
- C++
データ型 バイト数と値の範囲 void * * char 1 -128 ~ 127(文字型,整数型) unsigned char 1 0 ~ 255(文字型,符号無し整数型) short 2 -32,768 ~ 32,767(整数型) unsigned short 2 0 ~ 65,535(符号無し整数型) int * システム依存(整数型) unsigned int * システム依存(符号無し整数型) long 4 -2,147,483,648 ~ 2,147,483,647(整数型) unsigned long 4 0 ~ 4,294,967,295(符号無し整数型) long long 8 -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807(整数型) unsigned long long 8 0 ~ 18,446,744,073,709,551,615(符号無し整数型) float 4 3.4E±38(浮動小数点型,有効桁は約 7 桁) double 8 1.7E±308(浮動小数点型,有効桁は約 15 桁) long double * 拡張精度,システム依存(浮動小数点型) bool 1 true(0以外) or false(0)(論理型) auto * 代入された値によって型を推論する 文字列 : ダブルクォ-テンションマーク「 " 」で囲む(配列,または,string クラスの使用).
- Java
データ型 バイト数と値の範囲 byte 1 -128 ~ 127(整数型) char 2 1 つの Unicode 文字(文字型) short 2 -32,768 ~ 32,767(整数型) int 4 -2,147,483,648 ~ 2,147,483,647(整数型) long 8 -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807(整数型) float 4 3.4E±38(浮動小数点型,有効桁は約 7 桁) double 8 1.7E±308(浮動小数点型,有効桁は約 15 桁) boolean 1 true, false 文字列 : ダブルクォ-テンションマーク「 " 」で囲む( String クラスの使用).
- JavaScript
- 数値 : 整数と浮動小数点数は区別されず,すべて,8 バイトの浮動小数点数として表現されます.表現可能な範囲は,
±1.7976931348623157×10308
- となります.また,整数として精度が保証されるのは,
-253(-9,007,199,254,740,992) ~ 253(9,007,199,254,740,992)
- の範囲です.
- 文字列 : ダブルクォ-テンションマーク「 " 」,または,シングルクォ-テンションマーク「 ' 」で囲まれた文字や数字です.両者に差はなく,「"abc"」と「'abc'」は全く同じ文字列になります.また,String オブジェクトとしても表現できますが,同じ内容の文字列であっても,ダブルクォ-テンションマーク等で囲まれた文字列定数と String オブジェクトは全く別のものです.
- 論理値 : true(0以外), false(0)
- 数値 : 整数と浮動小数点数は区別されず,すべて,8 バイトの浮動小数点数として表現されます.表現可能な範囲は,
- PHP
- 数値 : 10 進整数,8 進数( 0 で始まる),16 進数( 0x で始まる),浮動小数点数を使用できます.環境によって異なりますが,基本的に,整数は 4 バイト,浮動小数点数は 8 バイトで表現されます.
- 文字列 : 文字列は,シングルクォーテーション「 ' 」,または,ダブルクォーテーション「 " 」によって囲んで表現されます.シングルクォーテーションで囲まれた場合は,その内容がそのまま文字列の内容となりますが,ダブルクォーテーションで囲まれた場合はその内部のエスケープシーケンスや変数が評価されます.
- 論理値 : true(0以外),false(0)(大文字,小文字を区別しない)
- 数値 : 10 進整数,8 進数( 0 で始まる),16 進数( 0x で始まる),浮動小数点数を使用できます.環境によって異なりますが,基本的に,整数は 4 バイト,浮動小数点数は 8 バイトで表現されます.
- Ruby
- 数値 : 10 進整数,8 進数( 0 で始まる),16 進数( 0x で始まる),浮動小数点数を使用できます.整数は,Integer クラス のサブクラスである Fixnum クラスのインスタンスです.ただし,整数の大きさが Fixnum によって表現できる範囲を超えると Bignum クラスのインスタンスとして扱われ,任意の桁数の整数を表現可能です.また,浮動小数点数は,Float クラスのインスタンスであり,8 バイトで表現されます.
- 文字列 : 文字列は,シングルクォーテーション「 ' 」,または,ダブルクォーテーション「 " 」によって囲んで表現され,String クラスのインスタンスです.ダブルクォーテーションで囲まれた文字列では,バックスラッシュ記法と式展開が有効になります.シングルクォーテーションで囲まれた文字列では,\\ (バックスラッシュそのもの)と \' (シングルクォーテーション),行末の \ (改行を無視)を除いて文字列の中身の解釈は行われません.
- 論理値 : true 及び false で表現され,各々,TrueClass クラスの及び FalseClass クラスの唯一のインスタンスです.
- 数値 : 10 進整数,8 進数( 0 で始まる),16 進数( 0x で始まる),浮動小数点数を使用できます.整数は,Integer クラス のサブクラスである Fixnum クラスのインスタンスです.ただし,整数の大きさが Fixnum によって表現できる範囲を超えると Bignum クラスのインスタンスとして扱われ,任意の桁数の整数を表現可能です.また,浮動小数点数は,Float クラスのインスタンスであり,8 バイトで表現されます.
- Python
- 数値 : 数値には 3 種類あります.整数,浮動小数点数,及び,虚数です.整数は,10 進数,8 進数 0ohhhh,16 進数 0xhhhh,または,2 進数 0bhhhh を使用して表現できます( o,x,b は大文字でも良い).なお,値がメモリ上に収まるかどうかという問題を除けば,整数には長さの制限がありません.浮動小数点数の取りうる値の範囲は実装に依存します.
- 文字列 : 文字列およびバイト列( bytes 型)は,シングルクォーテーション「 ' 」,または,ダブルクォーテーション「 " 」で囲まれます.Python においては,二つの引用符は同じ意味になります.また,バイト列に対しては,常に b や B が接頭します.
- 論理値 : 整数の一種であり,False と True の値をとります.真偽値を表すブール型は整数型の派生型であり,ほとんどの状況でそれぞれ 0 と 1 のように振る舞います.
- 数値 : 数値には 3 種類あります.整数,浮動小数点数,及び,虚数です.整数は,10 進数,8 進数 0ohhhh,16 進数 0xhhhh,または,2 進数 0bhhhh を使用して表現できます( o,x,b は大文字でも良い).なお,値がメモリ上に収まるかどうかという問題を除けば,整数には長さの制限がありません.浮動小数点数の取りうる値の範囲は実装に依存します.
- C#
データ型 バイト数と値の範囲 sbyte 1 -128 ~ 127(符号付き整数) byte 1 0 ~ 255(符号なし整数) short 2 -32768 ~ 32767(符号付き整数) ushort 2 0 ~ 65535(符号なし整数) int 4 -2147483648 ~ 2147483647(符号付き整数) uint 4 0 ~ 4294967295(符号なし整数) long 8 -9223372036854775808 ~ 9223372036854775807(符号付き整数) ulong 8 0 ~ 18446744073709551615(符号なし整数) float 4 1.5 * 10-45 ~ 3.4 * 1038(単精度浮動小数点数,有効桁は約 7 桁) double 8 5.0 * 10-324 ~ 1.7 * 10308(倍精度浮動小数点数,有効桁は約 15 桁) decimal 16 0 ~ ±79228162514264337593543950335(有効桁約 28 桁) char 2 0 ~ 65535(符号なし整数),Unicode 文字 string Unicode 文字列 bool 真理値(true と false) object 任意のオブジェクトへの参照
- VB
データ型 バイト数と値の範囲 SByte 1 -128 ~ 127(符号付き整数) Byte 1 0 ~ 255(符号なし整数) Short 2 -32768 ~ 32767(符号付き整数) UShort 2 0 ~ 65535(符号なし整数) Integer 4 -2147483648 ~ 2147483647(符号付き整数) UInteger 4 0 ~ 4294967295(符号なし整数) Long 8 -9223372036854775808 ~ 9223372036854775807(符号付き整数) ULong 8 0 ~ 18446744073709551615(符号なし整数) Single 4 1.5 * 10-45 ~ 3.4 * 1038(単精度浮動小数点数,有効桁は約 7 桁) Double 8 5.0 * 10-324 ~ 1.7 * 10308(倍精度浮動小数点数,有効桁は約 15 桁) Decimal 16 0 ~ ±79228162514264337593543950335(有効桁約 28 桁) Char 2 0 ~ 65535 (符号なし整数) ,単一文字 String Unicode 文字列 Boolean True( 0 以外),False( 0 ) Object 任意のオブジェクトへの参照 Date 8 00:00:00 AM (0001年1月1日) ~ 11:59:59 PM (9999 年12月31日)
x = 10; y = 20;
z = x + y;

int x, y; char u; double v; x = 10; // 1 行目を削除し,int x = 10; でも可 y = 20; // 1 行目を削除し,int y = 20; でも可 u = 'x'; // 2 行目を削除し,char u = 'x'; でも可 v = 3.14; // 3 行目を削除し,double v = 3.14; でも可
x = 10; y = x; // 変数 x に記憶されている値のコピーを記憶 y = 20;
- C++
- C++ は,ここで紹介する言語の中で,唯一,アドレスを直接扱えるアドレス演算子や間接演算子を持つ言語です.そのため,変数に記憶されているデータがどのようなものなのか,どのような意味を持っているか等によって,記述方法が異なります.従って,上に述べたような誤りを犯す可能性は非常に少ないと思います.記述方法が多少面倒になりますが,正しいプログラムを書くためには,やむを得ない仕様ではないかと思います.
- 整数型
01 #include <stdio.h> 02 03 int main() 04 { 05 printf(" 変更前\n"); 06 int ia, ib, ic, &id = ia; 07 ia = 10; 08 ib = 10; 09 ic = ia; 10 printf("ia %d ib %d ic %d id(iaの別名) %d\n", ia, ib, ic, id); 11 printf(" 変更後\n"); 12 ia = 100; 13 ib = 200; 14 ic = 300; 15 printf("ia %d ib %d ic %d id(iaの別名) %d\n", ia, ib, ic, id); 16 id = 400; // id は参照型変数( ia の別名) 17 printf("ia %d ib %d ic %d id(iaの別名) %d\n", ia, ib, ic, id); 18 printf(" アドレスの利用\n"); 19 int *iap = &ia, *ibp = &ib, *icp = iap, *idp = &id; 20 printf("iap %08x ibp %08x icp %08x idp(idはiaの別名) %08x\n", (unsigned)iap, (unsigned)ibp, (unsigned)icp, (unsigned)idp); 21 *iap = 10; 22 *ibp = 20; 23 printf("ia %d ib %d ic %d id(iaの別名) %d\n", ia, ib, ic, id); 24 *icp = 30; // icp と iap は等しい 25 printf("ia %d ib %d ic %d id(iaの別名) %d\n", ia, ib, ic, id); 26 *idp = 40; 27 printf("ia %d ib %d ic %d id(iaの別名) %d\n", ia, ib, ic, id); 28 29 return 0; 30 }- 整数型のデータに対して,記憶と変更の問題を検討したプログラムです.変数 id は,06 行目の宣言により,変数 ia の別名となります.このような変数を,参照型変数と呼びます.07 行目~ 09 行目の記述によって,変数 ia 及び ib には 10 という値が記憶され,変数 ic には変数 ia に記憶されている値のコピーが記憶されます.従って,10 行目の出力文によって,以下に示すような出力が得られます.
ia 10 ib 10 ic 10 id(iaの別名) 10
- 12 行目~ 14 行目,16 行目において,各変数に記憶しているデータを変更しています.09 行目の記述があっても,ia と ic は異なる変数ですので,各々独立に変化します.また,変数 id は,変数 ia の別名ですので,ia,id のいずれかの値を変更すれば他の変数の値も変化します.従って,15,17 行目の出力文によって,下に示すような結果が得られます.以上の結果を概念的に図示すればその下に示す図のようになります.
ia 100 ib 200 ic 300 id(iaの別名) 100 ia 400 ib 200 ic 300 id(iaの別名) 400
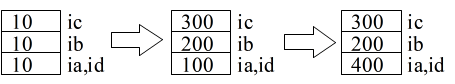
- C++ においては,変数が示す記憶場所(変数のアドレス)を,アドレス演算子 & を使用して知ることができます.例えば,以下のように記述することによって,変数 x のアドレスを変数(ポインタ変数) p に記憶できます.また,間接演算子 * を使用して,ポインタ変数が指すアドレスに記憶されている値(変数の値)を参照することが可能です.プログラムの下に示した図は,以下に示すプログラムの断片の実行結果を概念的に示したものです.
int x; int *p = &x; *p = 20; // x = 20; int y = *p; // y = x;

- 19 行目では,変数 ia のアドレスをポインタ変数 iap に,変数 ib のアドレスをポインタ変数 ibp に,変数 id のアドレスをポインタ変数 idp に記憶しています.また,ポインタ変数 icp には,ポインタ変数 iap に記憶されている値(アドレス)をコピーして記憶しています.20 行目の出力結果によって,以下に示すように,iap,icp,idp は,アドレス 0091fdc8 に記憶されている同じ変数を指していることが分かります.イメージとしては,出力結果の下に示す図のようになります.
iap 0091fdc8 ibp 0091fdc4 icp 0091fdc8 idp(idはiaの別名) 0091fdc8

- 21 行目~ 22 行目においては,ポインタを介して変数 ia と ib の値を変更しています.24 行目においては,ポインタ icp を介して変数の値を変更しています.icp と iap は,同じ場所を示しているため,結局,変数 ia ( id )の値が変更されます.また,26 行目においては,ポインタ変数 idp を介して,変数 id ( ia )の値が変更されています.以上の結果,23 行目,25 行目,及び,27 行目の出力文によって,以下に示すような出力が得られます.
ia 10 ib 20 ic 300 id(iaの別名) 10 ia 30 ib 20 ic 300 id(iaの別名) 30 ia 40 ib 20 ic 300 id(iaの別名) 40
- 浮動小数点型,文字型
01 #include <stdio.h> 02 03 int main() 04 { 05 // double 06 printf(" ***double***\n"); 07 printf(" 変更前\n"); 08 double da, db, dc, &dd = da; 09 da = 10.1; 10 db = 10.1; 11 dc = da; 12 printf("da %f db %f dc %f dd(daの別名) %f\n", da, db, dc, dd); 13 printf(" 変更後\n"); 14 da = 100.1; 15 db = 200.1; 16 dc = 300.1; 17 printf("da %f db %f dc %f dd(daの別名) %f\n", da, db, dc, dd); 18 dd = 400.1; // dd は参照型変数( da の別名) 19 printf("da %f db %f dc %f dd(daの別名) %f\n", da, db, dc, dd); 20 printf(" アドレスの利用\n"); 21 double *dap = &da, *dbp = &db, *dcp = dap, *ddp = ⅆ 22 printf("dap %08x dbp %08x dcp %08x ddp(ddはdaの別名) %08x\n", (unsigned)dap, (unsigned)dbp, (unsigned)dcp, (unsigned)ddp); 23 *dap = 10.1; 24 *dbp = 20.1; 25 printf("da %f db %f dc %f dd(daの別名) %f\n", da, db, dc, dd); 26 *dcp = 30.1; // dcp と dap は等しい 27 printf("da %f db %f dc %f dd(daの別名) %f\n", da, db, dc, dd); 28 *ddp = 40.1; 29 printf("da %f db %f dc %f dd(daの別名) %f\n", da, db, dc, dd); 30 // 文字 31 printf(" ***文字***\n"); 32 printf(" 変更前\n"); 33 char ca, cb, cc, &cd = ca; 34 ca = 'a'; 35 cb = 'a'; 36 cc = ca; 37 printf("ca %c cb %c cc %c cd(caの別名) %c\n", ca, cb, cc, cd); 38 printf(" 変更後\n"); 39 ca = 'u'; 40 cb = 'v'; 41 cc = 'w'; 42 printf("ca %c cb %c cc %c cd(caの別名) %c\n", ca, cb, cc, cd); 43 cd = 'x'; // cd は参照型変数( ca の別名) 44 printf("ca %c cb %c cc %c cd(caの別名) %c\n", ca, cb, cc, cd); 45 printf(" アドレスの利用\n"); 46 char *cap = &ca, *cbp = &cb, *ccp = cap, *cdp = &cd; 47 printf("cap %08x cbp %08x ccp %08x cdp(cdはcaの別名) %08x\n", (unsigned)cap, (unsigned)cbp, (unsigned)ccp, (unsigned)cdp); 48 *cap = 'a'; 49 *cbp = 'b'; 50 printf("ca %c cb %c cc %c cd(caの別名) %c\n", ca, cb, cc, cd); 51 *ccp = 'c'; // ccp と cap は等しい 52 printf("ca %c cb %c cc %c cd(caの別名) %c\n", ca, cb, cc, cd); 53 *cdp = 'd'; 54 printf("ca %c cb %c cc %c cd(caの別名) %c\n", ca, cb, cc, cd); 55 56 return 0; 57 }- 06 行目~ 29 行目
- 浮動小数点型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
***double*** 変更前 da 10.100000 db 10.100000 dc 10.100000 dd(daの別名) 10.100000 変更後 da 100.100000 db 200.100000 dc 300.100000 dd(daの別名) 100.100000 da 400.100000 db 200.100000 dc 300.100000 dd(daの別名) 400.100000 アドレスの利用 dap 0091fdb8 dbp 0091fdb0 dcp 0091fdb8 ddp(ddはdaの別名) 0091fdb8 da 10.100000 db 20.100000 dc 300.100000 dd(daの別名) 10.100000 da 30.100000 db 20.100000 dc 300.100000 dd(daの別名) 30.100000 da 40.100000 db 20.100000 dc 300.100000 dd(daの別名) 40.100000
- 31 行目~ 54 行目
- 文字型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.char 型は,1 バイトの int 型と同等であり,当然の結果といえます.
***文字*** 変更前 ca a cb a cc a cd(caの別名) a 変更後 ca u cb v cc w cd(caの別名) u ca x cb v cc w cd(caの別名) x アドレスの利用 cap 0091fdaf cbp 0091fdae ccp 0091fdaf cdp(cdはcaの別名) 0091fdaf ca a cb b cc w cd(caの別名) a ca c cb b cc w cd(caの別名) c ca d cb b cc w cd(caの別名) d
- 1 次元配列
01 #include <stdio.h> 02 03 int main() 04 { 05 printf(" 1次元,変更前\n"); 06 int x1[3] = {1, 2, 3}, x2[3]; // x1 に対しては,各要素を 1,2,3 で初期化 07 for (int i1 = 0; i1 < 3; i1++) // x2 = x1 は許されない 08 x2[i1] = x1[i1]; 09 printf("x1 %d %d %d\n", x1[0], x1[1], x1[2]); 10 printf("x2 %d %d %d\n", x2[0], x2[1], x2[2]); 11 printf(" 1次元,変更後\n"); 12 x1[1] = 4; 13 int *xp = &x1[2]; 14 xp[0] = 5; // *xp = 5; でも良い 15 x2[0] = 6; 16 printf("x1 %d %d %d\n", x1[0], x1[1], x1[2]); 17 printf("x2 %d %d %d\n", x2[0], x2[1], x2[2]); 18 19 return 0; 20 }- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.例えば,
int x[3], y[4];
- のように宣言すれば,3 つ,及び,4 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,x[0],x[1],x[2],y[0],y[1],y[2],y[3] のようにして参照できます.配列は,ポインタと非常に強い関係があります.例えば,上のように宣言した場合,3 つ,及び,4 つの整数型データを記憶できる領域の先頭アドレスをポインタ変数 x,及び,y が指しているようなイメージになります.ただし,x++,x = y などの演算ができないなど,ポインタ変数とは多少異なります.

- 配列に対しては,整数などの基本データ型とは異なり,x1 に記憶されているデータをすべて x2 に記憶するため,x2 = x1 という操作を行うことができません.そのため,07 行目~ 08 行目のように,個々のデータを個別に記憶しています.その結果,基本データ型と同様,片方の配列内の値を変更しても,他の配列は変化しません.また,13 行目に示すように,配列内の特定の要素のアドレスを取得することによって,配列の一部を別の配列のように扱うことも可能です.この場合,xp は,要素数が 1 である 1 次元配列とみなせます.ただし,xp は,x1 の 3 番目の要素を指しているわけですから,xp の各要素の値を変更すれば( 14 行目),対応する x1 の要素の値も変化します.05 行目~ 17 行目内の出力文によって,以下に示すような結果が得られます.
1次元,変更前 x1 1 2 3 x2 1 2 3 1次元,変更後 x1 1 4 5 x2 6 2 3
- 2 次元配列
01 #include <stdio.h> 02 03 int main() 04 { 05 printf(" 多次元,変更前\n"); 06 int y[2][3] = {{10, 20, 30}, {40, 50, 60}}; 07 printf("y %d %d %d\n", y[0][0], y[0][1], y[0][2]); 08 printf(" %d %d %d\n", y[1][0], y[1][1], y[1][2]); 09 printf(" 多次元,変更後\n"); 10 y[0][1] = 70; 11 int *yp1 = &y[0][0]; 12 int *yp2 = y[1]; 13 yp1[4] = 80; // *(yp1+4) = 80; でも良い 14 yp2[2] = 90; // *(yp2+2) = 90; でも良い 15 printf("y %d %d %d\n", y[0][0], y[0][1], y[0][2]); 16 printf(" %d %d %d\n", y[1][0], y[1][1], y[1][2]); 17 18 return 0; 19 }- 多次元の配列を扱うことも可能です.例えば,
int y[2][3] = {{10, 20, 30}, {40, 50, 60}};- のように記述すれば,2 行 3 列の表に対応する配列を定義できます.ポインタ変数との関係から考えると,以下の図に示すように,ポインタ変数 y が,2 つのポインタ変数 y[0],y[1] を記憶する領域の先頭を指し,y[0],y[1] が,各々,3 つの整数型データを記憶する領域の先頭を指すことになります.
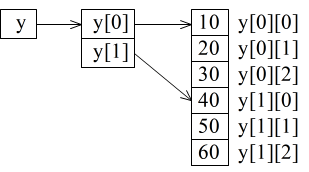
- ただし,上の図に示すように,実際のデータが記憶される領域は連続的に確保されるため,11 行目~ 14 行目のように,その一部を 1 次元配列として扱うことも可能です.特に,yp1 が 1 行目の先頭要素に対するアドレスであることにもかかわらず,yp1[4] が配列 y の 2 行目の要素であることに注意してください.また,1 元配列と同様,多次元配列を他の多次元配列にコピーして記憶しても,各々独立した配列になるため,片方の配列内の値を変更しても,他の配列は変化しません.05 行目~ 16 行目内の出力文によって,以下に示すような結果が得られます.
多次元,変更前 y 10 20 30 40 50 60 多次元,変更後 y 10 70 30 40 80 90
- 1 次元配列( new 演算子)
01 #include <stdio.h> 02 03 int main() 04 { 05 printf(" 1次元,変更前\n"); 06 int *u1 = new int [3], *u2 = new int [3], *u3; // int *u1 = new int [3] {1, 2, 3}; のような初期設定も可 07 for (int i1 = 0; i1 < 3; i1++) { 08 u1[i1] = i1 + 1; 09 u2[i1] = i1 + 1; 10 } 11 u3 = u1; 12 printf("u1 %d %d %d\n", u1[0], u1[1], u1[2]); 13 printf("u2 %d %d %d\n", u2[0], u2[1], u2[2]); 14 printf("u3 %d %d %d\n", u3[0], u3[1], u3[2]); 15 printf(" 1次元,変更後\n"); 16 u1[1] = 4; 17 u3[0] = 0; 18 int *up = &u1[2]; 19 up[0] = 5; // *up = 5; でも良い 20 printf("u1 %d %d %d\n", u1[0], u1[1], u1[2]); 21 printf("u2 %d %d %d\n", u2[0], u2[1], u2[2]); 22 printf("u3 %d %d %d\n", u3[0], u3[1], u3[2]); 23 24 return 0; 25 }- new 演算子を使用して配列を実現することも可能です.new 演算子は,指定されたデータ型を指定された数だけ記憶できる領域を確保し,その先頭のアドレスを返す演算子です.例えば,06 行目の記述によって,整数型のデータを 3 つ記憶できる領域が確保され,その先頭アドレスがポインタ変数 u1 に記憶されます.u2 についても同様ですが,u1 とは別の配列になります.また,各要素の参照は,配列と同じ方法で可能です.u1 は,基本データ型の一種であるポインタ変数ですので,11 行目のような代入が可能です.その結果,06 行目~ 11 行目の記述によって,以下に示すような状態になります.
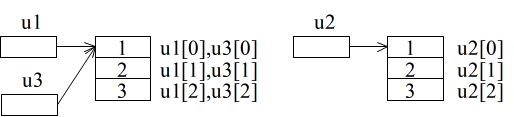
- 上の図からも明らかなように,11 行目の記述によって,u3 には u1 に記憶されているアドレスが記憶されるため,u1 と u3 は同じ領域を指すことになります.従って,u1 の要素の値を変更すれば,対応する u3 の要素の値も変化します(逆も同様).C++ 以外の言語においては,ポインタ変数という形では現れませんが,配列を確保する場合,ここで述べた new 演算子を使用した方法と似た結果になる場合が多いので注意してください.05 行目~ 22 行目内の出力文によって,以下に示すような結果が得られます.
1次元,変更前 u1 1 2 3 u2 1 2 3 u3 1 2 3 1次元,変更後 u1 0 4 5 u2 1 2 3 u3 0 4 5
- 2 次元配列( new 演算子)
01 #include <stdio.h> 02 03 int main() 04 { 05 printf(" 多次元,変更前\n"); 06 int **v1 = new int *[2], **v2 = new int *[2], **v3; // 以下のような方法で初期設定も可 // int ** v1 = new int* [2]; // v1[0] = new int [3] {10, 20, 30}; // v1[1] = new int [3] {40, 50, 60}; 07 v1[0] = new int [3]; 08 v2[0] = new int [3]; 09 for (int i1 = 0; i1 < 3; i1++) { 10 v1[0][i1] = 10 * (i1 + 1); 11 v2[0][i1] = 10 * (i1 + 1); 12 } 13 v1[1] = new int [3]; 14 v2[1] = new int [3]; 15 for (int i1 = 0; i1 < 3; i1++) { 16 v1[1][i1] = 10 * (i1 + 4); 17 v2[1][i1] = 10 * (i1 + 4); 18 } 19 v3 = v1; 20 printf("v1 %d %d %d\n", v1[0][0], v1[0][1], v1[0][2]); 21 printf(" %d %d %d\n", v1[1][0], v1[1][1], v1[1][2]); 22 printf("v2 %d %d %d\n", v2[0][0], v2[0][1], v2[0][2]); 23 printf(" %d %d %d\n", v2[1][0], v2[1][1], v2[1][2]); 24 printf("v3 %d %d %d\n", v3[0][0], v3[0][1], v3[0][2]); 25 printf(" %d %d %d\n", v3[1][0], v3[1][1], v3[1][2]); 26 printf(" 多次元,変更後\n"); 27 v3[0][1] = 70; 28 int *vp1 = &v1[0][0]; 29 int *vp2 = v1[1]; 30 vp1[0] = 80; // *(vp1+2) = 80; でも良い 31 vp2[2] = 90; // *(vp2+2) = 90; でも良い,*(vp1+5) = 90;,vp1[5]; は許されない 32 printf("v1 %d %d %d\n", v1[0][0], v1[0][1], v1[0][2]); 33 printf(" %d %d %d\n", v1[1][0], v1[1][1], v1[1][2]); 34 printf("v2 %d %d %d\n", v2[0][0], v2[0][1], v2[0][2]); 35 printf(" %d %d %d\n", v2[1][0], v2[1][1], v2[1][2]); 36 printf("v3 %d %d %d\n", v3[0][0], v3[0][1], v3[0][2]); 37 printf(" %d %d %d\n", v3[1][0], v3[1][1], v3[1][2]); 38 39 return 0; 40 }- new 演算子によって,多次元配列も実現可能です.そのイメージは,下に示すように,new 演算子を使用しない場合に対する多次元配列の箇所で示したものとほとんど同じです.ただし,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません( 31 行目参照).1 次元配列の場合と同様,ポインタ変数を他のポインタ変数に代入すれば同じ領域を指すことになる点に注意してください.05 行目~ 37 行目内の出力文によって,図の下に示すような結果が得られます.
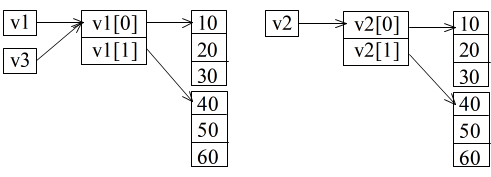
多次元,変更前 v1 10 20 30 40 50 60 v2 10 20 30 40 50 60 v3 10 20 30 40 50 60 多次元,変更後 v1 80 70 30 40 50 90 v2 10 20 30 40 50 60 v3 80 70 30 40 50 90
- C++ 標準ライブラリ内 の vector クラス
01 #include <stdio.h> 02 #include <iostream> 03 #include <vector> 04 05 using namespace std; 06 07 int main() 08 { 09 printf(" 変更前\n"); 10 vector<int> w1, w2; // vector<int> w1 {1, 2, 3}; のような初期設定も可 11 for(int i1 = 0; i1 < 3; i1++) 12 w1.push_back(i1+1); 13 w2 = w1; 14 printf("w1 %d %d %d\n", w1[0], w1[1], w1[2]); 15 printf("w2 %d %d %d\n", w2[0], w2[1], w2[2]); 16 printf(" 変更後\n"); 17 w1[1] = 4; 18 w2[0] = 0; 19 printf("w1 %d %d %d\n", w1[0], w1[1], w1[2]); 20 printf("w2 %d %d %d\n", w2[0], w2[1], w2[2]); 22 printf(" 変更後(アドレス)\n"); 23 vector*w3 = &w1; 24 (*w3)[2] = 100; 25 printf("w1 %d %d %d\n", w1[0], w1[1], w1[2]); 26 printf("w3 %d %d %d\n", (*w3)[0], (*w3)[1], (*w3)[2]); 27 28 return 0; 29 } - 今まで述べた方法では,プログラムの実行時に,要素の削除,追加等を行うことができません( new 演算子を使用した場合は多少面倒であるが可能).しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,C++ 標準ライブラリ内の vector クラスを使用することによって実現できます.vector クラスにおいては,実行時に,必要な数だけのデータの追加,削除,変更等が可能です.また,13 行目のような代入も可能であり,w1 に含まれるすべてのデータがコピー(浅いコピー)され,w2 に記憶されます.w1 と w2 は独立した変数として働き,w1 のデータを変更しても w2 のデータは影響を受けません(逆も同様).
- ただし,23 行目のように,w1 のアドレスを ポインタ変数 w3 に代入した場合は,new 演算子を使用した配列の場合と同様(データの参照方法は異なりますが),w3 の値を変更すれば w1 の値も変化します(逆も同様).09 行目~ 26 行目内の出力文によって,以下に示すような結果が得られます.
変更前 w1 1 2 3 w2 1 2 3 変更後 w1 1 4 3 w2 0 2 3 変更後(アドレス) w1 1 4 100 w3 1 4 100
- 文字列
01 #include <stdio.h> 02 #include <iostream> 03 #include <string> 04 05 using namespace std; 06 07 int main() 08 { 09 // char str[4] = "abc"; 10 printf(" C++ の string(変更前)\n"); 11 string str1 = "abc", str2, str3 = "abc"; 12 str2 = str1; 13 cout << "str1 " << str1 << " str2 " << str2 << " str3 " << str3 << " str1==str2? " << (str1==str2) << " str1==str3? " << (str1==str3) << endl; 14 printf("str1 %08x str2 %08x str3 %08x\n", (unsigned)&str1, (unsigned)&str2, (unsigned)&str3); 15 printf(" C++ の string(変更後)\n"); 16 str1.erase(0, 1); // 最初の文字を削除 17 cout << "str1 " << str1 << " str2 " << str2 << endl; 18 19 return 0; 20 }- 09 行目
- C++ において,文字列は,文字型データの配列として扱われます.n 文字からなる文字列を記憶するためには,(n + 1) 個の文字型データからなる配列が必要になります.なぜなら,文字列の最後には,必ず,文字列の終わりを示す文字 '\0' が付加されるためです.例えば,09 行目のように記述されます.その操作等に関しては,先に述べた整数型の場合と同様ですので省略します.
- 10 行目~ 17 行目
- C++ 標準ライブラリ内の string クラスを使用することによっても,文字列を表現可能です.この場合は,12 行目に示すような代入も可能です.その際,str1 に記憶されている文字列の内容がコピーされ str2 に記憶されます.従って,16 行目のように,str1 の内容を変更しても,str2 の内容は変化しません(逆も同様).また,13 行目に対応する出力結果から明らかなように,== 演算子によって,文字列自体の比較を行ってくれます.10 行目~ 17 行目内の出力文によって,以下に示すような結果が得られます.
C++ の string(変更前) str1 abc str2 abc str3 abc str1==str2? 1 str1==str3? 1 str1 0061feb8 str2 0061fed0 str3 0061fee8 C++ の string(変更後) str1 bc str2 abc
- クラスのオブジェクト
01 #include <stdio.h> 02 03 class Example 04 { 05 public: 06 int x1, x2; 07 int y[3]; 08 int *z; 09 Example () {} 10 Example (int xx1, int xx2) 11 { 12 x1 = xx1; 13 x2 = xx2; 14 for (int i1 = 0; i1 < 3; i1++) 15 y[i1] = 10 * (i1 + 1); 16 z = new int [3]; 17 for (int i1 = 0; i1 < 3; i1++) 18 z[i1] = 100 * (i1 + 1); 19 } 20 }; 21 22 int main() 23 { 24 // オブジェクト 25 printf(" ***オブジェクト***\n"); 26 printf(" 変更前\n"); 27 Example t1(1, 2); 28 Example t2(1, 2); 29 Example t3 = t1; 30 printf("t1 %08x t2 %08x t3 %08x\n", (unsigned)&t1, (unsigned)&t2, (unsigned)&t3); 31 printf("t1.x %d %d\n", t1.x1, t1.x2); 32 printf("t2.x %d %d\n", t2.x1, t2.x2); 33 printf("t3.x %d %d\n", t3.x1, t3.x2); 34 printf("t1.y %d %d %d\n", t1.y[0], t1.y[1], t1.y[2]); 35 printf("t2.y %d %d %d\n", t2.y[0], t2.y[1], t2.y[2]); 36 printf("t3.y %d %d %d\n", t3.y[0], t3.y[1], t3.y[2]); 37 printf("t1.z %d %d %d\n", t1.z[0], t1.z[1], t1.z[2]); 38 printf("t2.z %d %d %d\n", t2.z[0], t2.z[1], t2.z[2]); 39 printf("t3.z %d %d %d\n", t3.z[0], t3.z[1], t3.z[2]); 40 printf(" 変更後\n"); 41 t2.x1 = 8; 42 t2.y[1] = 80; 43 t2.z[1] = 800; 44 t3.x2 = 9; 45 t3.y[2] = 90; 46 t3.z[2] = 900; 47 printf("t1.x %d %d\n", t1.x1, t1.x2); 48 printf("t2.x %d %d\n", t2.x1, t2.x2); 49 printf("t3.x %d %d\n", t3.x1, t3.x2); 50 printf("t1.y %d %d %d\n", t1.y[0], t1.y[1], t1.y[2]); 51 printf("t2.y %d %d %d\n", t2.y[0], t2.y[1], t2.y[2]); 52 printf("t3.y %d %d %d\n", t3.y[0], t3.y[1], t3.y[2]); 53 printf("t1.z %d %d %d\n", t1.z[0], t1.z[1], t1.z[2]); 54 printf("t2.z %d %d %d\n", t2.z[0], t2.z[1], t2.z[2]); 55 printf("t3.z %d %d %d\n", t3.z[0], t3.z[1], t3.z[2]); 56 // オブジェクト(new演算子) 57 printf(" ***オブジェクト(new演算子)***\n"); 58 printf(" 変更前\n"); 59 Example *p1 = new Example(1, 2); 60 Example *p2 = new Example(1, 2); 61 Example *p3 = p1; 62 printf("p1 %08x p2 %08x p3 %08x\n", (unsigned)p1, (unsigned)p2, (unsigned)p3); 63 printf("p1.x %d %d\n", p1->x1, p1->x2); 64 printf("p2.x %d %d\n", p2->x1, p2->x2); 65 printf("p3.x %d %d\n", p3->x1, p3->x2); 66 printf("p1.y %d %d %d\n", p1->y[0], p1->y[1], p1->y[2]); 67 printf("p2.y %d %d %d\n", p2->y[0], p2->y[1], p2->y[2]); 68 printf("p3.y %d %d %d\n", p3->y[0], p3->y[1], p3->y[2]); 69 printf("p1.z %d %d %d\n", p1->z[0], p1->z[1], p1->z[2]); 70 printf("p2.z %d %d %d\n", p2->z[0], p2->z[1], p2->z[2]); 71 printf("p3.z %d %d %d\n", p3->z[0], p3->z[1], p3->z[2]); 72 printf(" 変更後\n"); 73 p1->x1 = 8; 74 p1->y[1] = 80; 75 p1->z[1] = 800; 76 p3->x2 = 9; 77 p3->y[2] = 90; 78 p3->z[2] = 900; 79 printf("p1.x %d %d\n", p1->x1, p1->x2); 80 printf("p2.x %d %d\n", p2->x1, p2->x2); 81 printf("p3.x %d %d\n", p3->x1, p3->x2); 82 printf("p1.y %d %d %d\n", p1->y[0], p1->y[1], p1->y[2]); 83 printf("p2.y %d %d %d\n", p2->y[0], p2->y[1], p2->y[2]); 84 printf("p3.y %d %d %d\n", p3->y[0], p3->y[1], p3->y[2]); 85 printf("p1.z %d %d %d\n", p1->z[0], p1->z[1], p1->z[2]); 86 printf("p2.z %d %d %d\n", p2->z[0], p2->z[1], p2->z[2]); 87 printf("p3.z %d %d %d\n", p3->z[0], p3->z[1], p3->z[2]); 88 89 return 0; 90 }- 25 行目~ 55 行目
- ここでは,クラスのインスタンス(オブジェクト)について検討していきます.基本的に,先に述べた vector クラスの場合と同じですが,もう少し詳しく述べておきます.クラスとは,03 行目~ 20 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,2 つの整数型データ x1,x2,整数型を要素とする配列 y,同じく整数型データを要素とする new 演算子を使用した配列 z から構成されています.27 行目,28 行目によって生成されたオブジェクト t1,t2 は,値は同じであっても,全く別のオブジェクトになります.また,29 行目では,t1 の内容をすべてコピーし,それを t3 に記憶しています.30 行目~ 39 行目内の出力文によって,以下に示すような結果が得られます.1 行目における各変数のアドレスから,値は同じであっても,t1,t2,t3 が全く別のオブジェクトであることが分かると思います.
t1 0091fe58 t2 0091fe38 t3 0091fe18 t1.x 1 2 t2.x 1 2 t3.x 1 2 t1.y 10 20 30 t2.y 10 20 30 t3.y 10 20 30 t1.z 100 200 300 t2.z 100 200 300 t3.z 100 200 300
- 下に示す 47 行目~ 55 行目による出力結果から,44 行目,45 行目において,t3 の x2,y[2] の値を変更しても,対応する t1 の値は全く変化しないことが分かります(逆も同様).ただし,46 行目において t3 の z[2] を変更すると,t1 の z[2] も変化します(逆も同様).これは,29 行目の代入文によっては,配列 y は値を含めてすべてコピーされますが,z が new 演算子を使用して作成された配列のため,そのアドレスだけがコピーされるためです.つまり,浅いコピーによりアドレスが指すデータ領域がコピーされず,t1 の z と t3 の z が同じ場所を指しているためです.しかし,全体における整合性を保ち,かつ,プログラムミングにおける誤りを避けるためには,z が指すデータ部分もコピーして代入するように,仕様を変更すべきではないでしょうか.
t1.x 1 2 t2.x 8 2 t3.x 1 9 t1.y 10 20 30 t2.y 10 80 30 t3.y 10 20 90 t1.z 100 200 900 t2.z 100 800 300 t3.z 100 200 900
- 57 行目~ 87 行目
- 次に,new 演算子を使用して生成されたオブジェクトのアドレスを記憶する方法について考えてみます.先の場合と同様,p1 と p2 は,全く別のオブジェクトであり,片方の値を変更しても,他のオブジェクトは全く影響を受けません.しかし,p3 は,61 行目に示すように,p1 のアドレスをコピーして記憶したものです.下に示す 57 行目~ 87 行目内の出力文による出力結果の 3 行目に示すように,p1 と p3 は,同じオブジェクトを指しています.従って,p3 を介してオブジェクトの値を変更すれば,p1 の値も変化します(逆も同様).C++ においては,この例に見るように,インスタンスを生成する方法として,27 行目,28 行目に示す方法と 59 行目,60 行目に示す方法とは明確に区別されています.つまり,new 演算子を使用する場合は,ポインタ変数だけに代入できます.しかし,他の言語においては,ここで述べた new 演算子を使用した方法と似た方法を使用しているにもかかわらず,ポインタ変数が存在しないため,27 行目,28 行目と同じように見えてしまいます.そのため,61 行目の代入文を基本データ型の代入文と同じようにとらえ,p3 を変化させても p1 には何の影響も与えないと考えがちです.十分注意してください.
***オブジェクト(new演算子)*** 変更前 p1 00030e20 p2 00030e58 p3 00030e20 p1.x 1 2 p2.x 1 2 p3.x 1 2 p1.y 10 20 30 p2.y 10 20 30 p3.y 10 20 30 p1.z 100 200 300 p2.z 100 200 300 p3.z 100 200 300 変更後 p1.x 8 9 p2.x 1 2 p3.x 8 9 p1.y 10 80 90 p2.y 10 20 30 p3.y 10 80 90 p1.z 100 800 900 p2.z 100 200 300 p3.z 100 800 900
- Java
- 整数型
01 import java.io.*; 02 03 public class Test { 04 public static void main(String args[]) throws IOException 05 { 06 int ia, ib, ic; // Integer ia, ib, ic; 07 ia = 10; // ia = new Integer(10); 08 ib = 10; // ib = new Integer(10); 09 ic = ia; 10 System.out.printf(" ***int***\n"); 11 System.out.printf("ia %d ib %d ic %d\n", ia, ib, ic); 12 ic = 20; // ic = new Integer(20); 13 System.out.printf("ia %d ib %d ic %d\n", ia, ib, ic); 14 } 15 }- 整数型のデータに対して,記憶と変更の問題を検討したプログラムです.07 行目~ 09 行目の記述によって,変数 ia 及び ib には 10 という値が記憶され,変数 ic には変数 ia に記憶されている値のコピーが記憶されます.従って,11 行目の出力文によって,以下に示すような出力が得られます.
ia 10 ib 10 ic 10
- 12 行目において,変数 ic に記憶しているデータを変更しています.09 行目の記述があっても,ia と ic は異なる変数ですので,各々独立に変化します.従って,13 行目の出力文によって,下に示すような結果が得られます.予想したとおりの結果だと思います.以上の結果を概念的に図示すればその下に示す図のようになります.なお,06 ~ 08 行目,12 行目のコメントに記したように Integer クラスを利用した場合も,同様の結果が得られます.
ia 10 ib 10 ic 20

- 浮動小数点型,文字型,文字列型
01 import java.io.*; 02 03 public class Test { 04 public static void main(String args[]) throws IOException 05 { 06 // double 07 double da, db, dc; 08 da = 10.5; 09 db = 10.5; 10 dc = da; 11 System.out.printf(" ***double***\n"); 12 System.out.printf("da %f db %f dc %f\n", da, db, dc); 13 dc = 20.5; 14 System.out.printf("da %f db %f dc %f\n", da, db, dc); 15 // 文字 16 char ca, cb, cc; 17 ca = 'a'; 18 cb = 'a'; 19 cc = ca; 20 System.out.printf(" ***文字***\n"); 21 System.out.printf("ca %c cb %c cc %c\n", ca, cb, cc); 22 cc = 'x'; 23 System.out.printf("ca %c cb %c cc %c\n", ca, cb, cc); 24 // 文字列 25 System.out.printf(" ***文字列***\n"); 26 String str1 = "abc", str2 = "abc", str3; 27 str3 = str1; 28 System.out.printf("str1 %s str2 %s str3 %s\n", str1, str2, str3); 29 str3 = "xyz"; 30 System.out.printf("str1 %s str2 %s str3 %s\n", str1, str2, str3); 31 } 32 }- 07 行目~ 14 行目
- 浮動小数点型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
da 10.500000 db 10.500000 dc 10.500000 da 10.500000 db 10.500000 dc 20.500000
- 16 行目~ 23 行目
- 文字型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
ca a cb a cc a ca a cb a cc x
- 25 行目~ 30 行目
- 文字列型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
str1 abc str2 abc str3 abc str1 abc str2 abc str3 xyz
- 1 次元配列
01 import java.io.*; 02 03 public class Test { 04 public static void main(String args[]) throws IOException 05 { 06 System.out.printf(" 変更前(1次元)\n"); 07 int u1[] = {1, 2, 3}, u2[] = {1, 2, 3}, u3[], u4[]; 08 u3 = u1; 09 u4 = u1.clone(); 10 Ex x1 = new Ex(1); 11 Ex x2 = new Ex(2); 12 Ex u5[] = {x1, x2}, u6[]; 13 u6 = u5.clone(); 14 System.out.printf("u1 %d %d %d\n", u1[0], u1[1], u1[2]); 15 System.out.printf("u2 %d %d %d\n", u2[0], u2[1], u2[2]); 16 System.out.printf("u3 %d %d %d\n", u3[0], u3[1], u3[2]); 17 System.out.printf("u4 %d %d %d\n", u4[0], u4[1], u4[2]); 18 System.out.printf("u5 %d, %d\n", u5[0].x, u5[1].x); 19 System.out.printf("u6 %d, %d\n", u6[0].x, u6[1].x); 20 System.out.printf(" 変更後(1次元)\n"); 21 u3[1] = 4; 22 u4[2] = 5; 23 u6[0] = new Ex(6); 24 u6[1].x = 7; 25 System.out.printf("u1 %d %d %d\n", u1[0], u1[1], u1[2]); 26 System.out.printf("u2 %d %d %d\n", u2[0], u2[1], u2[2]); 27 System.out.printf("u3 %d %d %d\n", u3[0], u3[1], u3[2]); 28 System.out.printf("u4 %d %d %d\n", u4[0], u4[1], u4[2]); 29 System.out.printf("u5 %d, %d\n", u5[0].x, u5[1].x); 30 System.out.printf("u6 %d, %d\n", u6[0].x, u6[1].x); 31 } 32 } 33 34 class Ex 35 { 36 int x; 37 Ex () {} 38 Ex (int x) 39 { 40 this.x = x; 41 } 42 }- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.例えば,
int x[] = new int [3]; int y[] = {1, 2, 3};- の 1 行目のように宣言すれば,3 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.2 行目においても,3 つの整数型データを記憶できる領域が確保される点では同じですが,各要素に記憶される値が 1,2,3 で初期設定されます.
- プログラムの 07 行目においては,同じ整数値で初期設定された 2 つの配列 u1,u2 と,配列変数であることだけを宣言した変数 u3,u4 を定義しています.つまり,整数型における 06 行目~ 08 行目の処理とほぼ同じことを行っています.そして,08 行目の文は,整数型における 09 行目に対応します.また,09 行目においては,メソッド clone (浅いコピーを実行)を利用して,u1 のクローンを u4 に代入しています.さらに,12 行目においては,クラス Ex ( 34 行目~ 42 行目)のオブジェクトを要素とする配列 u5,u6 を定義し,13 行目において u5 のクローンを u6 に代入しています.この結果,14 行目~ 19 行目の出力文によって,以下に示すような結果が出力されます.
u1 1 2 3 u2 1 2 3 u3 1 2 3 u4 1 2 3 u5 1, 2 u6 1, 2
- 21 行目~ 24 行目は,要素に記憶されている値を変更する処理であり,整数型における 12 行目に相当します.今までの考え方からすれば,u3[1],u4[2],u6[0],及び,u[6].x の値だけが変化し,他の変数は一切影響を受けないはずです.しかし,25 行目~ 30 行目の出力文によって出力される結果,
u1 1 4 3 u2 1 2 3 u3 1 4 3 u4 1 2 5 u5 1, 7 u6 6, 7
- を見てください.u4 の変更によって他の変数は何の影響も受けませんが,u3 の変更によって u1[1] も変化していることが分かります.これは,C++ における new 演算子を使用した 1 次元配列の場合と同様,u1,u2,u3,u4 がポインタ変数であると考えると当然の結果です.08 行目によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているからです.07 行目~ 08 行目による結果を概念的に示せば以下のようになります.
- u4 においては,u1 の各要素に記憶されている値が u4 の各要素にコピーされ,u1 と u4 は別の配列になります.そのため,u4 の要素の値を変更しても u1 には影響を及ぼしません.しかし,u5,u6 に対する結果を見てください.u6 は,u5 のクローンですから,u1 と u4 の関係と同じになるはずです.確かに,23 行において u6[0] の値を変更しても u5 には何の影響も与えていません.しかし,24 行目において u6[1].x の値を変更すると,u5[1].x の値も変化してしまいます.これは,クローンの生成が浅いコピーに基づいているが故に起きる現象です.u5 のクローンを生成する際に,u5 の各要素に記憶されている値,つまり,クラス Ex のオブジェクトに対するアドレスを u6 にコピーします.浅いコピーのため,そのアドレスが指すデータまではコピーされません.その結果,クローンが生成された時点においては,u5 と u6 の各要素は同じクラス Ex のオブジェクトを指していることになり,u6[1].x の値を変更すると,u5[1].x の値も変化することになります.ただし,23 行における u6[0] の変更は,要素に記憶されているアドレス自身の変更となり,u5 の値には影響を及ぼしません.
- 2 次元配列
01 import java.io.*; 02 03 public class Test { 04 public static void main(String args[]) throws IOException 05 { 06 System.out.printf(" 変更前(多次元)\n"); 07 int v1[][] = {{10, 20, 30}, {40, 50, 60}}, v2[][] = {{10, 20, 30}, {40, 50, 60}}, v3[][], v4[][]; 08 v3 = v1; 09 v4 = v1.clone(); 10 System.out.printf("v1 %d %d %d\n", v1[0][0], v1[0][1], v1[0][2]); 11 System.out.printf(" %d %d %d\n", v1[1][0], v1[1][1], v1[1][2]); 12 System.out.printf("v2 %d %d %d\n", v2[0][0], v2[0][1], v2[0][2]); 13 System.out.printf(" %d %d %d\n", v2[1][0], v2[1][1], v2[1][2]); 14 System.out.printf("v3 %d %d %d\n", v3[0][0], v3[0][1], v3[0][2]); 15 System.out.printf(" %d %d %d\n", v3[1][0], v3[1][1], v3[1][2]); 16 System.out.printf("v4 %d %d %d\n", v4[0][0], v4[0][1], v4[0][2]); 17 System.out.printf(" %d %d %d\n", v4[1][0], v4[1][1], v4[1][2]); 18 System.out.printf(" 変更後(多次元)\n"); 19 v1[0][1] = 70; 20 int vp1[] = v1[0]; 21 int vp2[] = v1[1]; 22 vp1[0] = 80; 23 vp2[2] = 90; // vp1[5] = 90; は許されない 24 v3[0][2] = 100; 25 v4[1][1] = 200; 26 System.out.printf("v1 %d %d %d\n", v1[0][0], v1[0][1], v1[0][2]); 27 System.out.printf(" %d %d %d\n", v1[1][0], v1[1][1], v1[1][2]); 28 System.out.printf("v2 %d %d %d\n", v2[0][0], v2[0][1], v2[0][2]); 29 System.out.printf(" %d %d %d\n", v2[1][0], v2[1][1], v2[1][2]); 30 System.out.printf("v3 %d %d %d\n", v3[0][0], v3[0][1], v3[0][2]); 31 System.out.printf(" %d %d %d\n", v3[1][0], v3[1][1], v3[1][2]); 32 System.out.printf("v4 %d %d %d\n", v4[0][0], v4[0][1], v4[0][2]); 33 System.out.printf(" %d %d %d\n", v4[1][0], v4[1][1], v4[1][2]); 34 } 35 }- 多次元の配列を扱うことも可能です.例えば,07 行目の記述によって 2 行 3 列の表に対応する配列 v1,v2 が生成されます.v3,v4 に対しては,2 次元配列であることだけを宣言していますが,08,09 行目の記述によって,v3,v4 も,v1 と同じ 2 行 3 列の配列になります.そのイメージは,C++ における new 演算子を使用した 2 次元配列の場合と同様,以下のようになります.
- 19 行目~ 25 行目において,v1,v3,及び,v4 の値を変更していますが,v1 と v3 は,同じ領域を指しているため,v1 の値を変更すれば v3 の値も変化します(逆も同様).v4 は,v1 のクローンですが,浅いコピーであるため,v1[i] を v4[i] にコピーするだけであり,v1[i] と v4[i] は,同じデータ v1[i][j] を指すことになります.そのため,v1[i][j] の値を変更すれば,v4[i][j] ( v1[i][j] と同じもの)の値も変化します.また,20 行目~ 23 行目に示すように,各行を 1 次元配列として扱うことも可能ですが,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません( 23 行目参照).06 行目~ 33 行目内の出力文によって,以下に示すような結果が得られます.
変更前(多次元) v1 10 20 30 40 50 60 v2 10 20 30 40 50 60 v3 10 20 30 40 50 60 v4 10 20 30 40 50 60 変更後(多次元) v1 80 70 100 40 200 90 v2 10 20 30 40 50 60 v3 80 70 100 40 200 90 v4 80 70 100 40 200 90
- ArrayList クラス
01 import java.io.*; 02 import java.util.*; 03 04 public class Test { 05 public static void main(String args[]) throws IOException 06 { 07 System.out.printf(" 変更前\n"); 08 ArrayList <Integer> w1, w2, w3, w4; 09 w1 = new ArrayList <Integer> (); 10 for(int i1 = 0; i1 < 3; i1++) 11 w1.add(new Integer(i1+1)); 12 w2 = w1; 13 w3 = new ArrayList <Integer> (w1); 14 w4 = listCast(w1.clone()); 15 // w4 = (ArrayList <Integer>)w1.clone(); 16 System.out.print("w1"); 17 for(int i1 = 0; i1 < 3; i1++) 18 System.out.print(" " + w1.get(i1)); 19 System.out.println(); 20 System.out.print("w2"); 21 for(int i1 = 0; i1 < 3; i1++) 22 System.out.print(" " + w2.get(i1)); 23 System.out.println(); 24 System.out.print("w3"); 25 for(int i1 = 0; i1 < 3; i1++) 26 System.out.print(" " + w3.get(i1)); 27 System.out.println(); 28 System.out.print("w4"); 29 for(int i1 = 0; i1 < 3; i1++) 30 System.out.print(" " + w4.get(i1)); 31 System.out.println(); 32 System.out.printf(" 変更後\n"); 33 w1.set(1, 4); 34 w2.set(0, 0); 35 w3.set(2, 5); 36 w4.set(2, 6); 37 System.out.print("w1"); 38 for(int i1 = 0; i1 < 3; i1++) 39 System.out.print(" " + w1.get(i1)); 40 System.out.println(); 41 System.out.print("w2"); 42 for(int i1 = 0; i1 < 3; i1++) 43 System.out.print(" " + w2.get(i1)); 44 System.out.println(); 45 System.out.print("w3"); 46 for(int i1 = 0; i1 < 3; i1++) 47 System.out.print(" " + w3.get(i1)); 48 System.out.println(); 49 System.out.print("w4"); 50 for(int i1 = 0; i1 < 3; i1++) 51 System.out.print(" " + w4.get(i1)); 52 System.out.println(); 53 } 54 55 @SuppressWarnings("unchecked") 56 public static <Type> Type listCast(Object src) { 57 Type target = (Type)src; 58 return target; 59 } 60 }- 今まで述べた方法では,プログラムの実行時に,要素の追加,削除等を行うことができません.しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,ArrayList クラスや Vector クラスを使用することによって実現できます.ArrayList クラスや Vector クラスにおいては,実行時に,必要な数だけのデータを追加,削除,変更等が可能です.C++ における vector クラスを使用した場合と似ていますが,配列の場合と同様,12 行目の代入文によってアドレスが記憶されるため,w1 の要素の値を変更すると w2 に対する値も変化します(逆も同様).しかし,13 行目のように,w1 を引数として新しい ArrayList クラスのオブジェクト w3 を生成した場合や,14 行目のように,w1 のクローンを w4 に代入した場合は,w1,w3,w4 は ArrayList クラスの異なるオブジェクトとして動作します.ただし,この例における ArrayList クラス は,Integer クラスのオブジェクトを要素とし,かつ,w4 は w1 の浅いコピーである点に注意してください( 1 次元配列に対する説明を参照).07 行目~ 52 行目内の出力文によって,以下に示すような結果が得られます.
変更前 w1 1 2 3 w2 1 2 3 w3 1 2 3 w4 1 2 3 変更後 w1 0 4 3 w2 0 4 3 w3 1 2 5 w4 1 2 6- なお,クローンを生成する場合,15 行目のような形でキャスティングを行うと,警告メッセージが出力されてしまいます.そこで,コレクション型のオブジェクトに対する自動型変換を行うメソッド listCast を定義し( 56 行目~ 59 行目),このメソッド内では警告を出さないようにしています( 55 行目).
- クラスのオブジェクト
01 import java.io.*; 02 03 public class Test { 04 public static void main(String args[]) throws IOException 05 { 06 System.out.printf(" 変更前\n"); 07 Example p1 = new Example(1, 2); 08 Example p2 = new Example(1, 2); 09 Example p3 = p1; 10 System.out.printf("p1.x %d %d\n", p1.x1, p1.x2); 11 System.out.printf("p2.x %d %d\n", p2.x1, p2.x2); 12 System.out.printf("p3.x %d %d\n", p3.x1, p3.x2); 13 System.out.printf("p1.y %d %d %d\n", p1.y[0], p1.y[1], p1.y[2]); 14 System.out.printf("p2.y %d %d %d\n", p2.y[0], p2.y[1], p2.y[2]); 15 System.out.printf("p3.y %d %d %d\n", p3.y[0], p3.y[1], p3.y[2]); 16 System.out.printf(" 変更後\n"); 17 p3.x2 = 9; 18 p3.y[2] = 90; 19 System.out.printf("p1.x %d %d\n", p1.x1, p1.x2); 20 System.out.printf("p2.x %d %d\n", p2.x1, p2.x2); 21 System.out.printf("p3.x %d %d\n", p3.x1, p3.x2); 22 System.out.printf("p1.y %d %d %d\n", p1.y[0], p1.y[1], p1.y[2]); 23 System.out.printf("p2.y %d %d %d\n", p2.y[0], p2.y[1], p2.y[2]); 24 System.out.printf("p3.y %d %d %d\n", p3.y[0], p3.y[1], p3.y[2]); 25 } 26 } 27 28 class Example 29 { 30 int x1, x2; 31 int y[]; 32 Example () {} 33 Example (int xx1, int xx2) 34 { 35 x1 = xx1; 36 x2 = xx2; 37 y = new int [3]; 38 for (int i1 = 0; i1 < 3; i1++) 39 y[i1] = 10 * (i1 + 1); 40 } 41 }- 次に,クラスのインスタンス(オブジェクト)について検討していきます.クラスとは,28 行目~ 41 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,2 つの整数型データ x1,x2 と整数型を要素とする配列 y から構成されています.07 行目,08 行目によって生成されたオブジェクト p1,p2 は,値は同じであっても,全く別のオブジェクトになります.また,09 行目では,p1 の値をコピーし,それを p3 に記憶しています.以下に示す出力からも明らかなように,配列の場合と同様,C++ におけるクラスのオブジェクトの 57 行目~ 87 行目の内容に対応しており,p1,p2,p3 をポインタ変数として考えると理解しやすいと思います.元のオブジェクトと同じ内容の異なるオブジェクトを生成したいような場合は,ArrayList クラスの場合と同じように,元のオブジェクトを引数とするコンストラクタを作成する,クローンを生成する clone メソッドを作成する,などが必要になります.
変更前 p1.x 1 2 p2.x 1 2 p3.x 1 2 p1.y 10 20 30 p2.y 10 20 30 p3.y 10 20 30 変更後 p1.x 1 9 p2.x 1 2 p3.x 1 9 p1.y 10 20 90 p2.y 10 20 30 p3.y 10 20 90
- 整数型
- JavaScript
- JavaScript においては,他の言語と同じような出力文が存在しませんので,結果を文字列として変数 str に記憶しておき,それを 08 行目で定義されているテキストエリアに,
document.getElementById("tx").value = str;- という形で表示しています.プログラムは HTML ファイル内に組み込まれていますので,ここをクリックすれば,ブラウザによって,以下に示す全ての場合に対する出力結果を同時に見ることができます.また,ページのソースを表示すれば,JavaScript のソースプログラムも表示可能です.
- 整数型
01 <!DOCTYPE HTML> 02 <HTML> 03 <HEAD> 04 <TITLE>データ型</TITLE> 05 <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-8"> 06 </HEAD> 07 <BODY> 08 <DIV STYLE="text-align: center"><TEXTAREA TYPE="text" ID="tx" COLS="50" ROWS="10" STYLE="font-size: 120%"></TEXTAREA></DIV> 09 <SCRIPT TYPE="text/javascript"> 10 let ia = 10; 11 let ib = 10; 12 let ic = ia; 13 let str = " ***int***\n"; 14 str += "ia " + ia + " ib " + ib + " ic " + ic + "\n"; 15 ic = 20; 16 str += "ia " + ia + " ib " + ib + " ic " + ic + "\n"; 17 document.getElementById("tx").value = str; 18 </SCRIPT> 19 </BODY> 20 </HTML>- 整数型のデータに対して,記憶と変更の問題を検討したプログラムです.10 行目~ 12 行目の記述によって,変数 ia 及び ib には 10 という値が記憶され,変数 ic には変数 ia に記憶されている値のコピーが記憶されます.従って,14 行目の文によって,以下に示すような出力が得られます.
ia 10 ib 10 ic 10
- 15 行目において,変数 ic に記憶しているデータを変更しています.12 行目の記述があっても,ia と ic は異なる変数ですので,各々独立に変化します.従って,16 行目の文によって,下に示すような結果が得られます.予想したとおりの結果だと思います.以上の結果を概念的に図示すればその下に示す図のようになります.
ia 10 ib 10 ic 20
- 浮動小数点型,文字列型
01 <!DOCTYPE HTML> 02 <HTML> 03 <HEAD> 04 <TITLE>データ型</TITLE> 05 <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-8"> 06 </HEAD> 07 <BODY> 08 <DIV STYLE="text-align: center"><TEXTAREA TYPE="text" ID="tx" COLS="50" ROWS="10" STYLE="font-size: 120%"></TEXTAREA></DIV> 09 <SCRIPT TYPE="text/javascript"> 10 // double 11 let da = 10.5; 12 let db = 10.5; 13 let dc = da; 14 str += " ***double***\n"; 15 str += "da " + da + " db " + db + " dc " + dc + "\n"; 16 dc = 20.5; 17 str += "da " + da + " db " + db + " dc " + dc + "\n"; 18 // 文字列 19 let ca = "abc"; 20 let cb = "abc"; 21 let cc = ca; 22 str += " ***文字列***\n"; 23 str += "ca " + ca + " cb " + cb + " cc " + cc + "\n"; 24 cc = cc.replace(/a/, "x"); 25 str += "ca " + ca + " cb " + cb + " cc " + cc + "\n"; 26 27 document.getElementById("tx").value = str; 28 </SCRIPT> 29 </BODY> 30 </HTML>- 11 行目~ 17 行目
- 浮動小数点型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
da 10.500000 db 10.500000 dc 10.500000 da 10.500000 db 10.500000 dc 20.500000
- 19 行目~ 25 行目
- 文字列型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
ca abc cb abc cc abc ca abc cb abc cc xbc
- 1 次元配列
01 <!DOCTYPE HTML> 02 <HTML> 03 <HEAD> 04 <TITLE>データ型</TITLE> 05 <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-8"> 06 </HEAD> 07 <BODY> 08 <DIV STYLE="text-align: center"><TEXTAREA TYPE="text" ID="tx" COLS="50" ROWS="10" STYLE="font-size: 120%"></TEXTAREA></DIV> 09 <SCRIPT TYPE="text/javascript"> 10 let u1 = new Array(1, "abc", 2); 11 let u2 = new Array(1, "abc", 2); 12 let u3 = u1; 13 let str = " ***配列(1次元)***\n"; 14 str += " 変更前\n"; 15 str += "u1 " + u1[0] + " " + u1[1] + " " + u1[2] + "\n"; 16 str += "u2 " + u2[0] + " " + u2[1] + " " + u2[2] + "\n"; 17 str += "u3 " + u3[0] + " " + u3[1] + " " + u3[2] + "\n"; 18 str += " 変更後\n"; 19 u3[1] = 4; 20 str += "u1 " + u1[0] + " " + u1[1] + " " + u1[2] + "\n"; 21 str += "u2 " + u2[0] + " " + u2[1] + " " + u2[2] + "\n"; 22 str += "u3 " + u3[0] + " " + u3[1] + " " + u3[2] + "\n"; 23 24 document.getElementById("tx").value = str; 25 </SCRIPT> 26 </BODY> 27 </HTML>- 配列は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.例えば,
x = new Array(1, 2.3, "abc");
- のように宣言すれば,3 つのデータを記憶できる領域が確保され,各要素に記憶される値が 1,2.3,"abc" で初期設定されます.また,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.この例に示すように,各要素は,必ずしも,同じデータ型である必要はありません.しかし,間違いの元になる可能性がありますので,配列は,同じデータ型だけで構成するようにした方が良いと思います.また,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 10 行目,11 行目においては,同じ値で初期設定された 2 つの配列 u1,u2 を定義し,12 行目において u1 を u3 に代入しています.つまり,整数型における 10 行目~ 12 行目の処理とほぼ同じことを行っています.この結果,15 行目~ 17 行目の文によって,以下に示すような結果が出力されます.
u1 1 abc 2 u2 1 abc 2 u3 1 abc 2
- 19 行目は,要素に記憶されている値を変更する処理であり,整数型における 15 行目に相当します.今までの考え方からすれば,u3[1] の値だけが変化し,他の部分は一切影響を受けないはずです.しかし,20 行目~ 22 行目の文によって出力される結果,
u1 1 4 2 u2 1 abc 2 u3 1 4 2
- を見てください.u1[1] も変化していることが分かります.これは,C++ における new 演算子を使用した 1 次元配列の場合と同様,u1,u2,u3 がポインタ変数であると考えると当然の結果です.12 行目によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているからです.10 行目~ 12 行目,19 行目による結果を概念的に示せば以下のようになります.
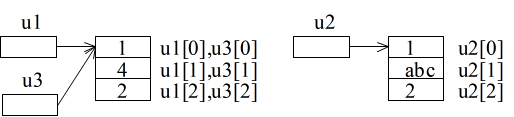
- 2 次元配列
01 <!DOCTYPE HTML> 02 <HTML> 03 <HEAD> 04 <TITLE>データ型</TITLE> 05 <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-8"> 06 </HEAD> 07 <BODY> 08 <DIV STYLE="text-align: center"><TEXTAREA TYPE="text" ID="tx" COLS="50" ROWS="10" STYLE="font-size: 120%"></TEXTAREA></DIV> 09 <SCRIPT TYPE="text/javascript"> 10 let str = " 変更前\n"; 11 let v1 = new Array(2); 12 v1[0] = new Array(10, 20, 30); 13 v1[1] = new Array(40, 50, 60); 14 let v2 = new Array(2); 15 v2[0] = new Array(10, 20, 30); 16 v2[1] = new Array(40, 50, 60); 17 let v3 = v1; 18 str += "v1 " + v1[0][0] + " " + v1[0][1] + " " + v1[0][2] + "\n"; 19 str += " " + v1[1][0] + " " + v1[1][1] + " " + v1[1][2] + "\n"; 20 str += "v2 " + v2[0][0] + " " + v2[0][1] + " " + v2[0][2] + "\n"; 21 str += " " + v2[1][0] + " " + v2[1][1] + " " + v2[1][2] + "\n"; 22 str += "v3 " + v3[0][0] + " " + v3[0][1] + " " + v3[0][2] + "\n"; 23 str += " " + v3[1][0] + " " + v3[1][1] + " " + v3[1][2] + "\n"; 24 str += " 変更後\n"; 25 v1[0][1] = 70; 26 let vp1 = v1[0]; 27 let vp2 = v1[1]; 28 vp1[0] = 80; 29 vp2[2] = 90; // vp1[5] = 90; は許されない 30 v3[0][2] = 100; 31 str += "v1 " + v1[0][0] + " " + v1[0][1] + " " + v1[0][2] + "\n"; 32 str += " " + v1[1][0] + " " + v1[1][1] + " " + v1[1][2] + "\n"; 33 str += "v2 " + v2[0][0] + " " + v2[0][1] + " " + v2[0][2] + "\n"; 34 str += " " + v2[1][0] + " " + v2[1][1] + " " + v2[1][2] + "\n"; 35 str += "v3 " + v3[0][0] + " " + v3[0][1] + " " + v3[0][2] + "\n"; 36 str += " " + v3[1][0] + " " + v3[1][1] + " " + v3[1][2] + "\n"; 37 38 document.getElementById("tx").value = str; 39 </SCRIPT> 40 </BODY> 41 </HTML>- 多次元の配列を扱うことも可能です.例えば,11 行目~ 13 行目,14 行目~ 16 行目のように,配列の要素を,さらに配列として定義すれば,2 次元の配列を定義できます.この例では,2 行 3 列の配列になります.17 行目の記述によって,v3 も,v1 と同じ 2 行 3 列の配列になります.そのイメージは,C++ における new 演算子を使用した 2 次元配列の場合と同様,以下のようになります.
- 25 行目~ 30 行目において,v1 及び v3 の値を変更していますが,v1 と v3 は,同じ領域を指しているため,v1 の値を変更すれば v3 の値も変化します(逆も同様).26 行目~ 29 行目に示すように,各行を 1 次元配列として扱うことも可能ですが,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません( 29 行目参照).10 行目~ 36 行目内の文によって,以下に示すような結果が得られます.
変更前 v1 10 20 30 40 50 60 v2 10 20 30 40 50 60 v3 10 20 30 40 50 60 変更後 v1 80 70 100 40 50 90 v2 10 20 30 40 50 60 v3 80 70 100 40 50 90- クラスとオブジェクト
01 <!DOCTYPE HTML> 02 <HTML> 03 <HEAD> 04 <TITLE>データ型</TITLE> 05 <META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=utf-8"> 06 </HEAD> 07 <BODY> 08 <DIV STYLE="text-align: center"><TEXTAREA TYPE="text" ID="tx" COLS="50" ROWS="10" STYLE="font-size: 120%"></TEXTAREA></DIV> 09 <SCRIPT TYPE="text/javascript"> 10 // オブジェクト 11 function Example(xx1, xx2) 12 { 13 this.x1 = xx1; 14 this.x2 = xx2; 15 this.y = new Array(10, 20, 30); 16 } 17 18 let p1 = new Example(1, 2); 19 let p2 = new Example(1, 2); 20 let p3 = p1; 21 let str = " ***オブジェクト***\n"; 22 str += " 変更前\n"; 23 str += "p1.x " + p1.x1 + " " + p1.x2 + "\n"; 24 str += "p2.x " + p2.x1 + " " + p2.x2 + "\n"; 25 str += "p3.x " + p3.x1 + " " + p3.x2 + "\n"; 26 str += "p1.y " + p1.y[0] + " " + p1.y[1] + " " + p1.y[2] + "\n"; 27 str += "p2.y " + p2.y[0] + " " + p2.y[1] + " " + p2.y[2] + "\n"; 28 str += "p3.y " + p3.y[0] + " " + p3.y[1] + " " + p3.y[2] + "\n"; 29 str += " 変更後\n"; 30 p1.x1 = 9; 31 p3.y[2] = 90; 32 str += "p1.x " + p1.x1 + " " + p1.x2 + "\n"; 33 str += "p2.x " + p2.x1 + " " + p2.x2 + "\n"; 34 str += "p3.x " + p3.x1 + " " + p3.x2 + "\n"; 35 str += "p1.y " + p1.y[0] + " " + p1.y[1] + " " + p1.y[2] + "\n"; 36 str += "p2.y " + p2.y[0] + " " + p2.y[1] + " " + p2.y[2] + "\n"; 37 str += "p3.y " + p3.y[0] + " " + p3.y[1] + " " + p3.y[2] + "\n"; 38 39 document.getElementById("tx").value = str; 40 </SCRIPT> 41 </BODY> 42 </HTML>- 次に,オブジェクトについて検討していきます.JavaScript のオブジェクトは,クラスから生成されるオブジェクトとは異なりますが,非常に似た概念です.オブジェクトは,11 行目~ 16 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,2 つの整数型データ x1,x2 と配列 y から構成されています.18 行目,19 行目によって生成されたオブジェクト p1,p2 は,値は同じであっても,全く別のオブジェクトになります.また,20 行目では,p1 の値をコピーし,それを p3 に記憶しています.以下に示す出力からも明らかなように,配列の場合と同様,C++ におけるクラスのオブジェクトの 57 行目~ 87 行目の内容に対応しており,p1,p2,p3 をポインタ変数として考えると理解しやすいと思います.
変更前 p1.x 1 2 p2.x 1 2 p3.x 1 2 p1.y 10 20 30 p2.y 10 20 30 p3.y 10 20 30 変更後 p1.x 9 2 p2.x 1 2 p3.x 9 2 p1.y 10 20 90 p2.y 10 20 30 p3.y 10 20 90
- PHP
- 整数型
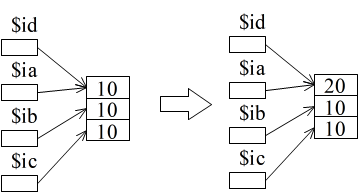
01 <?php 02 $ia = 10; 03 $ib = 10; 04 $ic = $ia; 05 $id = &$ia; 06 printf(" ***int***\n"); 07 printf("\$ia %d \$ib %d \$ic %d \$id %d\n", $ia, $ib, $ic, $id); 08 $ia = 20; 09 printf("\$ia %d \$ib %d \$ic %d \$id %d\n", $ia, $ib, $ic, $id); 10 ?>- 整数型のデータに対して,記憶と変更の問題を検討したプログラムです.02 行目~ 05 行目の記述によって,変数 $ia 及び $ib には 10 という値が記憶され,変数 $ic には変数 $ia に記憶されている値のコピーが記憶され,かつ,変数 $id には変数 $ia の参照(アドレス)記憶されます.従って,07 行目の文によって,以下に示すような出力が得られます.
$ia 10 $ib 10 $ic 10 $id 10
- 08 行目において,変数 $ia に記憶しているデータを変更しています.04 行目の記述があっても,$ia と $ic は異なる変数ですので,各々独立に変化します.しかし,$id は 変数 $ia の参照ですので,$ia の値を変更すれば $id の値も変化します(逆も同様).その結果,09 行目の文によって,下に示すような結果が得られます.予想したとおりの結果だと思います.以上の結果を概念的に図示すればその下に示す図のようになります.
$ia 20 $ib 10 $ic 10 $id 20
- 浮動小数点型,文字列型
01 <?php 02 // double 03 $da = 10.5; 04 $db = 10.5; 05 $dc = $da; 06 $dd = &$da; 07 printf(" ***double***\n"); 08 printf("\$da %f \$db %f \$dc %f \$dd %f\n", $da, $db, $dc, $dd); 09 $da = 20.5; 10 printf("\$da %f \$db %f \$dc %f \$dd %f\n", $da, $db, $dc, $dd); 11 // 文字列 12 $ca = "abc"; 13 $cb = "abc"; 14 $cc = $ca; 15 $cd = &$ca; 16 printf(" ***文字列***\n"); 17 printf("\$ca %s \$cb %s \$cc %s \$cd %s\n", $ca, $cb, $cc, $cd); 18 $ca = str_replace("a", "x", $ca); 19 printf("\$ca %s \$cb %s \$cc %s \$cd %s\n", $ca, $cb, $cc, $cd); 20 ?>- 03 行目~ 10 行目
- 浮動小数点型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
$da 10.500000 $db 10.500000 $dc 10.500000 $dd 10.500000 $da 20.500000 $db 10.500000 $dc 10.500000 $dd 20.500000
- 12 行目~ 19 行目
- 文字列型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
$ca abc $cb abc $cc abc $cd abc $ca xbc $cb abc $cc abc $cd xbc
- 1 次元配列
01 <?php 02 $u1 = array(1, "abc", 2); 03 $u2 = array(1, "abc", 2); 04 $u3 = $u1; 05 $u4 = &$u1; 06 $x1 = new Example1(1); 07 $x2 = new Example1(2); 08 $u5 = array($x1, $x2); 09 $u6 = $u5; 10 $u7 = &$u5; 11 printf(" 変更前\n"); 12 printf("\$u1 %d %s %d\n", $u1[0], $u1[1], $u1[2]); 13 printf("\$u2 %d %s %d\n", $u2[0], $u2[1], $u2[2]); 14 printf("\$u3 %d %s %d\n", $u3[0], $u3[1], $u3[2]); 15 printf("\$u4 %d %s %d\n", $u4[0], $u4[1], $u4[2]); 16 printf("\$u5 %d %d\n", $u5[0]->x, $u5[1]->x); 17 printf("\$u6 %d %d\n", $u6[0]->x, $u6[1]->x); 18 printf("\$u7 %d %d\n", $u7[0]->x, $u7[1]->x); 19 printf(" 変更後\n"); 20 $u1[2] = 4; 21 $u5[0] = new Example1(10); 22 $u5[1]->x = 20; 23 printf("\$u1 %d %s %d\n", $u1[0], $u1[1], $u1[2]); 24 printf("\$u2 %d %s %d\n", $u2[0], $u2[1], $u2[2]); 25 printf("\$u3 %d %s %d\n", $u3[0], $u3[1], $u3[2]); 26 printf("\$u4 %d %s %d\n", $u4[0], $u4[1], $u4[2]); 27 printf("\$u5 %d %d\n", $u5[0]->x, $u5[1]->x); 28 printf("\$u6 %d %d\n", $u6[0]->x, $u6[1]->x); 29 printf("\$u7 %d %d\n", $u7[0]->x, $u7[1]->x); 30 31 class Example1 32 { 33 public $x; 34 function Example1($x) 35 { 36 $this->x = $x; 37 } 38 } 39 ?>- 配列は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.例えば,
$x = array(1, 2.3, "abc");
- のように宣言すれば,3 つのデータを記憶できる領域が確保され,各要素に記憶される値が 1,2.3,"abc" で初期設定されます.また,変数名と添え字を利用して,$x[0],$x[1],$x[2] のようにして参照できます.この例に示すように,各要素は,必ずしも,同じデータ型である必要はありません.しかし,間違いの元になる可能性がありますので,配列は,同じデータ型だけで構成するようにした方が良いと思います.また,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 02 行目,03 行目においては,同じ値で初期設定された 2 つの配列 $u1,$u2 を定義し,04 行目において $u1 を $u3 に代入し,かつ,05 行目において $u1 の参照を $u4 に代入しています.また,06 行目~ 10 行目では,Example クラスのオブジェクトを要素とする $u5 を定義し,それを変数 $u6 に代入し,かつ,$u5 の参照を $u7 に代入しています.つまり,整数型における 02 行目~ 05 行目の処理とほぼ同じことを行っています.この結果,12 行目~ 18 行目の文によって以下に示すような出力が得られます.
$u1 1 abc 2 $u2 1 abc 2 $u3 1 abc 2 $u4 1 abc 2 $u5 1 2 $u6 1 2 $u7 1 2
- 20 行目において,$u1[2] の値を変更していますが,下に示す出力結果から明らかなように,整数型の場合と同様,$u3[2] の値は変化せず,参照を利用した $u4[2] の値は変化しています.これは,他の言語とは異なり,04 行目の代入文によって,$u1 のすべてのデータが $u3 にコピー(浅いコピー)され新しい配列が作成されたことを意味します.
- Example クラスのオブジェクトを要素とした場合においては,浅いコピーであるがために,各オブジェクトのアドレスがコピーされて新しい配列が生成されるため,$u5 と $u6 の各要素は同じオブジェクトを指すことになります.従って,その値(アドレス)を変更する 21 行目のような変更においては,変数 $u6 の値に影響を与えませんが,22 行目のような変更では,対応する変数 $u6 の要素の値も変化します.
$u1 1 abc 4 $u2 1 abc 2 $u3 1 abc 2 $u4 1 abc 4 $u5 10 20 $u6 1 20 $u7 10 20
- 2 次元配列
01 <?php 02 $v1 = array(2); 03 $v1[0] = array(10, 20, 30); 04 $v1[1] = array(40, 50, 60); 05 $v2 = array(2); 06 $v2[0] = array(10, 20, 30); 07 $v2[1] = array(40, 50, 60); 08 $v3 = $v1; 09 $v4 = &$v1; 10 printf(" 変更前\n"); 11 printf("\$v1 %d %d %d\n", $v1[0][0], $v1[0][1], $v1[0][2]); 12 printf(" %d %d %d\n", $v1[1][0], $v1[1][1], $v1[1][2]); 13 printf("\$v2 %d %d %d\n", $v2[0][0], $v2[0][1], $v2[0][2]); 14 printf(" %d %d %d\n", $v2[1][0], $v2[1][1], $v2[1][2]); 15 printf("\$v3 %d %d %d\n", $v3[0][0], $v3[0][1], $v3[0][2]); 16 printf(" %d %d %d\n", $v3[1][0], $v3[1][1], $v3[1][2]); 17 printf("\$v4 %d %d %d\n", $v4[0][0], $v4[0][1], $v4[0][2]); 18 printf(" %d %d %d\n", $v4[1][0], $v4[1][1], $v4[1][2]); 19 printf(" 変更後\n"); 20 $v1[0][0] = 70; 21 $v5 = $v1[0]; 22 $v5[1] = 80; 23 $v6 = &$v1[0]; 24 $v6[2] = 90; 25 printf("\$v1 %d %d %d\n", $v1[0][0], $v1[0][1], $v1[0][2]); 26 printf(" %d %d %d\n", $v1[1][0], $v1[1][1], $v1[1][2]); 27 printf("\$v2 %d %d %d\n", $v2[0][0], $v2[0][1], $v2[0][2]); 28 printf(" %d %d %d\n", $v2[1][0], $v2[1][1], $v2[1][2]); 29 printf("\$v3 %d %d %d\n", $v3[0][0], $v3[0][1], $v3[0][2]); 30 printf(" %d %d %d\n", $v3[1][0], $v3[1][1], $v3[1][2]); 31 printf("\$v4 %d %d %d\n", $v4[0][0], $v4[0][1], $v4[0][2]); 32 printf(" %d %d %d\n", $v4[1][0], $v4[1][1], $v4[1][2]); 33 printf("\$v5 %d %d %d\n", $v5[0], $v5[1], $v5[2]); 34 printf("\$v6 %d %d %d\n", $v6[0], $v6[1], $v6[2]); 35 ?>- 多次元の配列を扱うことも可能です.例えば,02 行目~ 04 行目,05 行目~ 07 行目のように,配列の要素を,さらに配列として定義すれば,2 次元の配列を定義できます.この例では,2 行 3 列の配列になります.08 行目においては,$v1 を $v3 に代入し,かつ,09 行目において $v1 の参照を $v4 に代入しています.通常の代入の場合は,1 次元配列の場合と同様,$v3 は,$v1 のすべての要素をコピーして,全く新しい配列として生成されます(浅いコピーの考え方から見ると奇妙).
- また,21 行目~ 24 行目に示すように,各行を 1 次元配列として扱うことも可能です.この場合も,1 次元配列の場合と同様,$v5 は,$v1 の 1 行目のすべての値をコピーした全く新しい配列となります.ただし,参照を利用した $v4 は,$v1 の 1 行目と同じ配列を指すことになります.その結果,10 行目~ 34 行目内の文によって,以下に示すような結果が得られます.
変更前 $v1 10 20 30 40 50 60 $v2 10 20 30 40 50 60 $v3 10 20 30 40 50 60 $v4 10 20 30 40 50 60 変更後 $v1 70 20 90 40 50 60 $v2 10 20 30 40 50 60 $v3 10 20 30 40 50 60 $v4 70 20 90 40 50 60 $v5 70 80 30 $v6 70 20 90
- クラスのオブジェクト
01 <?php 02 $p1 = new Example2(1, 2); 03 $p2 = new Example2(1, 2); 04 $p3 = $p1; 05 printf(" 変更前\n"); 06 printf("\$p1.x %d %d\n", $p1->x1, $p1->x2); 07 printf("\$p2.x %d %d\n", $p2->x1, $p2->x2); 08 printf("\$p3.x %d %d\n", $p3->x1, $p3->x2); 09 printf("\$p1.y %d %d %d\n", $p1->y[0], $p1->y[1], $p1->y[2]); 10 printf("\$p2.y %d %d %d\n", $p2->y[0], $p2->y[1], $p2->y[2]); 11 printf("\$p3.y %d %d %d\n", $p3->y[0], $p3->y[1], $p3->y[2]); 12 $p1->x1 = 9; 13 $p3->y[2] = 90; 14 printf(" 変更後\n"); 15 printf("\$p1.x %d %d\n", $p1->x1, $p1->x2); 16 printf("\$p2.x %d %d\n", $p2->x1, $p2->x2); 17 printf("\$p3.x %d %d\n", $p3->x1, $p3->x2); 18 printf("\$p1.y %d %d %d\n", $p1->y[0], $p1->y[1], $p1->y[2]); 19 printf("\$p2.y %d %d %d\n", $p2->y[0], $p2->y[1], $p2->y[2]); 20 printf("\$p3.y %d %d %d\n", $p3->y[0], $p3->y[1], $p3->y[2]); 21 22 class Example2 23 { 24 public $x1; 25 public $x2; 26 public $y; 27 function Example2($xx1, $xx2) 28 { 29 $this->x1 = $xx1; 30 $this->x2 = $xx2; 31 $this->y = array(10, 20, 30); 32 } 33 } 34 ?>- 次に,クラスのオブジェクト(インスタンス)について検討していきます.クラスは,22 行目~ 33 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,2 つの整数型データ $x1,$x2 と配列 $y から構成されています.02 行目,03 行目によって生成されたオブジェクト $p1,$p2 は,値は同じであっても,全く別のオブジェクトになります.また,04 行目では,$p1 の値をコピーし,それを $p3 に記憶しています.以下に示す出力からも明らかなように,C++ におけるクラスのオブジェクトの 57 行目~ 87 行目の内容に対応しており,$p1,$p2,$p3 をポインタ変数として考えると理解しやすいと思います.つまり,$p1 と $p3 は同じアドレスにあるデータを指しており,$p1 を介してデータを変更すれば,$p3 を介して参照するデータの値も同じように変化します(逆も同様).配列の扱いとクラスのオブジェクトの扱いの違いには,何か理由があるのでしょうか.
変更前 $p1.x 1 2 $p2.x 1 2 $p3.x 1 2 $p1.y 10 20 30 $p2.y 10 20 30 $p3.y 10 20 30 変更後 $p1.x 9 2 $p2.x 1 2 $p3.x 9 2 $p1.y 10 20 90 $p2.y 10 20 30 $p3.y 10 20 90
- Ruby
- 整数型,浮動小数点型
01 # int 02 ia = 10; 03 ib = 10; 04 ic = ia; 05 print " ***int***\n"; 06 print "ia ", ia, " ib ", ib, " ic ", ic, "\n"; 07 ic = 20; 08 print "ia ", ia, " ib ", ib, " ic ", ic, "\n"; 09 # double 10 da = 10.5; 11 db = 10.5; 12 dc = da; 13 print " ***double***\n"; 14 print "da ", da, " db ", db, " dc ", dc, "\n"; 15 dc = 20.5; 16 print "da ", da, " db ", db, " dc ", dc, "\n";
- 02 行目~ 08 行目
- 整数型のデータに対して,記憶と変更の問題を検討した部分です.02 行目~ 04 行目の記述によって,変数 ia 及び ib には 10 という値が記憶され,変数 ic には変数 ia に記憶されている値のコピーが記憶されます.従って,06 行目の出力文によって,以下に示すような出力が得られます.
ia 10 ib 10 ic 10
- 07 行目において,変数 ic に記憶しているデータを変更しています.04 行目の記述があっても,ia と ic は異なる変数ですので,各々独立に変化します.従って,08 行目の出力文によって,下に示すような結果が得られます.予想したとおりの結果だと思います.以上の結果を概念的に図示すればその下に示す図のようになります.
ia 10 ib 10 ic 20
- 10 行目~ 16 行目
- 浮動小数点型のデータに対して,02 行目~ 08 行目における整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
da 10.500000 db 10.500000 dc 10.500000 da 10.500000 db 10.500000 dc 20.500000
- 文字列型
01 ca = "abc"; 02 cb = "abc"; 03 cc = ca; 04 printf " ***文字列***\n"; 05 print "ca ", ca, " cb ", cb, " cc ", cc, "\n"; 06 cc = cc.replace("xbc"); 07 print "ca ", ca, " cb ", cb, " cc ", cc, "\n"; 08 cc = "ybc"; 09 print "ca ", ca, " cb ", cb, " cc ", cc, "\n";- 文字列型のデータに対して,整数型データに対する処理と同様のことを行っています.しかし,下に示す出力結果の 2 行目を見てください.06 行目において変数 cc の値だけを変更したにもかかわらず,変数 ca の値も変化しています.これは,ca や cb が文字列を記憶している場所を指すポインタ変数であり,03 行目の代入文によって,ca と cc が同じ文字列を指す結果になったものとして理解できます.しかし,08 行目のような代入文を使用すると,cc は,新しい文字列を指すことになり,ca の値は変化しません(出力の 3 行目).以上のことを概念的に示せば,出力結果の下に示す図のようになります.
ca abc cb abc cc abc ca xbc cb abc cc xbc ca xbc cb abc cc ybc

- 1 次元配列
01 class Example 02 def initialize(x) 03 @_x = x 04 end 05 attr("_x", true) 06 end 07 08 u1 = Array[1, "abc", 2]; 09 u2 = Array[1, "abc", 2]; 10 u3 = u1; 11 u4 = u1.clone; 12 x1 = Example.new(1); 13 x2 = Example.new(2); 14 u5 = Array[x1, x2]; 15 u6 = u5.clone; 16 print " ***配列(1次元)***\n"; 17 print " 変更前\n"; 18 print "u1 ", u1[0], " ", u1[1], " ", u1[2], "\n"; 19 print "u2 ", u2[0], " ", u2[1], " ", u2[2], "\n"; 20 print "u3 ", u3[0], " ", u3[1], " ", u3[2], "\n"; 21 print "u4 ", u4[0], " ", u4[1], " ", u4[2], "\n"; 22 print "u5 ", u5[0]._x, " ", u5[1]._x, "\n"; 23 print "u6 ", u6[0]._x, " ", u6[1]._x, "\n"; 24 print " 変更後\n"; 25 u3[1] = 4; 26 u4[2] = 5; 27 u6[0] = Example.new(0); 28 u6[0]._x = 6; 29 u6[1]._x = 7; 30 print "u1 ", u1[0], " ", u1[1], " ", u1[2], "\n"; 31 print "u2 ", u2[0], " ", u2[1], " ", u2[2], "\n"; 32 print "u3 ", u3[0], " ", u3[1], " ", u3[2], "\n"; 33 print "u4 ", u4[0], " ", u4[1], " ", u4[2], "\n"; 34 print "u5 ", u5[0]._x, " ", u5[1]._x, "\n"; 35 print "u6 ", u6[0]._x, " ", u6[1]._x, "\n";- 配列は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.Ruby においては Array クラスのインスタンスとして定義され,例えば,
x = Array[1, 2.3, "abc"];
- のように宣言すれば,3 つのデータを記憶できる領域が確保され,各要素に記憶される値が 1,2.3,"abc" で初期設定されます.また,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.この例に示すように,各要素は,必ずしも,同じデータ型である必要はありません.しかし,間違いの元になる可能性がありますので,配列は,同じデータ型だけで構成するようにした方が良いと思います.また,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 08 行目,09 行目においては,同じ値で初期設定された 2 つの配列 u1,u2 を定義し,10 行目において u1 を u3 に代入しています.つまり,整数型の 02 行目~ 04 行目の処理とほぼ同じことを行っています.11 行目においては,clone メソッドを利用して u1 のクローン(浅いコピー)を u4 に代入しています.さらに,12 行目~ 14 行目において,Example クラスのオブジェクトを要素とする配列 u5 を定義し,そのクローンを u6 に代入しています.この結果,18 行目~ 23 行目の文によって,以下に示すような結果が出力されます.
u1 1 abc 2 u2 1 abc 2 u3 1 abc 2 u4 1 abc 2 u5 1 2 u6 1 2
- 25 行目は,要素に記憶されている値を変更する処理であり,整数型における 07 行目に相当します.整数型のような考え方からすれば,u3[1] の値だけが変化し,他の部分は一切影響を受けないはずです.しかし,30 行目~ 35 行目の文によって出力される結果,
u1 1 4 2 u2 1 abc 2 u3 1 4 2 u4 1 abc 5 u5 1 7 u6 6 7
- を見てください.u1[1] も変化していることが分かります.これは,C++ における new 演算子を使用した 1 次元配列の場合と同様,u1,u2,u3 がポインタ変数であると考えると当然の結果です.08 行目によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているからです.08 行目~ 10 行目,25 行目による結果を概念的に示せば以下のようになります.
- ところが,u1 のクローンである u4 の値を変更しても( 26 行目),u1 は,その影響を受けません.クローン作成操作によって,u1 のすべてのデータが u4 にコピーされ新しい配列が作成されたことを意味します.しかし,Example クラスのオブジェクトを要素とした場合は,各オブジェクトのアドレスがコピーされて新しい配列が生成されるため,u5 と u6 の各要素は同じオブジェクトを指すことになります.従って,その値(アドレス)を変更する 27,28 行目のような変更においては,変数 u5 の値に影響を与えませんが,29 行目のような変更では,対応する変数 u5 の要素の値も変化します.
- 2 次元配列
01 print " 変更前\n"; 02 v1 = Array[[10, 20, 30], [40, 50, 60]]; 03 v2 = Array[[10, 20, 30], [40, 50, 60]]; 04 v3 = v1; 05 print "v1 ", v1[0][0], " ", v1[0][1], " ", v1[0][2], "\n"; 06 print " ", v1[1][0], " ", v1[1][1], " ", v1[1][2], "\n"; 07 print "v2 ", v2[0][0], " ", v2[0][1], " ", v2[0][2], "\n"; 08 print " ", v2[1][0], " ", v2[1][1], " ", v2[1][2], "\n"; 09 print "v3 ", v3[0][0], " ", v3[0][1], " ", v3[0][2], "\n"; 10 print " ", v3[1][0], " ", v3[1][1], " ", v3[1][2], "\n"; 11 print " 変更後\n"; 12 v1[0][1] = 70; 13 v3[0][2] = 100; 14 v4 = v1[0]; 15 v5 = v1[1]; 16 v4[0] = 200; 17 v5[2] = 300; # v4[5] = 300; は許されない 18 print "v1 ", v1[0][0], " ", v1[0][1], " ", v1[0][2], "\n"; 19 print " ", v1[1][0], " ", v1[1][1], " ", v1[1][2], "\n"; 20 print "v2 ", v2[0][0], " ", v2[0][1], " ", v2[0][2], "\n"; 21 print " ", v2[1][0], " ", v2[1][1], " ", v2[1][2], "\n"; 22 print "v3 ", v3[0][0], " ", v3[0][1], " ", v3[0][2], "\n"; 23 print " ", v3[1][0], " ", v3[1][1], " ", v3[1][2], "\n"; 24 print "v4 ", v4[0], " ", v4[1], " ", v4[2], "\n"; 25 print "v5 ", v5[0], " ", v5[1], " ", v5[2], "\n";
- 多次元の配列を扱うことも可能です.例えば,02 行目,03 行目のように定義すれば,2 次元の配列を定義できます.この例では,2 行 3 列の配列になります.04 行目の記述によって,v3 も,v1 と同じ値を持った 2 行 3 列の配列になります.そのイメージは,C++ における new 演算子を使用した 2 次元配列の場合と同様,以下のようになります.
- 12 行目,13 行目において,v1 及び v3 の値を変更していますが,v1 と v3 は,同じ領域を指しているため,v1 の値を変更すれば v3 の値も変化します(逆も同様).14 行目~ 17 行目に示すように,各行を 1 次元配列として扱うことも可能ですが,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを連続した 1 次元配列とみなして参照することはできません( 17 行目参照).なお,clone メソッドによって,v1 のクローンを v3 に代入しても,結果は同じになります.その理由は,clone メソッドが行うのは浅いコピーであり,上の図における v1[0],v1[1] を v3[0],v3[1] にコピーするだけで,それらのアドレスが指すデータはコピーされないからです.
変更前 v1 10 20 30 40 50 60 v2 10 20 30 40 50 60 v3 10 20 30 40 50 60 変更後 v1 200 70 100 40 50 300 v2 10 20 30 40 50 60 v3 200 70 100 40 50 300 v4 200 70 100 v5 40 50 300
- クラスのオブジェクト
01 class Example2; 02 def initialize(xx1, xx2); 03 @_x1 = xx1; 04 @_x2 = xx2; 05 @_y = [10, 20, 30]; 06 end; 07 def out(); 08 print @_x1, " ", @_x2, "\n"; 09 print @_y[0], " ", @_y[1], " ", @_y[2], "\n"; 10 end; 11 def set(); 12 @_x1 = 9; 13 @_y[2] = 90; 14 end; 15 end; 16 17 p1 = Example2.new(1, 2); 18 p2 = Example2.new(1, 2); 19 p3 = p1; 20 print " ***オブジェクト***\n"; 21 print " 変更前\n"; 22 print "p1 "; 23 p1.out; 24 print "p2 "; 25 p2.out; 26 print "p3 "; 27 p3.out; 28 print " 変更後\n"; 29 p1.set(); # 値の変更 30 print "p1 "; 31 p1.out; 32 print "p2 "; 33 p2.out; 34 print "p3 "; 35 p3.out;
- 次に,クラスのインスタンス(オブジェクト)について検討していきます.クラスとは,01 行目~ 15 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,2 つの整数型データ @_x1,@_x2 と整数型を要素とする配列 @_y から構成されています.17 行目,18 行目によって生成されたオブジェクト p1,p2 は,値は同じであっても,全く別のオブジェクトになります.また,19 行目では,p1 の値をコピーし,それを p3 に記憶しています.以下に示す出力からも明らかなように,配列の場合と同様,C++ におけるクラスのオブジェクトの 57 行目~ 87 行目の内容に対応しており,p1,p2,p3 をポインタ変数として考えると理解しやすいと思います.
変更後 p1 1 2 10 20 30 p2 1 2 10 20 30 p3 1 2 10 20 30 変更後 p1 9 2 10 20 90 p2 1 2 10 20 30 p3 9 2 10 20 90
- Python
- 整数型
01 # -*- coding: UTF-8 -*- 02 ia = 10 03 ib = 10 04 ic = ia 05 print(" ***int***") 06 print("ia", ia, "ib", ib, "ic", ic) 07 ic = 20 08 print("ia", ia, "ib", ib, "ic", ic)- 整数型のデータに対して,記憶と変更の問題を検討したプログラムです.02 行目~ 04 行目の記述によって,変数 ia 及び ib には 10 という値が記憶され,変数 ic には変数 ia に記憶されている値のコピーが記憶されます.従って,06 行目の出力文によって,以下に示すような出力が得られます.
ia 10 ib 10 ic 10
- 07 行目において,変数 ic に記憶しているデータを変更しています.04 行目の記述があっても,ia と ic は異なる変数ですので,各々独立に変化します.従って,08 行目の出力文によって,下に示すような結果が得られます.予想したとおりの結果だと思います.以上の結果を概念的に図示すればその下に示す図のようになります.
ia 10 ib 10 ic 20
- 浮動小数点型,文字列型
01 # -*- coding: UTF-8 -*- 02 # double 03 da = 10.5 04 db = 10.5 05 dc = da 06 print(" ***double***") 07 print("da", da, "db", db, "dc", dc) 08 dc = 20.5 09 print("da", da, "db", db, "dc", dc) 10 # 文字列 11 ca = "abc" 12 cb = "abc" 13 cc = ca 14 print(" ***文字列***") 15 print("ca", ca, "cb", cb, "cc", cc) 16 cc = cc.replace("a", "x") 17 print("ca", ca, "cb", cb, "cc", cc)- 03 行目~ 09 行目
- 浮動小数点型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
da 10.500000 db 10.500000 dc 10.500000 da 10.500000 db 10.500000 dc 20.500000
- 11 行目~ 17 行目
- 文字列型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
ca abc cb abc cc abc ca abc cb abc cc xbc
- 1 次元配列( array,list )
01 # -*- coding: UTF-8 -*- 02 import copy 03 from array import * 04 05 class Example : 06 def __init__(self, x) : 07 self.x = x 08 09 print(" (1次元,array,list,変更前)") 10 u1 = array("i", [1, 2, 3]) 11 u2 = array("i", [1, 2, 3]) 12 u3 = u1 13 u4 = copy.copy(u1) 14 x1 = Example(10) 15 x2 = Example(20) 16 x3 = Example(30) 17 u5 = [x1, x2, x3] 18 u6 = u5 19 u7 = copy.copy(u5) 20 u8 = copy.deepcopy(u5) 21 print("u1", u1[0], u1[1], u1[2]) 22 print("u2", u2[0], u2[1], u2[2]) 23 print("u3", u3[0], u3[1], u3[2]) 24 print("u4", u4[0], u4[1], u4[2]) 25 print("class u5", u5[0].x, u5[1].x, u5[2].x) 26 print("class u6", u6[0].x, u6[1].x, u6[2].x) 27 print("class u7", u7[0].x, u7[1].x, u7[2].x) 28 print("class u8", u8[0].x, u8[1].x, u8[2].x) 29 print(" (1次元,array,list,変更後)") 30 u3[1] = 4 31 u4[2] = 5 32 u6[1] = Example(40) 33 u6[2].x = 50 34 print("u1", u1[0], u1[1], u1[2]) 35 print("u2", u2[0], u2[1], u2[2]) 36 print("u3", u3[0], u3[1], u3[2]) 37 print("u4", u4[0], u4[1], u4[2]) 38 print("class u5", u5[0].x, u5[1].x, u5[2].x) 39 print("class u6", u6[0].x, u6[1].x, u6[2].x) 40 print("class u7", u7[0].x, u7[1].x, u7[2].x) 41 print("class u8", u8[0].x, u8[1].x, u8[2].x)- 配列( array )は,複合データ型の一種であり,複数のデータを処理する場合に利用されます.例えば,
x = array("i", [1, 2, 3]) y = [1, "abc", 2]- の 1 行目のように宣言すれば,1,2,3 で初期設定された 3 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.array は,"i" の部分で指定された同じデータ型の数値データだけを取り扱うことができますが,array とほぼ同じ機能を持った list では,2 行目に示すように,異なるデータ型を要素として持つことができます.また,いずれの場合においても,プログラムの実行時に,要素の追加,削除等を行うことが可能です.
- 10 行目,11 行目においては,同じ値で初期設定された 2 つの配列 u1,u2 を定義し,12 行目では,u1 を u3 に代入(記憶)しています.つまり,整数型データに対する処理と同様のことを行っています.また,13 行目においては,u1 の浅いコピーを u4 に代入しています.さらに,14 行目~ 17 行目においては,クラス Example のオブジェクトを要素とするリスト u5 を定義し,18 行目ではそれを u6 に代入,19 行目では u5 の浅いコピーを u7 に代入,また,20 行目では u5 の深いコピーを u8 に代入しています.この結果,21 行目~ 28 行目の出力文によって,以下に示すような結果が出力されます.
u1 1 2 3 u2 1 2 3 u3 1 2 3 u4 1 2 3 class u5 10 20 30 class u6 10 20 30 class u7 10 20 30 class u8 10 20 30
- 30 行目~ 33 行目は,要素に記憶されている値を変更する処理であり,整数型における 07 行目に相当します.今までの考え方からすれば,u3[1],u4[2],u6[1],u6[2] の値だけが変化し,他の部分は一切影響を受けないはずです.しかし,34 行目~ 37 行目の出力文によって出力される結果を見てください.
u1 1 4 3 u2 1 2 3 u3 1 4 3 u4 1 2 5
- u3[1] の変更によって,u1[1] も変化していることが分かります.これは,C++ における new 演算子を使用した 1 次元配列の場合と同様,u1 ~ u4 がポインタ変数であると考えると当然の結果です.12 行目によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているからです.しかし,浅いコピーを使用した u4 に関しては,u4[2] だけが変化しています.これは,08 行目の浅いコピーによって,アドレスだけでなく,アドレスが指している値(配列の各要素の値)もコピーされ,u4 に記憶されたからです.10 行目~ 13 行目,30 行目,31 行目による結果を概念的に示せば以下のようになります( u2 に関する部分は除く).
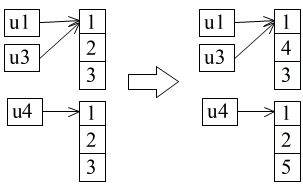
- list に関しても,基本的に,array の場合と同じような結果になります.しかし,u5 ~ u8 は,Example クラスのオブジェクトを要素としています.そのため,多少異なった結果になります.下に示す 38 行目~ 41 行目の出力文によって出力される結果を見てください.u6 の各要素の値を変更すれば,u5 の値も変化しますが,u7 は,u5 の浅いコピーであるため,その影響を受けないはずです.しかし,u7[2] の値も変化しています.オブジェクトを要素とした場合,各要素にはオブジェクトに対するアドレスが記憶されています.浅いコピーは,元の配列( list )の各要素の値(アドレス)をコピーして新しい配列( list )を生成します.その際,アドレスが指すオブジェクト自身はコピーされません.そのため,u5 と u6 の各要素は,同じオブジェクトを指すことになります.32 行目のように,新しいオブジェクト(のアドレス)を代入した場合,u7 はその影響を受けませんが,33 行目のような変更は,u5[2],u6[2],u7[2] が同じオブジェクトを指しているため,u5[2],u7[2] の値も変化します.このようなことを避けるためには,20 行目のような深いコピーを行い,アドレスだけでなくそのアドレスが指すオブジェクトもコピーしてやる必要があります.なお,深いコピーに関しては,2 次元配列に対する説明も参考にしてください.
class u5 10 40 50 class u6 10 40 50 class u7 10 20 50 class u8 10 20 30
- 2 次元配列( array )
01 # -*- coding: UTF-8 -*- 02 import copy 03 from array import * 04 print(" (多次元,array,変更前)") 05 v1 = [array("i", [10, 20, 30]), array("i", [40, 50, 60])] 06 v2 = [array("i", [10, 20, 30]), array("i", [40, 50, 60])] 07 v3 = v1 08 v4 = copy.copy(v1) 09 v5 = copy.deepcopy(v1) 10 print("v1", v1[0][0], v1[0][1], v1[0][2]) 11 print(" ", v1[1][0], v1[1][1], v1[1][2]) 12 print("v2", v2[0][0], v2[0][1], v2[0][2]) 13 print(" ", v2[1][0], v2[1][1], v2[1][2]) 14 print("v3", v3[0][0], v3[0][1], v3[0][2]) 15 print(" ", v3[1][0], v3[1][1], v3[1][2]) 16 print("v4", v4[0][0], v4[0][1], v4[0][2]) 17 print(" ", v4[1][0], v4[1][1], v4[1][2]) 18 print("v5", v5[0][0], v5[0][1], v5[0][2]) 19 print(" ", v5[1][0], v5[1][1], v5[1][2]) 20 print(" (多次元,array,変更後)") 21 v1[0][1] = 70 22 v3[0][2] = 100 23 v4[1][0] = 200 24 v5[1][1] = 300 25 v6 = v1[0] 26 v7 = v1[1] 27 v6[0] = 400 28 v7[2] = 500 # v6[5] = 500 は許されない 29 print("v1", v1[0][0], v1[0][1], v1[0][2]) 30 print(" ", v1[1][0], v1[1][1], v1[1][2]) 31 print("v2", v2[0][0], v2[0][1], v2[0][2]) 32 print(" ", v2[1][0], v2[1][1], v2[1][2]) 33 print("v3", v3[0][0], v3[0][1], v3[0][2]) 34 print(" ", v3[1][0], v3[1][1], v3[1][2]) 35 print("v4", v4[0][0], v4[0][1], v4[0][2]) 36 print(" ", v4[1][0], v4[1][1], v4[1][2]) 37 print("v5", v5[0][0], v5[0][1], v5[0][2]) 38 print(" ", v5[1][0], v5[1][1], v5[1][2]) 39 print("v6", v6[0], v6[1], v6[2]) 40 print("v7", v7[0], v7[1], v7[2])- 多次元の配列を扱うことも可能です.例えば,05 行目,06 行目のように記述すれば,2 行 3 列の表に対応する配列を定義できます.07 行目においては,v1 の値のコピーを v3 に代入,08 行目においては,v1 の浅いコピーを v4 に代入,また,09 行目においては,v1 の深いコピーを v5 に代入しています.10 行目~ 19 行目の出力文によって,以下に示すような結果が得られます.
v1 10 20 30 40 50 60 v2 10 20 30 40 50 60 v3 10 20 30 40 50 60 v4 10 20 30 40 50 60 v5 10 20 30 40 50 60
- 21 行目~ 28 行目において,要素の値を変更していますが,29 行目~ 40 行目の出力文による結果は,以下に示すとおりです.
v1 400 70 100 200 50 500 v2 10 20 30 40 50 60 v3 400 70 100 200 50 500 v4 400 70 100 200 50 500 v5 10 20 30 40 300 60 v6 400 70 100 v7 200 50 500
- v1 や v3 を変更した場合の結果は,1 次元配列と同様,v1 と v3 が同じように変化します.しかし,浅いコピーを行った v4 を介した変更に対しても,v1 や v3 が影響を受けています.2 次元配列は,C++ における 2 次元配列に対する説明で述べたように,v1 がポインタ変数 v1[0],v1[1] からなる配列の先頭を指し,ポインタ変数 v1[0],v1[1] が,各々,各行のデータが入っている配列の先頭を指しているとみなせます(下に示す図を参照).浅いコピーが,v1 の指す領域だけをコピー(この例の場合は,v1[0],v1[1] を v4[0],v4[1] にコピー)して,v4 に記憶しているため,このようなことが起こります.v5 に対して行った深いコピーにおいては,v1[0],v1[1] が指すデータ領域もコピーされて,v5 に記憶されます.そのため,v5 は,全く別の配列となり,その要素の値の変更は他の配列に影響を与えません.

- 25 行目~ 28 行目に示すように,各行を 1 次元配列として扱うことも可能ですが,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません( 28 行目参照).勿論,v6,v7 は,v1 の 1 行目,2 行目と同じデータを指しているため,v6,v7 を介した変更によって,v1,v3,v4 の対応する要素の値も変化します.
- 1 次元配列( NumPy )
01 # -*- coding: UTF-8 -*- 02 import numpy as np 03 import copy 04 print(" (1次元,NumPy,変更前)") 05 w1 = np.array([1, 2, 3]) 06 w2 = np.array([1, 2, 3]) 07 w3 = w1 08 w4 = copy.copy(w1) 09 print("w1", w1[0], w1[1], w1[2]) 10 print("w2", w2[0], w2[1], w2[2]) 11 print("w3", w3[0], w3[1], w3[2]) 12 print("w4", w4[0], w4[1], w4[2]) 13 print(" (1次元,NumPy,変更後)") 14 w3[1] = 4 15 w4[2] = 5 16 print("w1", w1[0], w1[1], w1[2]) 17 print("w2", w2[0], w2[1], w2[2]) 18 print("w3", w3[0], w3[1], w3[2]) 19 print("w4", w4[0], w4[1], w4[2])- NumPy を利用して,配列を扱うことも可能です.array や list との大きな違いは,多次元配列であっても,データが連続した領域に記憶されることです.また,プログラムの実行時に,要素の追加,削除等を行うことは多少面倒です.ここでは,配列の定義方法は異なりますが,array を使用した 1 次元配列の場合と同様の処理を行っています.04 行目~ 19 行目内の出力文によって得られる結果は以下に示すとおりであり,array の場合と同じです.
(1次元,NumPy,変更前) w1 1 2 3 w2 1 2 3 w3 1 2 3 w4 1 2 3 (1次元,NumPy,変更後) w1 1 4 3 w2 1 2 3 w3 1 4 3 w4 1 2 5
- 2 次元配列( NumPy )
01 # -*- coding: UTF-8 -*- 02 import numpy as np 03 import copy 04 print(" (多次元,Numpy,変更前)") 05 x1 = np.array([[10, 20, 30], [40, 50, 60]]) 06 x2 = np.array([[10, 20, 30], [40, 50, 60]]) 07 x3 = x1 08 x4 = copy.copy(x1) 09 print("x1", x1[0][0], x1[0][1], x1[0][2]) 10 print(" ", x1[1][0], x1[1][1], x1[1][2]) 11 print("x2", x2[0][0], x2[0][1], x2[0][2]) 12 print(" ", x2[1][0], x2[1][1], x2[1][2]) 13 print("x3", x3[0][0], x3[0][1], x3[0][2]) 14 print(" ", x3[1][0], x3[1][1], x3[1][2]) 15 print("x4", x4[0][0], x4[0][1], x4[0][2]) 16 print(" ", x4[1][0], x4[1][1], x4[1][2]) 17 print(" (多次元,Numpy,変更後)") 18 x1[0][1] = 70 19 x3[0][2] = 100 20 x4[1][0] = 200 21 x5 = x1[0] 22 x5[0] = 300 23 print("x1", x1[0][0], x1[0][1], x1[0][2]) 24 print(" ", x1[1][0], x1[1][1], x1[1][2]) 25 print("x2", x2[0][0], x2[0][1], x2[0][2]) 26 print(" ", x2[1][0], x2[1][1], x2[1][2]) 27 print("x3", x3[0][0], x3[0][1], x3[0][2]) 28 print(" ", x3[1][0], x3[1][1], x3[1][2]) 29 print("x4", x4[0][0], x4[0][1], x4[0][2]) 30 print(" ", x4[1][0], x4[1][1], x4[1][2]) 31 print("x5", x5[0], x5[1], x5[2])- NumPy によって,多次元の配列を扱うことも可能です.09 行目~ 31 行目内の出力文によって得られる結果は以下に示すとおりです.大きく異なるのは,浅いコピーを利用した x4 においても,全く別の配列として取り扱われる点です( x4 の値を変更しても,他の配列はその影響を受けない).また,array の場合と同様,21 行目~ 22 行目に示すように,各行を 1 次元配列として扱うことも可能ですが,異なる行のデータを連続した 1 次元配列とみなして参照することはできません.
(多次元,NumPy,変更前) x1 10 20 30 40 50 60 x2 10 20 30 40 50 60 x3 10 20 30 40 50 60 x4 10 20 30 40 50 60 (多次元,NumPy,変更後) x1 300 70 100 40 50 60 x2 10 20 30 40 50 60 x3 300 70 100 40 50 60 x4 10 20 30 200 50 60 x5 300 70 100
- クラスのオブジェクト
01 # -*- coding: UTF-8 -*- 02 import numpy as np 03 import copy 04 05 class Example2 : 06 def __init__(self, xx1, xx2, xx3) : 07 self.x1 = xx1 08 self.x2 = xx2 09 self.x3 = xx3 10 self.y = [10, 20, 30] 11 12 print(" 変更前") 13 p1 = Example2(1, 2, 3) 14 p2 = Example2(1, 2, 3) 15 p3 = p1 16 p4 = copy.copy(p1) 17 p5 = copy.deepcopy(p1) 18 print("p1.x", p1.x1, p1.x2, p1.x3) 19 print("p2.x", p2.x1, p2.x2, p2.x3) 20 print("p3.x", p3.x1, p3.x2, p3.x3) 21 print("p4.x", p4.x1, p4.x2, p4.x3) 22 print("p5.x", p5.x1, p5.x2, p5.x3) 23 print("p1.y", p1.y[0], p1.y[1], p1.y[2]) 24 print("p2.y", p2.y[0], p2.y[1], p2.y[2]) 25 print("p3.y", p3.y[0], p3.y[1], p3.y[2]) 26 print("p4.y", p4.y[0], p4.y[1], p4.y[2]) 27 print("p5.y", p5.y[0], p5.y[1], p5.y[2]) 28 print(" 変更後") 29 p1.x1 = 10; 30 p3.y[0] = 100; 31 p4.x2 = 20 32 p4.y[1] = 200 33 p5.x3 = 30 34 p5.y[2] = 300 35 print("p1.x", p1.x1, p1.x2, p1.x3) 36 print("p2.x", p2.x1, p2.x2, p2.x3) 37 print("p3.x", p3.x1, p3.x2, p3.x3) 38 print("p4.x", p4.x1, p4.x2, p4.x3) 39 print("p5.x", p5.x1, p5.x2, p5.x3) 40 print("p1.y", p1.y[0], p1.y[1], p1.y[2]) 41 print("p2.y", p2.y[0], p2.y[1], p2.y[2]) 42 print("p3.y", p3.y[0], p3.y[1], p3.y[2]) 43 print("p4.y", p4.y[0], p4.y[1], p4.y[2]) 44 print("p5.y", p5.y[0], p5.y[1], p5.y[2])- 次に,クラスのインスタンス(オブジェクト)について検討していきます.クラスとは,05 行目~ 10 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,3 つの整数型データ x1,x2,x3 と整数型を要素とする配列 y から構成されています.13 行目~ 14 行目によって生成されたオブジェクト p1,p2 は,値は同じであっても,全く別のオブジェクトになります.また,15 行目~ 17 行目では,p1 の値をコピーし,それを p3 に記憶,p1 の浅いコピーを p4 に記憶,さらに,p1 の深いコピーを p5 に記憶しています.以下に示す出力からも明らかなように,array を使用した多次元配列の場合と同様,p1,p2,p3,p4,p5 をポインタ変数として考えると理解しやすいと思います.以下に示す結果からも明らかなように,浅いコピーでは,x1,x2,x3,及び,y(アドレス)はコピーしますが,y が指すデータまではコピーしません.しかし,深いコピーにおいては,y が指すデータもコピーして,新しいオブジェクトを生成しています.
変更前 p1.x 1 2 3 p2.x 1 2 3 p3.x 1 2 3 p4.x 1 2 3 p5.x 1 2 3 p1.y 10 20 30 p2.y 10 20 30 p3.y 10 20 30 p4.y 10 20 30 p5.y 10 20 30 変更後 p1.x 10 2 3 p2.x 1 2 3 p3.x 10 2 3 p4.x 1 20 3 p5.x 1 2 30 p1.y 100 200 30 p2.y 10 20 30 p3.y 100 200 30 p4.y 100 200 30 p5.y 10 20 300
- C#
- 整数型
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 int ia, ib, ic; 08 ia = 10; 09 ib = 10; 10 ic = ia; 11 Console.WriteLine(" ***int***"); 12 Console.WriteLine("ia " + ia + " ib " + ib + " ic " + ic); 13 ic = 20; 14 Console.WriteLine("ia " + ia + " ib " + ib + " ic " + ic); 15 } 16 }- 整数型のデータに対して,記憶と変更の問題を検討したプログラムです.07 行目~ 10 行目の記述によって,変数 ia 及び ib には 10 という値が記憶され,変数 ic には変数 ia に記憶されている値のコピーが記憶されます.従って,12 行目の出力文によって,以下に示すような出力が得られます.
ia 10 ib 10 ic 10
- 13 行目において,変数 ic に記憶しているデータを変更しています.10 行目の記述があっても,ia と ic は異なる変数ですので,各々独立に変化します.従って,14 行目の出力文によって,下に示すような結果が得られます.予想したとおりの結果だと思います.以上の結果を概念的に図示すればその下に示す図のようになります.
ia 10 ib 10 ic 20
- 浮動小数点型,文字型,文字列型
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 // double 08 double da, db, dc; 09 da = 10.5; 10 db = 10.5; 11 dc = da; 12 Console.WriteLine(" ***double***"); 13 Console.WriteLine("da " + da + " db " + db + " dc " + dc); 14 dc = 20.5; 15 Console.WriteLine("da " + da + " db " + db + " dc " + dc); 16 // 文字 17 char ca, cb, cc; 18 ca = 'a'; 19 cb = 'a'; 20 cc = ca; 21 Console.WriteLine(" ***文字***"); 22 Console.WriteLine("ca " + ca + " cb " + cb + " cc " + cc); 23 cc = 'x'; 24 Console.WriteLine("ca " + ca + " cb " + cb + " cc " + cc); 25 // 文字列 26 Console.WriteLine(" ***文字列***"); 27 String str1 = "abc", str2 = "abc", str3; 28 str3 = str1; 29 Console.WriteLine("str1 " + str1 + " str2 " + str2 + " str3 " + str3); 30 str3 = "xyz"; 31 Console.WriteLine("str1 " + str1 + " str2 " + str2 + " str3 " + str3); 32 } 33 }- 08 行目~ 15 行目
- 浮動小数点型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
da 10.500000 db 10.500000 dc 10.500000 da 10.500000 db 10.500000 dc 20.500000
- 17 行目~ 24 行目
- 文字型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
ca a cb a cc a ca a cb a cc x
- 26 行目~ 31 行目
- 文字列型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
str1 abc str2 abc str3 abc str1 abc str2 abc str3 xyz
- 1 次元配列
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 Console.WriteLine(" ***配列***"); 08 Console.WriteLine(" 変更前(1次元)"); 09 int[] u1 = {1, 2, 3}; 10 int[] u2 = {1, 2, 3}; 11 int[] u3; 12 u3 = u1; 13 Console.WriteLine("u1 " + u1[0] + " " + u1[1] + " " + u1[2]); 14 Console.WriteLine("u2 " + u2[0] + " " + u2[1] + " " + u2[2]); 15 Console.WriteLine("u3 " + u3[0] + " " + u3[1] + " " + u3[2]); 16 Console.WriteLine(" 変更後(1次元)"); 17 u3[1] = 4; 18 Console.WriteLine("u1 " + u1[0] + " " + u1[1] + " " + u1[2]); 19 Console.WriteLine("u2 " + u2[0] + " " + u2[1] + " " + u2[2]); 20 Console.WriteLine("u3 " + u3[0] + " " + u3[1] + " " + u3[2]); 21 } 22 }- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.例えば,
int[] u1 = new int [3]; // 初期設定しない場合 int[] u1 = {1, 2, 3}; int[] u1 = new int [] {1, 2, 3}; int[] u1 = new[] {1, 2, 3};- の 1 行目のように宣言すれば,3 つの整数型データを記憶できる領域が確保され,変数名と添え字を利用して,x[0],x[1],x[2] のようにして参照できます.2 行目以下においても,3 つの整数型データを記憶できる領域が確保される点では同じですが,各要素に記憶される値が 1,2,3 で初期設定されます.
- プログラムの 09 行目~ 11 行目においては,同じ整数値で初期設定された 2 つの配列 u1,u2 と,配列変数であることだけを宣言した変数 u3 を定義しています.つまり,整数型における 07 行目~ 09 行目の処理とほぼ同じことを行っています.そして,12 行目の文は,整数型における 10 行目に対応します.この結果,13 行目~ 15 行目の出力文によって,以下に示すような結果が出力されます.
u1 1 2 3 u2 1 2 3 u3 1 2 3
- 17 行目は,要素に記憶されている値を変更する処理であり,整数型における 13 行目に相当します.今までの考え方からすれば,u3[1] の値だけが変化し,他の変数は一切影響を受けないはずです.しかし,18 行目~ 20 行目の出力文によって出力される結果,
u1 1 4 3 u2 1 2 3 u3 1 4 3
- を見てください.u3[1] の変更によって u1[1] も変化していることが分かります.これは,C++ における new 演算子を使用した 1 次元配列の場合と同様,u1,u2,u3 がポインタ変数であると考えると当然の結果です.12 行目によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているからです.09 行目~ 12 行目による結果を概念的に示せば以下のようになります.
- 2 次元配列,[][]
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 Console.WriteLine(" 変更前(多次元), [][]"); 08 int[][] w1 = new int[][] { // 行毎に列数が変わっても良い 09 new int[] {10, 20, 30}, 10 new int[] {40, 50, 60} 11 }; 12 int[][] w2 = new int [2][]; 13 w2[0] = new int[] {10, 20, 30}; 14 w2[1] = new int[] {40, 50, 60}; 15 int[][] w3; 16 w3 = w1; 17 Console.WriteLine("w1 " + w1[0][0] + " " + w1[0][1] + " " + w1[0][2]); 18 Console.WriteLine(" " + w1[1][0] + " " + w1[1][1] + " " + w1[1][2]); 19 Console.WriteLine("w2 " + w2[0][0] + " " + w2[0][1] + " " + w2[0][2]); 20 Console.WriteLine(" " + w2[1][0] + " " + w2[1][1] + " " + w2[1][2]); 21 Console.WriteLine("w3 " + w3[0][0] + " " + w3[0][1] + " " + w3[0][2]); 22 Console.WriteLine(" " + w3[1][0] + " " + w3[1][1] + " " + w3[1][2]); 23 Console.WriteLine(" 変更後(多次元), [][]"); 24 w3[1][1] = 100; 25 int[] wp1 = w1[0]; 26 wp1[1] = 200; 27 Console.WriteLine("w1 " + w1[0][0] + " " + w1[0][1] + " " + w1[0][2]); 28 Console.WriteLine(" " + w1[1][0] + " " + w1[1][1] + " " + w1[1][2]); 29 Console.WriteLine("w2 " + w2[0][0] + " " + w2[0][1] + " " + w2[0][2]); 30 Console.WriteLine(" " + w2[1][0] + " " + w2[1][1] + " " + w2[1][2]); 31 Console.WriteLine("w3 " + w3[0][0] + " " + w3[0][1] + " " + w3[0][2]); 32 Console.WriteLine(" " + w3[1][0] + " " + w3[1][1] + " " + w3[1][2]); 33 } 34 }- 多次元の配列は,08 行目~ 11 行目,12 行目~ 14 行目に示すように,配列の要素を配列として定義することによって可能です.その際,各行の列数が異なっても構いません.また,初期設定を行わないような場合は,
int[][] w1 = new int [2][3];
- のような形で定義することも可能です.w3 に対しては,2 次元配列であることだけを宣言していますが( 15 行目),16 行目の記述によって,w3 も,w1 と同じ 2 行 3 列の配列になります.そのイメージは,C++ における new 演算子を使用した 2 次元配列の場合と同様,以下のようになります.
- 24 行目において,w3 の値を変更していますが,w1 と w3 は,同じ領域を指しているため,w3 の値を変更すれば w1 の値も変化します(逆も同様).また,25 行目~ 26 行目に示すように,各行を 1 次元配列として扱うことも可能です.この例では,wp1 は,要素数 が 3 である 1 次元配列とみなされますが,w1 の 1 行目と同じデータを指していますので,wp1 を介して要素の値を変更すれば,w1 の対応する要素の値も変化します.また,すべてのデータが連続した領域に確保されるとは限らないため,異なる行のデータを,連続した 1 次元配列とみなして参照することはできません.07 行目~ 32 行目内の出力文によって,以下に示すような結果が得られます.
変更前(多次元), [][] w1 10 20 30 40 50 60 w2 10 20 30 40 50 60 w3 10 20 30 40 50 60 変更後(多次元), [][] w1 10 200 30 40 100 60 w2 10 20 30 40 50 60 w3 10 200 30 40 100 60
- 2 次元配列,[*,*]
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 Console.WriteLine(" 変更前(多次元), [*,*]"); 08 int[,] v1 = {{10, 20, 30}, {40, 50, 60}}; 09 int[,] v2 = {{10, 20, 30}, {40, 50, 60}}; 10 int[,] v3; 11 v3 = v1; 12 Console.WriteLine("v1 " + v1[0,0] + " " + v1[0,1] + " " + v1[0,2]); 13 Console.WriteLine(" " + v1[1,0] + " " + v1[1,1] + " " + v1[1,2]); 14 Console.WriteLine("v2 " + v2[0,0] + " " + v2[0,1] + " " + v2[0,2]); 15 Console.WriteLine(" " + v2[1,0] + " " + v2[1,1] + " " + v2[1,2]); 16 Console.WriteLine("v3 " + v3[0,0] + " " + v3[0,1] + " " + v3[0,2]); 17 Console.WriteLine(" " + v3[1,0] + " " + v3[1,1] + " " + v3[1,2]); 18 Console.WriteLine(" 変更後(多次元), [*,*]"); 19 v3[0,2] = 100; 20 Console.WriteLine("v1 " + v1[0,0] + " " + v1[0,1] + " " + v1[0,2]); 21 Console.WriteLine(" " + v1[1,0] + " " + v1[1,1] + " " + v1[1,2]); 22 Console.WriteLine("v2 " + v2[0,0] + " " + v2[0,1] + " " + v2[0,2]); 23 Console.WriteLine(" " + v2[1,0] + " " + v2[1,1] + " " + v2[1,2]); 24 Console.WriteLine("v3 " + v3[0,0] + " " + v3[0,1] + " " + v3[0,2]); 25 Console.WriteLine(" " + v3[1,0] + " " + v3[1,1] + " " + v3[1,2]); 26 } 27 }- C# においては,多次元配列を 08 行目~ 10 行目,または,
int[,] v1 = new int[,] {{10, 20, 30}, {40, 50, 60}}; int[,] v1 = new[,] {{10, 20, 30}, {40, 50, 60}}; int[,] v1 = new int [2,3]; // 初期設定しない場合- のような形で定義することも可能です.この方法を使用すると,配列は,連続した領域に確保され,[i][j] ではなく,[i,j] のような形で各要素を参照します.基本的には,「 2 次元配列,[][] 」の項で示した内容と同じですが,25 行目~ 26 行目に示したように,各行を 1 次元配列として扱うことはできません.07 行目~ 25 行目内の出力文によって,以下に示すような結果が得られます.
変更前(多次元), [*,*] v1 10 20 30 40 50 60 v2 10 20 30 40 50 60 v3 10 20 30 40 50 60 変更後(多次元), [*,*] v1 10 20 100 40 50 60 v2 10 20 30 40 50 60 v3 10 20 100 40 50 60
- List クラス
01 using System; 02 using System.Collections.Generic; 03 04 class Program 05 { 06 static void Main() 07 { 08 Console.WriteLine(" 変更前"); 09 List <string> x1, x2; 10 x1 = new List <string> (); 11 x1.AddRange(new string[] { "aaa", "bbb", "ccc" }); 12 x2 = x1; 13 Console.WriteLine("x1 " + x1[0] + " " + x1[1] + " " + x1[2]); 14 Console.WriteLine("x2 " + x2[0] + " " + x2[1] + " " + x2[2]); 15 Console.WriteLine(" 変更後\n"); 16 x2[2] = "xxx"; 17 Console.WriteLine("x1 " + x1[0] + " " + x1[1] + " " + x1[2]); 18 Console.WriteLine("x2 " + x2[0] + " " + x2[1] + " " + x2[2]); 19 } 20 }- 今まで述べた方法では,プログラムの実行時に,要素の追加,削除等を行うことができません.しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,List クラスなどを使用することによって実現できます.List クラスにおいては,実行時に,必要な数だけのデータを追加,削除,変更等が可能です.C++ における vector クラスを使用した場合と似ていますが,配列の場合と同様,12 行目の代入文によってアドレスが記憶されるため,x2 の要素の値を変更すると x1 に対する値も変化します(逆も同様).08 行目~ 18 行目内の出力文によって,以下に示すような結果が得られます.
変更前 x1 aaa bbb ccc x2 aaa bbb ccc 変更後 x1 aaa bbb xxx x2 aaa bbb xxx
- クラスのオブジェクト
01 using System; 02 03 class Program 04 { 05 static void Main() 06 { 07 Console.WriteLine(" 変更前"); 08 Example p1 = new Example(10); 09 Example p2 = new Example(10); 10 Example p3 = p1; 11 Console.WriteLine("p1.x " + p1.x + " y " + p1.y[0] + " " + p1.y[1]); 12 Console.WriteLine("p2.x " + p2.x + " y " + p2.y[0] + " " + p2.y[1]); 13 Console.WriteLine("p3.x " + p3.x + " y " + p3.y[0] + " " + p3.y[1]); 14 Console.WriteLine(" 変更後"); 15 p3.x = 9; 16 p3.y[1] = 90; 17 Console.WriteLine("p1.x " + p1.x + " y " + p1.y[0] + " " + p1.y[1]); 18 Console.WriteLine("p2.x " + p2.x + " y " + p2.y[0] + " " + p2.y[1]); 19 Console.WriteLine("p3.x " + p3.x + " y " + p3.y[0] + " " + p3.y[1]); 20 } 21 } 22 23 class Example 24 { 25 public int x; 26 public int[] y; 27 public Example () {} 28 public Example (int x1) 29 { 30 x = x1; 31 y = new int [] {1, 2, 3}; 32 } 33 }- 次に,クラスのインスタンス(オブジェクト)について検討していきます.クラスとは,23 行目~ 33 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,1 つの整数型データ x と整数型を要素とする配列 y から構成されています.08 行目,09 行目によって生成されたオブジェクト p1,p2 は,値は同じであっても,全く別のオブジェクトになります.また,10 行目では,p1 を p3 に代入しています.以下に示す出力からも明らかなように,配列の場合と同様,C++ におけるクラスのオブジェクトの 57 行目~ 87 行目の内容に対応しており,p1,p2,p3 をポインタ変数として考えると理解しやすいと思います.元のオブジェクトと同じ内容の異なるオブジェクトを生成したいような場合は,元のオブジェクトを引数とするコンストラクタを作成する,クローンを生成する clone メソッドを作成する,などが必要になります.
変更前 p1.x 10 y 1 2 p2.x 10 y 1 2 p3.x 10 y 1 2 変更後 p1.x 9 y 1 90 p2.x 10 y 1 2 p3.x 9 y 1 90
- VB
- 整数型
01 Imports System 02 03 Module Test 04 Sub Main() 05 Dim ia, ib, ic as Integer 06 ia = 10 07 ib = 10 08 ic = ia 09 Console.WriteLine(" ***int***") 10 Console.WriteLine("ia " & ia & " ib " & ib & " ic " & ic) 11 ic = 20 12 Console.WriteLine("ia " & ia & " ib " & ib & " ic " & ic) 13 End Sub 14 End Module- 整数型のデータに対して,記憶と変更の問題を検討したプログラムです.05 行目~ 08 行目の記述によって,変数 ia 及び ib には 10 という値が記憶され,変数 ic には変数 ia に記憶されている値のコピーが記憶されます.従って,10 行目の出力文によって,以下に示すような出力が得られます.
ia 10 ib 10 ic 10
- 11 行目において,変数 ic に記憶しているデータを変更しています.08 行目の記述があっても,ia と ic は異なる変数ですので,各々独立に変化します.従って,12 行目の出力文によって,下に示すような結果が得られます.予想したとおりの結果だと思います.以上の結果を概念的に図示すればその下に示す図のようになります.
ia 10 ib 10 ic 20
- 浮動小数点型,文字列型
01 Imports System 02 03 Module Test 04 Sub Main() 05 ' double 06 Dim da, db, dc as Double 07 da = 10.5 08 db = 10.5 09 dc = da 10 Console.WriteLine(" ***double***") 11 Console.WriteLine("da " & da & " db " & db & " dc " & dc) 12 dc = 20.5 13 Console.WriteLine("da " & da & " db " & db & " dc " & dc) 14 ' 文字列 15 Console.WriteLine(" ***文字列***") 16 Dim str1 As String = "abc" 17 Dim str2 As String = "abc" 18 Dim str3 As String = str1 19 Console.WriteLine("str1 " & str1 & " str2 " & str2 & " str3 " & str3) 20 str3 = "xyz" 21 Console.WriteLine("str1 " & str1 & " str2 " & str2 & " str3 " & str3) 22 End Sub 23 End Module- 06 行目~ 13 行目
- 浮動小数点型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
da 10.500000 db 10.500000 dc 10.500000 da 10.500000 db 10.500000 dc 20.500000
- 15 行目~ 21 行目
- 文字列型のデータに対して,整数型データに対する処理と同様のことを行っています.得られる結果は,整数型の場合と同様であり,以下に示すような結果が得られます.
str1 abc str2 abc str3 abc str1 abc str2 abc str3 xyz
- 1 次元配列
01 Imports System 02 03 Module Test 04 Sub Main() 05 Console.WriteLine(" ***配列***" & vbCrLf & " 変更前(1次元)") 06 Dim u1() As Integer = {1, 2, 3} 07 Dim u2() As Integer = {1, 2, 3} 08 Dim u3() As Integer = u1 09 Console.WriteLine("u1 " & u1(0) & " " & u1(1) & " " & u1(2)) 10 Console.WriteLine("u2 " & u2(0) & " " & u2(1) & " " & u2(2)) 11 Console.WriteLine("u3 " & u3(0) & " " & u3(1) & " " & u3(2)) 12 Console.WriteLine(" 変更後(1次元)") 13 u3(1) = 4 14 Console.WriteLine("u1 " & u1(0) & " " & u1(1) & " " & u1(2)) 15 Console.WriteLine("u2 " & u2(0) & " " & u2(1) & " " & u2(2)) 16 Console.WriteLine("u3 " & u3(0) & " " & u3(1) & " " & u3(2)) 17 End Sub 18 End Module- 配列は,複合データ型の一種であり,複数の同じデータ型のデータを処理する場合に利用されます.プログラムの 06 行目,07 行目においては,同じ整数値で初期設定された 2 つの配列 u1,u2 を定義し,08 行目では,配列変数であることだけを宣言した変数 u3 に u1 を代入( u1 で初期設定)しています.つまり,整数型における 05 行目~ 08 行目の処理とほぼ同じことを行っています.この結果,09 行目~ 11 行目の出力文によって,以下に示すような結果が出力されます.
u1 1 2 3 u2 1 2 3 u3 1 2 3
- 13 行目は,要素に記憶されている値を変更する処理であり,整数型における 11 行目に相当します.今までの考え方からすれば,u3(1) の値だけが変化し,他の変数は一切影響を受けないはずです.しかし,14 行目~ 16 行目の出力文によって出力される結果,
u1 1 4 3 u2 1 2 3 u3 1 4 3
- を見てください.u3 の変更によって u1(1) も変化していることが分かります.これは,C++ における new 演算子を使用した 1 次元配列の場合と同様,u1,u2,u3 がポインタ変数であると考えると当然の結果です.08 行目によって,u1 に記憶されているアドレスが u3 に記憶され,u1 と u3 が同じ領域を指しているからです.06 行目~ 08 行目による結果を概念的に示せば以下のようになります.
- 2 次元配列
01 Imports System 02 03 Module Test 04 Sub Main() 05 Console.WriteLine(" 変更前(多次元)") 06 Dim v1(,) As Integer = {{10, 20, 30}, {40, 50, 60}} 07 Dim v2(,) As Integer = {{10, 20, 30}, {40, 50, 60}} 08 Dim v3(,) As Integer 09 v3 = v1 10 Console.WriteLine("v1 " & v1(0,0) & " " & v1(0,1) & " " & v1(0,2)) 11 Console.WriteLine(" " & v1(1,0) & " " & v1(1,1) & " " & v1(1,2)) 12 Console.WriteLine("v2 " & v2(0,0) & " " & v2(0,1) & " " & v2(0,2)) 13 Console.WriteLine(" " & v2(1,0) & " " & v2(1,1) & " " & v2(1,2)) 14 Console.WriteLine("v3 " & v3(0,0) & " " & v3(0,1) & " " & v3(0,2)) 15 Console.WriteLine(" " & v3(1,0) & " " & v3(1,1) & " " & v3(1,2)) 16 Console.WriteLine(" 変更後(多次元)") 17 v3(0,1) = 70 18 Console.WriteLine("v1 " & v1(0,0) & " " & v1(0,1) & " " & v1(0,2)) 19 Console.WriteLine(" " & v1(1,0) & " " & v1(1,1) & " " & v1(1,2)) 20 Console.WriteLine("v2 " & v2(0,0) & " " & v2(0,1) & " " & v2(0,2)) 21 Console.WriteLine(" " & v2(1,0) & " " & v2(1,1) & " " & v2(1,2)) 22 Console.WriteLine("v3 " & v3(0,0) & " " & v3(0,1) & " " & v3(0,2)) 23 Console.WriteLine(" " & v3(1,0) & " " & v3(1,1) & " " & v3(1,2)) 24 End Sub 25 End Module- 多次元の配列を扱うことも可能です.例えば,06 行目,07 行目の記述によって 2 行 3 列の表に対応する配列 v1,v2 が生成されます.v3 に対しては,2 次元配列であることだけを宣言していますが( 08 行目),09 行目の記述によって,v3 も,v1 と同じ 2 行 3 列の配列になります.そのイメージは,C++ における new 演算子を使用した 2 次元配列の場合と同様,以下のようになります.
- 17 行目において,v3 の値を変更していますが,v1 と v3 は,同じ領域を指しているため,v3 の値を変更すれば v1 の値も変化します(逆も同様).ただし,他の言語のように,各行を 1 次元配列として扱うことはできません.05 行目~ 23 行目内の出力文によって,下に示すような結果が得られます.
変更前(多次元) v1 10 20 30 40 50 60 v2 10 20 30 40 50 60 v3 10 20 30 40 50 60 変更後(多次元) v1 10 70 30 40 50 60 v2 10 20 30 40 50 60 v3 10 70 30 40 50 60
- List クラス
01 Imports System 02 Imports System.Collections.Generic 03 04 Module Test 05 Sub Main() 06 Console.WriteLine(" ***配列(List クラス)***" & vbCrLf & " 変更前") 07 Dim w1 As New List(Of Integer) 08 w1.Add(1) 09 w1.Add(2) 10 w1.Add(3) 11 Dim w2 As New List(Of Integer) 12 w2 = w1 13 Console.Write("w1") 14 For Each w As Integer In w1 15 Console.Write(" " & w) 16 Next 17 Console.WriteLine("") 18 Console.Write("w2") 19 For Each w As Integer In w2 20 Console.Write(" " & w) 21 Next 22 Console.WriteLine(vbCrLf & " 変更後") 23 w2.RemoveAt(0) 24 Console.Write("w1") 25 For Each w As Integer In w1 26 Console.Write(" " & w) 27 Next 28 Console.WriteLine("") 29 Console.Write("w2") 30 For Each w As Integer In w2 31 Console.Write(" " & w) 32 Next 33 Console.WriteLine("") 34 End Sub 35 End Module- 今まで述べた方法では,プログラムの実行時に,要素の追加,削除等を行うことができません.しかし,問題によっては,前もってデータの数を決めることができず,実行時に,必要な数だけのデータを扱いたい場合があります.これは,List クラスなどを使用することによって実現できます.List クラスにおいては,実行時に,必要な数だけのデータを追加,削除,変更等が可能です.C++ における vector クラスを使用した場合と似ていますが,配列の場合と同様,12 行目の代入文によってアドレスが記憶されるため,w1 の要素の値を変更すると w2 に対する値も変化します(逆も同様).06 行目~ 33 行目内の出力文によって,以下に示すような結果が得られます.なお,vbCrLf は,改行を意味します.
***配列(List クラス)*** 変更前 w1 1 2 3 w2 1 2 3 変更後 w1 2 3 w2 2 3
- クラスのオブジェクト
01 Imports System 02 03 Module Test 04 Sub Main() 05 Console.WriteLine(" ***オブジェクト***" & vbCrLf & " 変更前") 06 Dim p1 As Example = new Example(1, 2) 07 Dim p2 As Example = p1 08 Console.WriteLine("p1 x1 " & p1.x1 & " x2 " & p1.x2) 09 Console.WriteLine(" y " & p1.y(0) & " " & p1.y(1) & " " & p1.y(2)) 10 Console.WriteLine("p2 x1 " & p2.x1 & " x2 " & p2.x2) 11 Console.WriteLine(" y " & p2.y(0) & " " & p2.y(1) & " " & p2.y(2)) 12 Console.WriteLine(" 変更後") 13 p2.x1 = 9 14 p2.y(1) = 90 15 Console.WriteLine("p1 x1 " & p1.x1 & " x2 " & p1.x2) 16 Console.WriteLine(" y " & p1.y(0) & " " & p1.y(1) & " " & p1.y(2)) 17 Console.WriteLine("p2 x1 " & p2.x1 & " x2 " & p2.x2) 18 Console.WriteLine(" y " & p2.y(0) & " " & p2.y(1) & " " & p2.y(2)) 19 End Sub 20 21 Class Example 22 Public x1, x2 As Integer 23 Public y() As integer = {10, 20, 30} 24 Public Sub New (ByVal xx1 As Integer, ByVal xx2 As Integer) 25 x1 = xx1 26 x2 = xx2 27 End Sub 28 End Class 29 End Module- 次に,クラスのインスタンス(オブジェクト)について検討していきます.クラスとは,21 行目~ 29 行目に定義されているように,様々なデータ型の集まりから構成されています.この例では,2 つの整数型データ x1,x2 と整数型を要素とする配列 y から構成されています.06 行目によってオブジェクト p1 を生成し,07 行目では,p1 の値をコピーし,それを p2 に記憶しています.以下に示す出力からも明らかなように,配列の場合と同様,C++ におけるクラスのオブジェクトの 57 行目~ 87 行目の内容に対応しており,p1,p2 をポインタ変数として考えると理解しやすいと思います.元のオブジェクトを引数とするコンストラクタを作成する,クローンを生成する clone メソッドを作成する,などが必要になります.
***オブジェクト*** 変更前 p1 x1 1 x2 2 y 10 20 30 p2 x1 1 x2 2 y 10 20 30 変更後 p1 x1 9 x2 2 y 10 90 30 p2 x1 9 x2 2 y 10 90 30
情報学部 菅沼ホーム 目次 索引