1000 33 print(Example.c_var, x.c_var, x.i_var) 34 print(Example.c_var, y.c_var, y.i_var) 35 print(Example.c_var, z.c_var, z.i_var) 36 print(Example.c_var, w.c_var, w.i_var) 37 print("クラス変数値の変更 x,y,z,w") 38 Example.c_var = 123 39 print(Example.c_var, x.c_var, x.i_var) 40 print(Example.c_var, y.c_var, y.i_var) 41 print(Example.c_var, z.c_var, z.i_var) 42 print(Example.c_var, w.c_var, w.i_var)- 02 行目~ 06 行目
- クラス Example の定義です.クラス変数 c_var( 04 行目),インスタンス変数 i_var( 06 行目),及び,メソッド func( 05 行目~ 06 行目)を定義しています.
- 03 行目
- クラス本体を記述する文の最初の行は文字列リテラルにすることもできます.その場合,この文字列はクラスのドキュメンテーション文字列と呼ばれ,変数 __doc__ によって参照できます( 09 行目).
- 10 行目~ 19 行目
- Example クラスのオブジェクト x,y,z を生成しています.インスタンス変数の値は異なりますが,クラス変数の値はすべて同じです.
- 20 行目~ 28 行目
- x を w に代入後,w のクラス変数及びインスタンス変数の値を変更しています.当然,w の値は変化しますが,x の値も変化しています.これは,x と w が同じオブジェクトを指していることも意味します.つまり,Python におけるオブジェクトは,C/C++ におけるポインタに似た性質を持つことになります.従って,関数に対する説明において述べたリストを引数とした場合と同様,クラスのインスタンスを引数とした場合は,関数内でその値を変更すれば,関数を呼んだ側の値も変化します.
- 29 行目~ 36 行目
- x と w は同じインスタンスを指していますので,x の値を変化させても,上と同様なことが起こります.また,関数自体もポインタ(関数を指すアドレス)ですので,30,31 行目のようなことが可能です.
- 37 行目~ 42 行目
- クラス変数の値を変更すると( 38 行目),そのクラスのすべてのインスタンスのクラス変数の値も変化します( 40,41 行目).ただし,23,32 行目のように,インスタンスのクラス変数の値を直接変更した場合は,その影響を受けません( 39,42 行目).クラス変数やインスタンス変数の参照方法等,分かり難く,誤りやすい仕様だと思います.クラス変数は,「クラス名.クラス変数名」という形でしか参照できない,といった仕様にした方が良いのではないでしょうか.現時点では,Python の使用者が,その規則を守るべきだと思います.
- 02 行目~ 06 行目
- (出力)
A simple example of class 最初の状態 x,y,z 12345 12345 10 12345 12345 20 12345 12345 30 ***w に x を代入*** w の値変更 x,y,z,w 12345 100 40 12345 12345 20 12345 12345 30 12345 100 40 x の値変更 x,y,z,w 12345 1000 50 12345 12345 20 12345 12345 30 12345 1000 50 クラス変数値の変更 x,y,z 123 1000 50 123 123 20 123 123 30 123 1000 50
- 大きなプログラムの場合,その部分的な機能の修正のため,他の機能に対応する部分も理解し,かつ,場合によってはそれらの一部も修正するなど,プログラム全体にわたって理解し,かつ,修正をしなければならないとしたら,大変なことになります.そこで,プログラムのモジュール化が非常に重要になります.各機能毎にモジュール化し,
- 初期化
- クラスに __init__() メソッドが定義されている場合,クラスのインスタンスを生成すると最初にこのメソッドが呼ばれます.C++ におけるコンストラクタに対応するメソッドです.上で述べたプログラムにおいても,05 行目を,コメントに示すように変更すれば,例えば,11,12 行目は,
x = Example(10)
- の 1 行で済みます.
# -*- coding: UTF-8 -*- class Complex() : def __init__(self, re, im = 0.0) : self.re = re self.im = im def add(self, v) : x = Complex(self.re + v.re, self.im + v.im) return x ---------------------------------- # -*- coding: UTF-8 -*- from function import Complex x = Complex(1, 2) y = Complex(3) z = x.add(y) print((z.re, z.im)) # (4, 2.0)
- 継承
- Windows のプログラムを書くような場合について考えてみてください.多くの Windows アプリケーションが存在しますが,その基本的なレイアウトや機能はほとんど同じです.それらのすべてを一から記述するとすれば大変な作業になります.しかし,Windows の基本機能を実現したプログラムがすでに存在し,そのプログラムを利用しながら必要な箇所の修正,追加を行うことによって可能であるとすれば,作業量は非常に少なくなります.これを実現したのが継承です.
- あるクラスに宣言されている変数やメソッドをすべて受け継ぎ(継承),受け継いだメソッドを修正,さらには,それに新たな変数やメソッドを付加して新しいクラスを宣言することができます.このとき,基になったクラスを基底クラス,また,派生したクラスを派生クラス呼びます.
- 派生クラスを定義する方法は簡単です.以下に示すように,基底クラスとなるクラス名を括弧内に並べるだけです(多重継承が可能).
- あるクラスに宣言されている変数やメソッドをすべて受け継ぎ(継承),受け継いだメソッドを修正,さらには,それに新たな変数やメソッドを付加して新しいクラスを宣言することができます.このとき,基になったクラスを基底クラス,また,派生したクラスを派生クラス呼びます.
class DerivedClassName ( BaseClassName1, BaseClassName2, ・・・ ):
- また,
BaseClassName.methodname(self, arguments)
- という形で,基底クラスのメソッドも簡単に呼び出すことができます.
- 下の例では,Num を基底クラスとした 2 つの派生クラス,Int 及び Complex を定義しています.C++ の場合は,型宣言の存在,コンストラクタが継承されない,などの理由から,かなり異なったプログラムになります.
# -*- coding: UTF-8 -*- class Num : name = "数値" def __init__(self, v) : self.v = v def add(self, v) : x = Num(self.v + v) return x class Int(Num) : name = "整数" class Complex(Num) : name = "複素数" # 親クラスのコンストラクタを呼びたい場合は Num.__init__(self, 値) def __init__(self, re, im = 0.0) : self.re = re self.im = im def add(self, v) : x = Complex(self.re + v.re, self.im + v.im) return x ---------------------------------- # -*- coding: UTF-8 -*- from function import * x = Int(10) # 基底クラス Num のコンストラクタ __init__ の継承により,変数 v に値が設定される print(x.v) # 10 y = x.add(20) # 親クラス Num のメソッド add の継承 print(y.v) # 30 u = Complex(1, 2) # クラス Complex のコンストラクタ __init__ の利用 print((u.re, u.im)) # (1, 2) v = Complex(3) print((v.re, v.im)) # (3, 0.0) w = u.add(v) # クラス Complex のメソッド add の利用 print((w.re, w.im)) # (4, 2.0) u.re = (Num.add(Num(u.re), 10)).v # 基底クラスのメソッド add の利用 print((u.re, u.im)) # (11, 2) print(u.name) # クラス Complex のクラス変数 name の値(複素数) print(Num.name) # 基底クラス Num のクラス変数 name の値(数値)
- Windows のプログラムを書くような場合について考えてみてください.多くの Windows アプリケーションが存在しますが,その基本的なレイアウトや機能はほとんど同じです.それらのすべてを一から記述するとすれば大変な作業になります.しかし,Windows の基本機能を実現したプログラムがすでに存在し,そのプログラムを利用しながら必要な箇所の修正,追加を行うことによって可能であるとすれば,作業量は非常に少なくなります.これを実現したのが継承です.
- インスタントメソッド,クラスメソッド,スタティックメソッド
- 今まで使用してきたメソッドはインスタントメソッドと呼ばれ,クラスのインスタント(オブジェクト)固有の処理を行うためのメソッドです.これ以外に,Python には,クラスメソッド,及び,スタティックメソッドが存在します.クラスメソッド,スタティックメソッドともに,インスタンス変数にはアクセスできません.
- クラスメソッドは,「 @classmethod 」を付与して関数を定義します.インスタンスメソッドの場合は,第一引数にオブジェクト自身 self が渡されますが,クラスメソッドの場合は,第一引数にクラスが渡されます.従って,クラスメソッドは渡ってきたクラスを使ってクラス変数にアクセスすることができます.継承時には,第一引数に子クラスが渡されるため,クラス変数は子クラスのクラス変数の値となります.
- スタティックメソッドは,「 @staticmethod 」を付与して関数を定義します.スタティックメソッドは,クラスが渡されないため,クラス変数にアクセスするためには,クラスを記述する必要があります.クラスを記述することによってクラス変数にアクセスするため,継承時においても,記述したクラスが親クラスか子クラスかによって参照先が変わります.
- 下の例では,上で示した例における基底クラス Num にクラスメソッドとスタティックメソッドが追加してあります.クラスメソッドの場合は,クラスが引数として渡されますので,30,31 行目,いずれの場合においても,Complex クラスにおけるクラス変数 name の値「複素数」が出力されます.しかし,スタティックメソッドの場合は( 32,33 行目),基底クラス Num のスタティックメソッドがそのまま継承されるため,基底クラスのクラス変数 name の値「数値」がそのまま出力されます.
- クラスメソッドは,「 @classmethod 」を付与して関数を定義します.インスタンスメソッドの場合は,第一引数にオブジェクト自身 self が渡されますが,クラスメソッドの場合は,第一引数にクラスが渡されます.従って,クラスメソッドは渡ってきたクラスを使ってクラス変数にアクセスすることができます.継承時には,第一引数に子クラスが渡されるため,クラス変数は子クラスのクラス変数の値となります.
01 # -*- coding: UTF-8 -*- 02 class Num : 03 name = "数値" 04 def __init__(self, v) : 05 self.v = v 06 def add(self, v) : 07 x = Num(self.v + v) 08 return x 09 # クラスメソッド 10 @classmethod 11 def class_method(cls) : 12 print(cls.name) 13 # スタティックメソッド 14 @staticmethod 15 def static_method() : 16 print(Num.name) 17 class Int(Num) : 18 name = "整数" 19 class Complex(Num) : 20 name = "複素数" 21 def __init__(self, re, im = 0.0) : 22 self.re = re 23 self.im = im 24 def add(self, v) : 25 x = Complex(self.re + v.re, self.im + v.im) 26 return x ---------------------------------- 27 # -*- coding: UTF-8 -*- 28 from function import * 29 x = Complex(1, 2) 30 Complex.class_method() 31 x.class_method() 32 Complex.static_method() 33 x.static_method()
- 今まで使用してきたメソッドはインスタントメソッドと呼ばれ,クラスのインスタント(オブジェクト)固有の処理を行うためのメソッドです.これ以外に,Python には,クラスメソッド,及び,スタティックメソッドが存在します.クラスメソッド,スタティックメソッドともに,インスタンス変数にはアクセスできません.
- 標準入出力
- コマンドプロンプト上でデータを変数に入力するためには(標準入力,sys.stdin からの入力),組み込み関数 input を使用します.引数を記述すると,それが末尾の改行を除いて標準出力に書き出され,入力された 1 行を読み込み,文字列に変換して返します(末尾の改行を除去).また,変数の値などを標準出力( sys.stdout )に表示するためには,組み込み関数 print を使用します.print は,与えられたオブジェクトを,スペースで区切り,標準出力に表示し,最後に改行します.
01 # -*- coding: UTF-8 -*- 02 a = input("data? ") 03 b = a.split() 04 print(b) 05 x = int(b[0]) 06 y = float(b[1]) 07 z = b[2] 08 print(x, y, z) 09 print("x = " + str(x) + ", y = " + str(y) + ", z = " + str(z)) 10 #print("x = " + x + ", y = " + y + ", z = " + z) # error 11 form = "x = {0:2d}, y = {1:.2f}, z = {2:s}".format(x, y, z) 12 print(form)- 02 行目
- 「 data? 」というメッセージが出力されます.例えば,「 10 3.141592654 abc 」を入力し改行を行うと,入力した結果が文字列として変数 a に代入されます.
- 03,04 行目
- 入力された文字列には,3 つのデータが含まれていますので,文字列型に対するメソッド split を使用して分離します.分離されたデータは,リストとして返されます( 03 行目).04 行目では,その結果を,組み込み関数 print を使用して,出力しています.05 行目~ 07 行目に示すように,リスト内の i 番目のデータを添え字 [i-1] で参照することができます.
- 05 行目~ 07 行目
- 数値データは,文字列のままでは演算等に使用できませんので,組み込み関数 int や float を使用して,整数や浮動小数点数に変換します.ただし,変数 z に対しては,文字列のまま代入しています.
- 08 行目
- 組み込み関数 print を使用して,3 つの変数の値を出力しています.
- 09 行目
- 例えば,
x = ..., y = ..., z = ...
- のような形式で出力したい場合,10 行目のような記述では,x 等を自動的に文字列に変換してくれず,エラーになってしまいます.そのため,変数 x 等を,組み込み関数 str によって,文字列に変換して,他の文字列と結合しています.
- 11,12 行目
- データを書式化して出力したい場合は,文字列型に対するメソッド format を使用します.format は,C/C++ の printf に似た方法によって書式化を実行します.この例では,整数は 2 桁で,また,浮動小数点数は小数点以下 2 桁で出力します.
- 02 行目
- (出力)
data? 10 3.141592654 abc ['10', '3.141592654', 'abc'] 10 3.141592654 abc x = 10, y = 3.141592654, z = abc x = 10, y = 3.14, z = abc
- 以下に示すプログラムを実行すると,キーボードから入力されたデータを "end\n" が入力されるか,または,改行キーだけが入力されるまで,画面に表示続けます.
# -*- coding: UTF-8 -*- import sys for line in sys.stdin : if line == "end\n" or len(line.strip()) <= 0 : break else : print(" " + line) # 以下の文とほぼ同じ line = sys.stdin.readline() while line != "end\n" and len(line.strip()) > 0 : print(" " + line) line = sys.stdin.readline()
- ファイル入出力
- ここでは,ファイル入出力の際必要となる基本的な関数やメソッドについて説明します.
- open('file_name', 'w') : ファイルオブジェクト f を返す.通常,2 つの引数を伴って呼び出される.最初の引数はファイル名の入った文字列である.2 つ目の引数,mode 引数も文字列であり,ファイルをどのように使用するかを示す数個の文字が入っている.ファイルが読み出し専用なら 'r',書き込み専用なら 'w' とする.'a' はファイルを追記用に開き,ファイルに書き込まれた内容は自動的にファイルの終端に追加される.'r+' はファイルを読み書き両用に開く.mode 引数を省略すると,'r' であると見なされる.通常,ファイルはテキストモードで開かれるが,JPEG ファイルや EXE ファイルのようなバイナリデータの場合は,mode に 'b' を付け,バイナリモードで開く必要がある.
- f.close() : ファイルオブジェクト f を閉じる.
- f.closed : ファイルオブジェクト f が閉じられていれば True に設定される.
- f.read([size]) : 最大 size バイトのデータを読み出し,文字列(テキストモードの場合),または,bytes オブジェクト(バイナリーモードの場合)として返す.size が省略されたり負の数であった場合,ファイルの内容全てを読み出して返す.また,ファイルの終端に達していた場合,空の文字列( '' )を返す.
- f.readline() : ファイルから 1 行だけ読み取る.なお,改行文字( \n )は読み出された文字列の終端に残る.
- f.write(object) : object の内容をファイルに書き込み,書き込まれた文字数を返す.オブジェクトの型は,書き込む前に,文字列(テキストモード),または,bytes オブジェクト(バイナリーモード)に変換しなければならない.
- f.seek(offset[, from_what]) : ファイルオブジェクトの位置を変更する.位置は from_what によって指定された値に offset を加えて計算される.from_what の値が 0 ならばファイルの 先頭から,1 ならば現在のファイル位置,2 ならばファイルの終端を基準点とする.from_what のデフォルトは 0 である.
- 以下に示すのは,上で述べた関数やメソッドの簡単な使用例です.
- open('file_name', 'w') : ファイルオブジェクト f を返す.通常,2 つの引数を伴って呼び出される.最初の引数はファイル名の入った文字列である.2 つ目の引数,mode 引数も文字列であり,ファイルをどのように使用するかを示す数個の文字が入っている.ファイルが読み出し専用なら 'r',書き込み専用なら 'w' とする.'a' はファイルを追記用に開き,ファイルに書き込まれた内容は自動的にファイルの終端に追加される.'r+' はファイルを読み書き両用に開く.mode 引数を省略すると,'r' であると見なされる.通常,ファイルはテキストモードで開かれるが,JPEG ファイルや EXE ファイルのようなバイナリデータの場合は,mode に 'b' を付け,バイナリモードで開く必要がある.
# -*- coding: UTF-8 -*- # 出力 f = open("test.txt", "w") # 出力のためにオープン f.write("10 3.1492654 abc\nテスト データ\n") f.close() # 全てのデータを入力 f = open("test.txt", "r") # 入力のためにオープン a = f.read() print(a) # "10 3.1492654 abc\nテスト データ\n" # ファイルの先頭に移動 f.seek(0) # 1 行ずつ入力 b = f.readline() print(b) # "10 3.1492654 abc\n" b = f.readline() print(b) # "テスト データ\n" b = f.readline() print(b) # "" f.close()- ファイルの内容すべてを読み込む場合,次の例のように,標準関数 iter を使用した方法がしばしば使用されます.
# -*- coding: UTF-8 -*- with open('test.txt') as fp: for line in iter(fp.readline, ''): print(line, end="")- 数値データを要素として持つ配列を扱いたい場合において,拡張モジュール NumPy がインストールされていると,以下に示すように,配列に対する入出力を簡単に行うことができます.
# -*- coding: UTF-8 -*- import numpy as np a = np.array([[1, 2, 3], [4, 5, 6]]) # 2 行 3 列 np.savetxt('test.txt', a) # 配列 a の出力 b = np.loadtxt('test.txt') # 配列 b への入力 print(b)
- ここでは,ファイル入出力の際必要となる基本的な関数やメソッドについて説明します.
01 # -*- coding: UTF-8 -*- 02 03 #***************************/ 04 # 変数の有効範囲(スコープ) */ 05 # coded by Y.Suganuma */ 06 #***************************/ 07 08 #******************/ 09 # クラス Example1 */ 10 #******************/ 11 class Example1 : 12 c_var = 1000 13 14 def __init__(self) : 15 self.i_var = 2000 16 17 def sub1(self) : 18 print("sub1 c_var", self.c_var, "i_var", self.i_var) 19 20 #******************/ 21 # クラス Example2 */ 22 #******************/ 23 class Example2(Example1) : 24 def sub2(self) : 25 print("sub2 c_var", self.c_var, "i_var", self.i_var) 26 27 #***********/ 28 # 関数 sub */ 29 #***********/ 30 def sub() : # この位置で定義する必要がある 31 x = 40 32 print(" sub x", x) 33 print(" sub z", z) 34 35 #***************/ 36 # main program */ 37 #***************/ 38 # ブロック 39 x = 10 40 z = 30 41 if x > 5 : 42 print("block x", x) 43 x = 15 44 y = 20 45 print("block x", x) 46 print("block y", y) 47 else : 48 print("block x", x) 49 x = -15 50 print("block x", x) 51 sub() 52 print("x", x) 53 print("y", y) # 最初の x が 1 の時は,y が未定義のためエラー 54 # クラス 55 ex = Example2() 56 ex.sub1() 57 ex.sub2() 58 print("member( c_var )", Example2.c_var) 59 print("member( i_var )", ex.i_var)- まず,39 行目において,変数 x が定義され(変数 x に値が代入され),10 で初期設定されています.この変数 x は,この位置から main プログラムが終わる 59 行目まで有効になります.42 ~ 46 行目の if ブロック内の 42 行目において,変数 x の値が出力されていますが,当然,その結果は,39 行目で宣言されたときの値になります.しかし,43 行目において,再び,変数 x が宣言されていますが,Python の場合は,C++ の場合とは異なり,39 行目で宣言された変数 x に置き換わることになります.従って,ここで宣言された変数 x の有効範囲は,main プログラムの終わりである 59 行目までになります.実際,52 行目における出力文では,43 行目において宣言された変数 x の値が出力されます.同様に,44 行目で宣言された変数 y の有効範囲も 59 行目までとなります.この例では,問題がありませんが,39 行目における変数 x の初期値を 5 以下に設定すると,48 ~ 50 行目が実行されることになります.そのブロック内では,変数 y が使用されていませんので,53 行目の出力文はエラーになってしまいます.変数が定義されているか否か(変数に値が代入されているか否か)の見極めが困難である場合も多いと思いますので,十分注意してください.
- 51 行目において関数 sub を呼んでいます.31 行目では,変数 x を宣言(変数 x に値を代入)し,32 行目において,その値を出力しています.31 行目の宣言を行わなければ,変数 z と同様,main プログラム内の変数 x の値が出力されます.main プログラム内の変数 x ( 39 行目)の値を変更したい場合は,31 行目の前に,
global x- という宣言をしておく必要があります.
- 一般に,Python では,main プログラム内の変数は,33 行目に示すように,どの関数からも参照することができます(非常に危険だと思いますが).ただし,関数内で main プログラムと同じ変数を定義(変数に代入を行うことを意味する)したり,あるいは,新しい変数を定義した場合,それらの変数を main プログラムから参照することはできません( 52 行目に対応する出力結果参照).また,ある関数から,異なる関数内の変数を参照することも不可能です.このように,どの関数からも参照可能な変数をグローバル変数と呼びます.逆に,ある関数内だけで有効な変数を,ローカル変数と呼びます.以上,40 ~ 54 行目内の出力文(関数 sub 内の出力文を含む)によって,以下に示すような出力が得られます.
block x 10 block x 15 block y 20 sub x 40 sub z 30 x 15 y 20
- 次に,クラスに付いて考えてみます.11 ~ 18 行目においてクラス Example1 が定義され,23 ~ 25 行目では,クラス Example1 を継承する形で,クラス Example2 が定義されています.なお,Python においては,すべての変数をクラス外から参照可能です( C++ において,public 指定してる状況).
- 55 行目において,Example2 のインスタンス ex を生成し,56 行目では,クラス Example1 から継承した関数 sub1 を通して,2 つの変数を出力しています.また,57 行目では,クラス Example2 に追加された関数 sub2 を通して各変数を出力しています.いずれも,同じように出力されます.Python において,12 行目のような形で宣言された変数はクラス変数と呼ばれ,すべてのクラスのインスタンスで同じ値を持ち,クラス外部からでも,58 行目のような形で参照できます.また,15 行目のように,self を付加して宣言した変数は,インスタンス変数と呼ばれ,インスタンス毎に異なる値をとることが可能です.インスタンス変数は,59 行目のような形で,クラスの外部からも参照することができます.以上,55 ~ 69 行目内の出力文によって,以下に示すような出力が得られます.
sub1 c_var 1000 i_var 2000 sub2 c_var 1000 i_var 2000 member( c_var ) 1000 member( i_var ) 2000
- まず,39 行目において,変数 x が定義され(変数 x に値が代入され),10 で初期設定されています.この変数 x は,この位置から main プログラムが終わる 59 行目まで有効になります.42 ~ 46 行目の if ブロック内の 42 行目において,変数 x の値が出力されていますが,当然,その結果は,39 行目で宣言されたときの値になります.しかし,43 行目において,再び,変数 x が宣言されていますが,Python の場合は,C++ の場合とは異なり,39 行目で宣言された変数 x に置き換わることになります.従って,ここで宣言された変数 x の有効範囲は,main プログラムの終わりである 59 行目までになります.実際,52 行目における出力文では,43 行目において宣言された変数 x の値が出力されます.同様に,44 行目で宣言された変数 y の有効範囲も 59 行目までとなります.この例では,問題がありませんが,39 行目における変数 x の初期値を 5 以下に設定すると,48 ~ 50 行目が実行されることになります.そのブロック内では,変数 y が使用されていませんので,53 行目の出力文はエラーになってしまいます.変数が定義されているか否か(変数に値が代入されているか否か)の見極めが困難である場合も多いと思いますので,十分注意してください.