
| 情報学部 | 菅沼ホーム | 目次 | 索引 |
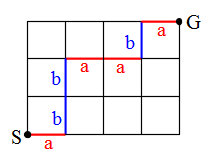

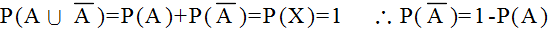
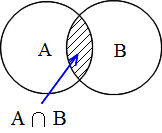

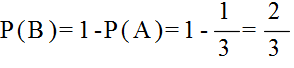
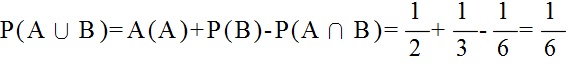
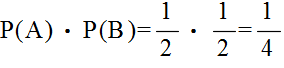
| 事象 | A1 | A2 | ・・・・・ | An | 全事象 U |
|---|---|---|---|---|---|
| 確率変数 X | x1 | x2 | ・・・・・ | xn | - |
| 確率 | P(A1) | P(A2) | ・・・・・ | P(An) | 1.0 |
| 順位 | 1等 | 2等 | 3等 |
|---|---|---|---|
| 本数 | 1本 | 2本 | 5本 |
| 賞金 | 50000円 | 10000円 | 5000円 |
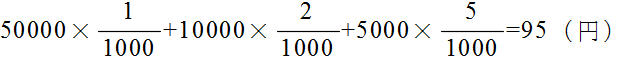
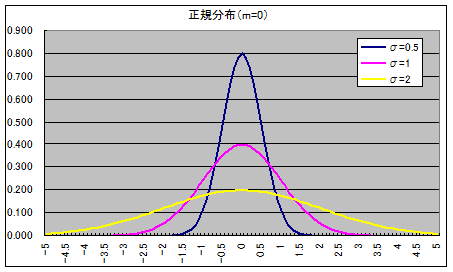
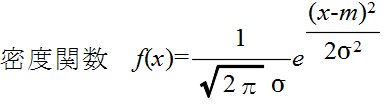
| 接頭辞 | 発音 | 大きさ | 接頭辞 | 発音 | 大きさ | |
|---|---|---|---|---|---|---|
| K | キロ | 103 | m | ミリ | 10-3 | |
| M | メガ | 106 | μ | マイクロ | 10-6 | |
| G | ギガ | 109 | n | ナノ | 10-9 | |
| T | テラ | 1012 | p | ピコ | 10-12 |
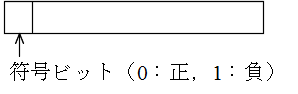

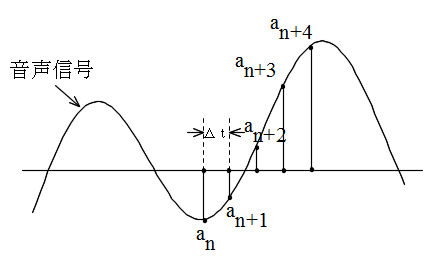
| 文字コード | 特徴 |
|---|---|
| ASCII コード | ANSI(アメリカ規格協会)が制定した,7 ビット,または,パリティビットを加えた 8 ビットコード.パソコンなどで広く利用されている. |
| EUC( Extended Unix Code,拡張 UNIX コード) | UNIX( OS の一種) で使用されている 2 バイトコード |
| JIS コード | ANSI を基本にした 8 ビットコード |
| JIS 漢字コード | 文字コードの前後に全角文字であることを示すコードを挿入した 2 バイトコード |
| シフト JIS コード | 先頭バイトに全角か半角かの情報を持たせた 2 バイトコード |
| Unicode | 世界中の文字を表現できる 2 ~ 4 バイトコード.ISO で標準化されている. |
| EBCDIC | IBM が作成し,大型計算機で使用されている 8 ビットコード |
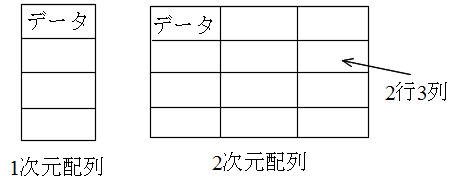
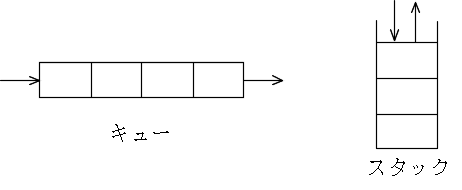
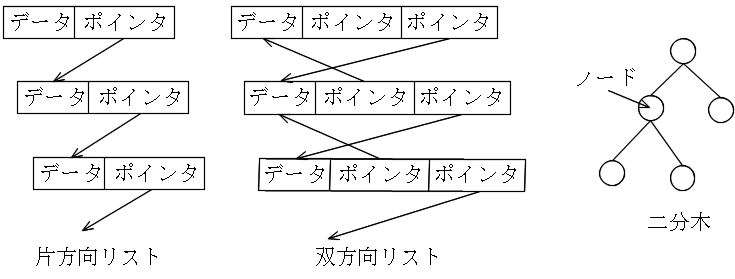
| 情報学部 | 菅沼ホーム | 目次 | 索引 |