
データ型 バイト数と値の範囲 void * * char 1 -128 ~ 127(文字型,1 バイトの整数型) unsigned char 1 0 ~ 255(文字型,1 バイトの符号無し整数型) short 2 -32,768 ~ 32,767( 2 バイトの整数型) unsigned short 2 0 ~ 65,535( 2 バイトの符号無し整数型) int * システム依存(整数型) unsigned int * システム依存(符号無し整数型) long 4 -2,147,483,648 ~ 2,147,483,647( 4 バイトの整数型) unsigned long 4 0 ~ 4,294,967,295( 4 バイトの符号無し整数型) long long 8 -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807( 8 バイトの整数型) unsigned long long 8 0 ~ 18,446,744,073,709,551,615( 8 バイトの符号無し整数型) float 4 3.4E±38(浮動小数点型,有効桁は約 7 桁) double 8 1.7E±308(浮動小数点型,有効桁は約 15 桁) long double * 拡張精度,システム依存(浮動小数点型) bool(C++) 1 true( 0 以外) or false( 0 )(論理型),数値の 0 は false に,その他は true に変換される auto(C++11) * 代入された値によって型を推論する
- 算術演算子と代入演算子
+ : 加算 - : 減算 * : 乗算 / : 除算(整数どうしの除算は,結果の小数点以下を切り捨て) % : 余り(整数演算に対してだけ使用可能) = : 代入 ++ : インクリメント演算子( 1 だけ増加) -- : デクリメント演算子( 1 だけ減少)
- 関係演算子,等値演算子,及び,論理演算子
> より大きい a > b 式 a の値が式 b の値より大きいとき真 < より小さい a < b 式 a の値が式 b の値より小さいとき真 >= 以上 a >= b 式 a の値が式 b の値以上のとき真 <= 以下 a <= b 式 a の値が式 b の値以下のとき真 == 等しい a == b 式 a の値と式 b の値が等しいとき真 != 等しくない a != b 式 a の値と式 b の値が等しくないとき真 || 論理和 x || y 式 x が真か,または,式 y が真のとき真 && 論理積 x && y 式 x が真で,かつ,式 y が真のとき真 ! 否定 ! x 式 x が偽のとき真
- ビット演算子とシフト演算子
| 論理和 x | y 対応するビットのいずれかが 1 のとき真. & 論理積 x & y 対応するビットの双方が 1 のとき真 ^ 排他的論理和 x ^ y 対応するビットが異なるのとき真 ~ 1 の補数 ~ x ビット毎に 1 と 0 を反転する << 左にシフト x << 3 3 ビット左にシフト.x を 23 倍することに相当. >> 右にシフト x >> 3 3 ビット右にシフト.x を 23 で割ることに相当.
- アドレス演算子と間接演算子
- 変数は,主記憶領域のある特定の場所に付けられた名前です.その場所(アドレス)を求めるために使用されるのがアドレス演算子です.アドレス演算子は「 & 」で表し,例えば,変数 value のアドレスを求めるためには,
&value
- と書きます.このアドレスをデータとして保存しておくためには,ポインタという特別な領域が必要です.この領域に付ける名前,つまり,ポインタ変数を定義するためには,例えば,int 型変数に対するポインタは,
int *point;
- と宣言します.変数 value が int 型であったとすると,
point = &value;
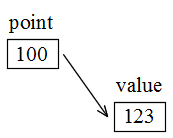
- という文により,変数 value のアドレスがポインタ変数 point に代入され,右図のような関係になります( 変数 value の値が 123,そのアドレスが 100 番地であった場合).
- ポインタ変数について,その変数に記憶されている値(右図では,100 )ではなく,その値が指す場所に記憶されている値(右図では,123 )を参照したい場合があります.このようなとき使用されるのが間接演算子です.間接演算子は「 * 」で表し,例えば,ポインタ変数 point が示すアドレスに入っている内容を変数 data に代入するためには,
data = *point;
- と書きます.右図の例では,変数 data に 123 が記憶されます.
- 論理式: 結果が真または偽となる式
- 分岐
- if 文
if (論理式) { 文1(複数の文も可) (論理式が真の場合に実行) } else { 文2(複数の文も可) (論理式が偽の場合に実行) } - else if 文
if (論理式1) { 文1(複数の文も可) (論理式1が真の場合に実行) } else if (論理式2) { 文2(複数の文も可) (論理式2が真の場合に実行) } ・・・ else { 文n(複数の文も可) (いずれの論理式も偽である場合に実行) } - switch 文
switch (式) { [case 定数式1 :] [文1] [case 定数式2 :] [文2] ・・・・・ [default :] [文n] }
- if 文
- 繰り返し
- for 文
for (初期設定; 論理式; 後処理) { 文(複数の文も可) (論理式が真である限り繰り返し実行) }for (変数宣言 : 範囲) { // 範囲 for 文 文(複数の文も可) } - while 文
while (論理式) { 文(複数の文も可) (論理式が真である限り繰り返し実行) } - do while 文
do { 文(複数の文も可) (論理式が真である限り繰り返し実行, ただし,最初は必ず実行) } while (論理式) ;
- for 文
- 配列
- 配列の宣言方法は以下に示すとおりです.多次元配列の場合も,必ず連続した領域が確保されます.下に示す 2 次元配列の例では,6 個の int 型データが,y[0][0],y[0][1],y[1][0],・・・,y[1][2] の順に,連続した領域に記憶されます.勿論,int の部分には,double,char などの型と共に,クラスも指定可能です.
int x[4]; int y[2][3];
- 以下に示すように,初期設定も可能です.初期設定を行う場合,要素数を省略可能ですが,多次元配列の場合,省略可能なのは最も左側の要素数だけです.なお,等号は,省略することが可能です.
int x[4] = {1, 2, 3, 4}; // int x[] = {1, 2, 3, 4}; int y[2][3] = {{10, 20, 30}, {40, 50, 60}}; // int y[][3] = {{10, 20, 30}, {40, 50, 60}}; - 配列とポインタ
- 配列とポインタとの関係を明らかにするために,以下のようなプログラムについて考えてみます.
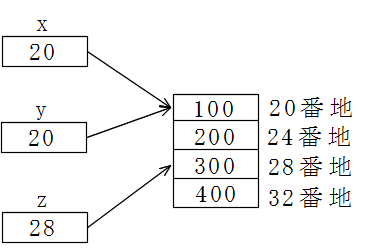
01 #include <stdio.h> 02 03 int main() 04 { 05 int x[4] = {100, 200, 300, 400}; 06 int *y = &x[0]; // int *y = x; でも良い 07 int *z = &x[2]; 08 09 printf("%d %d\n", x[2], *(x+2)); 10 printf("%d %d\n", y[2], *(y+2)); 11 printf("%d %d\n", z[0], *z); 12 13 return 0; 14 }- 05 行目の配列宣言を行うと,右図に示すように,int 型の 4 つのデータを保存するための連続した領域が確保されます.ポインタとの関係を見たい場合,その領域の先頭を指すポインタ変数 x の存在を考えた方が分かりやすいと思います.実際,配列変数の 3 番目の要素を x[2],または,*(x+2),いずれの方法で参照しても同じ結果が得られます.ただし,配列変数 x は,06 行目のポインタ変数 y とは,「 y++ は許されるが x++ は許されない」など,多少異なります.
- 変数 y に対しては,配列 x の先頭アドレスが代入されているため( 06 行目),変数 y は,変数 x と同じ場所を指し,その内容は全く同じになります.しかし,06 行目とは異なり,以下に示すように変数 y を配列として定義すると,その下に示すような代入(配列変数に配列変数を代入)することは許されません.
int y[4]; y = x;
- また,変数 z のように,配列 x の途中の位置を指すようにすれば( 07 行目),変数 z は,配列 x の部分配列となり,その要素数は 2 となります.この点は,多次元配列の場合も同様です.
- 以上の点から,上のプログラムにおける出力結果は,すべて 300 となります.
- 配列とポインタとの関係を明らかにするために,以下のようなプログラムについて考えてみます.
- new 演算子と delete 演算子
- new 演算子は,データ型とその個数を与えることによって,例えば,
01 int *x = new int [4]; // int x[4] とほとんど同じ 02 //int *x = new int [4] {1, 2, 3, 4}; // 初期設定も可能 03 //int *x = new int [4] = {1, 2, 3, 4}; // error 04 //int *x = new int [] {1, 2, 3, 4}; // error 05 // 以下,int y[2][3] とほぼ同じ,ただし,連続領域とは限らない 06 int **y = new int *[2]; 07 for (int i1 = 0; i1 < 2; i1++) 08 y[i1] = new int [3]; 09 // 以下のような方法で初期設定も可能 10 int **y = new int *[2]; 11 y[0] = new int [3] {1, 2, 3}; 12 y[1] = new int [3] {4, 5, 6};- の 1 行目では,int 型のデータを 4 つだけ記憶するのに必要な領域を確保し,その領域の先頭のアドレスをポインタ x に代入しています.そのため,変数 x は,通常の配列と同様の方法で参照可能となります.6 行目以降は,2 次元配列と似た構造を確保するためのものです.まず,6 行目において,2 個のポインタの配列を確保し,7 ~ 8 行目で,int 型のデータを 3 つだけ記憶するのに必要な領域を確保し,その領域の先頭のアドレスをポインタ y[i1] に代入しています.各要素の参照方法は,通常の 2 次元配列の場合と同様です.ただし,全ての要素が連続した領域に確保されるとは限りません.
- delete 演算子は,new 演算子によって確保された領域を解放します.意図的に解放しない限り,確保された領域はプログラム終了時まで存在しますので,必要な場合は,例えば,
delete [] x; for (int i1 = 0; i1 < 3; i1++) delete [] y[i1]; delete [] y;
- のように,delete 演算子によって解放して下さい.多次元配列の場合,解放する順序を間違えないでください.ただし.C++ においては,ガーベッジコレクションが行われませんので,大きな領域を確保する new 演算子と delete 演算子を多数回繰り返しますと,ゴミがたまってしまい,問題になる場合があります.
- 関数は,一般的に,
戻り値の型 関数名 ( 引数リスト ) { 処理の中身 }- のように記述します.関数内では,与えられた情報(引数リスト)に基づき何らかの処理を行い,その結果を戻り値( 1 つの値)として返します.関数名は,同じプログラム内で唯一の名前である必要がありますが,引数や戻り値が異なる場合は同じ名前の関数が存在しても構いません(関数名の多重定義(関数名のオーバーロード)).
- 基本的な方法
- 関数にデータを渡し,その結果を得るためには様々な方法が考えられます.最も簡単な方法は,以下に示すプログラム例( 2 つのデータの和を求める関数)のように,引数としてデータ(厳密には,データのコピー)を渡し,戻り値として結果を受け取る方法です.この関数において,「 int b = 0 」という記述がありますが,これは,「 2 番目の引数が省略されたとき,その値を 0 とする」といった意味であり,デフォルト引数と呼びます.
#include <stdio.h> int add(int a, int b = 0) { return a + b; } int main() { int x = 10, y = 20; printf("和 = %d\n", add(x, y)); printf("和 = %d\n", add(x)); return 0; } - 関数にデータを渡し,その結果を得るためには様々な方法が考えられます.最も簡単な方法は,以下に示すプログラム例( 2 つのデータの和を求める関数)のように,引数としてデータ(厳密には,データのコピー)を渡し,戻り値として結果を受け取る方法です.この関数において,「 int b = 0 」という記述がありますが,これは,「 2 番目の引数が省略されたとき,その値を 0 とする」といった意味であり,デフォルト引数と呼びます.
- アドレスの引き渡し
- 引数として渡されたデータは,その値がコピーされて渡されるため,関数内において引数(上の例における a や b )の値を変更しても,main 関数内の x や y の値はその影響を受けません.しかし,ポインタが引数である場合は,ポインタ自身がコピーされても,ポインタが指す場所は同じであるため,ポインタ(下の例における c )を介して,ポインタが指す場所の内容(下の例における z )を変更することが可能です.従って,例えば,下に示すプログラム例のように,結果を引数内の変数で受け取ることも可能です.
#include <stdio.h> void add(int a, int b, int *c) { *c = a + b; } int main() { int x = 10, y = 20, z; add(x, y, &z); printf("和 = %d\n", z); return 0; } - 引数として渡されたデータは,その値がコピーされて渡されるため,関数内において引数(上の例における a や b )の値を変更しても,main 関数内の x や y の値はその影響を受けません.しかし,ポインタが引数である場合は,ポインタ自身がコピーされても,ポインタが指す場所は同じであるため,ポインタ(下の例における c )を介して,ポインタが指す場所の内容(下の例における z )を変更することが可能です.従って,例えば,下に示すプログラム例のように,結果を引数内の変数で受け取ることも可能です.
- 参照渡し
- 関数への引数を参照型にすることによっても,上と同様のことが可能です.参照型変数の宣言方法は以下の通りです.
データ型 &別名 = 式;
- 例えば,
int &y = x;
- と宣言することにより,参照型変数 y は変数 x の別名としてふるまい,
x = 10; y = 10;
- の 2 つの文は全く同じ意味になります.下の例においては,参照型変数を利用して結果を受け取っています.
#include <stdio.h> void add(int a, int b, int &c) { c = a + b; } int main() { int x = 10, y = 20, z; add(x, y, z); printf("和 = %d\n", z); return 0; }- 関数では,後に述べるクラスのオブジェクトを引数とする場合もあります.そのような場合に対しても,データ,アドレス,参照渡しといった 3 つの方法が考えられます.しかし,データを渡す方法の場合,大きなオブジェクトに対してはコピーするための時間が掛かってしまいます.また,アドレスを渡す方法では,参照方法の問題(「 . 」ではなく「 -> 」を使用)や内容の変更を許さないようにする指定(「 const 」指定)ができないなどの問題があります.そこで,オブジェクトを引数とする場合は,参照渡しがよく使用されます.
- ただし,クラスの定義内で new 演算子を使用している場合,データ渡しであっても,ポインタだけがコピーされて渡され,ポインタが指す場所に存在するデータはコピーされないため,関数内でそれらのデータを修正すれば,関数を呼んだ側のデータも変更される点に注意してください.参照渡しにおいて,「 const 」指定を行っても同様です.
- 配列の引き渡し
- 以上の例においては,1 つの結果だけを求めていましたが,和と差のように,複数の結果を得たい場合はどのようにすればよいでしょうか.勿論,アドレス渡し,参照渡しによっても可能ですが,配列を利用するのも一つの方法です.配列を引数にすることは,配列とポインタとの関係から,アドレスを引数にすることに相当し,配列要素を関数内で変更できるからです.下の例では,和と差を配列に入れて返しています.
#include <stdio.h> void add(int a, int b, int c[]) // void add(int a, int b, int *c) でも可能 { c[0] = a + b; c[1] = a - b; } int main() { int x = 10, y = 20; int z[2]; // int *z = new int [2]; でも可能 add(x, y, z); printf("和 = %d, 差 = %d\n", z[0], z[1]); return 0; } - 以上の例においては,1 つの結果だけを求めていましたが,和と差のように,複数の結果を得たい場合はどのようにすればよいでしょうか.勿論,アドレス渡し,参照渡しによっても可能ですが,配列を利用するのも一つの方法です.配列を引数にすることは,配列とポインタとの関係から,アドレスを引数にすることに相当し,配列要素を関数内で変更できるからです.下の例では,和と差を配列に入れて返しています.
- ポインタを戻り値
- 上の例では,結果を引数として返していましたが,アドレスを使用すれば,以下に示す例のように,戻り値を利用して複数の結果を得ることが可能です.
#include <stdio.h> int *add(int a, int b) { int *c = new int [2]; c[0] = a + b; c[1] = a - b; return c; } int main() { int x = 10, y = 20, *z; z = add(x, y); printf("和 = %d, 差 = %d\n", z[0], z[1]); delete [] z; return 0; } - 上の例では,結果を引数として返していましたが,アドレスを使用すれば,以下に示す例のように,戻り値を利用して複数の結果を得ることが可能です.
- 関数名の引き渡し
- 関数名を引数とするには,基本的に,関数のアドレスを使用すれば可能です.例えば,
int (*sub)(double, char *)
- という記述は,sub が,double 及び char に対するポインタという 2 つの引数をもち,int を返す関数へのアドレスであることを表しています.下の例では,2 つの int 型の引数を持つ関数名を引数として和と積の計算を行っています( 20,21 行目).また,上の記述を利用して,関数のアドレスを他の変数に代入し,それを関数と同じように使用することも可能です( 22,23 行目).
01 #include <stdio.h> 02 03 int add(int a, int b) 04 { 05 return a + b; 06 } 07 08 int mult(int a, int b) 09 { 10 return a * b; 11 } 12 13 int cal(int x, int y, int (*sub)(int, int)) 14 { 15 return sub(x, y); 16 } 17 18 int main() 19 { 20 printf("和 %d\n", cal(2, 3, add)); 21 printf("積 %d\n", cal(2, 3, mult)); 22 int (*fun)(int, int) = &add; 23 printf("和 %d\n", fun(2, 3)); 24 25 return 0; 26 } - main 関数
- 例えば,
add 2 3
- とキーボードから入力すると,2 つの値 2 と 3 の和を計算し,その結果をディスプレイに出力したいような場合が存在します(下に示すプログラム例).このような場合,2 や 3 が main 関数の引数とみなされます.ただし,main 関数の場合は,引数の受け渡し方が以下のように決まっています.
int main ( int argc, char *argv[], char *envp[] )
- ここで,各引数の意味は次のようになります.
- argc : コマンドラインからプログラムへ渡された引数の数を指定する整数.プログラム名も引数と見なされるので, argc は 1 以上の値となります.「 add 2 3 」のような場合は,3 となります.
- argv : null 文字で終わる文字列の配列. 最初の文字列 ( argv[0] ) はプログラム名で,その後に続く各文字列はコマンドラインからプログラムへ渡される引数(文字列)です.
- envp : 環境文字列の配列へのポインタ.
#include <stdio.h> #include <stdlib.h> int main(int argc, char *argv[], char *envp[]) { int i1, k, sum = 0; /* 引数の内容の出力 */ printf(" 引数の数 %d\n",argc); printf(" プログラム名 %s\n",argv[0]); for (i1 = 1; i1 < argc; i1++) { k = atoi(argv[i1]); /* 文字を整数に変換 */ printf(" %d 番目の引数 %d\n", i1+1, k); sum += k; } /* 結果の表示 */ printf("結果=%d\n", sum); return 0; }
- 基本的な方法
- 住所録を作成する際のように,氏名,住所,電話番号などをまとめて一つのデータとして扱いたい場合があります.数学の例で言えば,複素数などが相当します.複素数は,実数部と虚数部という 2 つの実数データの組からなっており,それらのデータは常に一緒に扱われます.C の範囲において,複数のデータをまとめて扱う方法に構造体があります.
- クラスは,構造体を拡張した概念ですが,その内部に定義できるのはデータ(メンバー変数)だけではなく,そのデータを処理するための関数(メンバー関数など)も定義できます.そして,メンバー変数やメンバー関数に対して参照制限を設けることが可能です.C++ においては,構造体は,下に述べる public なメンバー変数だけからなるクラスとみなされます.クラスの定義方法を一般的に記述すれば以下のようになります(この例では,クラス名を Example1 としている).
- クラスは,構造体を拡張した概念ですが,その内部に定義できるのはデータ(メンバー変数)だけではなく,そのデータを処理するための関数(メンバー関数など)も定義できます.そして,メンバー変数やメンバー関数に対して参照制限を設けることが可能です.C++ においては,構造体は,下に述べる public なメンバー変数だけからなるクラスとみなされます.クラスの定義方法を一般的に記述すれば以下のようになります(この例では,クラス名を Example1 としている).
class Example1 { int x; // プライベートメンバー変数 ・・・ // メンバー関数だけから参照可能なメンバー変数 protected: int y; // 派生クラスだけから参照可能なメンバー変数 ・・・ public: int z; // パブリックメンバー変数 ・・・ // いずれの関数からも参照可能なメンバー変数 private: double fun1(int); // プライベートメンバー関数 ・・・ // メンバー関数だけから参照可能なメンバー関数 protected: double fun2(int); // 派生クラスだけから参照可能なメンバー関数 ・・・ public: double fun3(int); // パブリックメンバー関数 ・・・ // いずれの関数からも参照可能なメンバー関数 friend double fun4(int); // フレンド関数(通常の関数であるが,メンバー関数と同じ参照権限を持つ) ・・・ friend class Example2; // フレンドクラス(クラス Example1 と同じ参照権限を持つ) ・・・ };- ただし,上の例における public,private 等に対応するすべてのメンバーを所有する必要はありません.public 等を記述しないと,クラス宣言のメンバーがプライベートとみなされる点以外,記述する順番も一般的には決まっていません.また,関数の本体は,クラス定義の中に記述することも,クラス定義の本体では関数の宣言だけを行いクラス宣言の外側に記述することも可能です.
- 以下に示すのは,実数部と虚数部からなる複素数を扱うためのクラスです.
- 以下に示すのは,実数部と虚数部からなる複素数を扱うためのクラスです.
#include <stdio.h> class Complex { private: double real; double imaginary; public: // 引数のないコンストラクタ Complex() {}; // 引数のあるコンストラクタ Complex(double a, double b = 0.0) { real = a; imaginary = b; } // 値の設定するためのメンバー関数 void set(double a, double b = 0.0); // 出力するためのメンバー関数 void print(); }; void Complex::set(double a, double b) { real = a; imaginary = b; } void Complex::print() { printf("実数部 = %f, 虚数部 = %f\n", real, imaginary); } int main() { // 初期設定を行う場合 Complex x(1.0); x.print(); // 初期設定を行わない場合 Complex y; y.set(5.1, 1.5); // real は private であるため,y.real = 5.1; などは不可能 y.print(); // 初期設定を行う場合(ポインター) Complex *z = new Complex (1.0, 2.0); z->print(); return 0; }- ここで,コンストラクタとは,クラスのインスタンスが生成されたとき( Complex 型の変数が定義されたとき),最初に呼ばれる関数です.初期設定を行う関数と言って良いかもしれません.この例では,引数の無い場合とある場合に対する 2 種類のコンストラクタを定義しています.なお,メンバー関数 set や print においては,クラスの定義内で関数の定義だけを行い,その本体をクラス定義の外に記述しています(コンストラクタに対しても可能).
- 複素数どうしの加算は,実数部どうし,及び,虚数部どうしの加算によって定義されます.従って,複素数どうしの加算を行うためには,複数の文によって記述するか,または,加算を行う関数を定義し,それを利用する必要があります.しかし,x,y,z を上で述べた Complex 型のオブジェクトとした場合,通常の数値の演算のように,
z = x + y;
- のような記述ができればこれに越したことはありません.このことを実現可能にするのが演算子のオーバーロードです.演算子のオーバーロード機能を利用すれば,例えば,+ 演算子の場合,
operator+
- というメンバー関数を定義してやると,
z = x + y;
- という演算は,
z = x.(operator+)(y);
- と解釈され,希望の結果が得られます..
- 以下に示す例は,Complex クラスに対して,+ 演算子のオーバーロードによって複素数の加算を実現しています.なお,この例においては,メンバー関数ではなく,フレンド関数を利用しています.その理由は,メンバー関数を利用すると,x が Complex 型でない場合,「 x.(operator+)(y) 」を解釈できず,エラーになってしまうからです.
- 以下に示す例は,Complex クラスに対して,+ 演算子のオーバーロードによって複素数の加算を実現しています.なお,この例においては,メンバー関数ではなく,フレンド関数を利用しています.その理由は,メンバー関数を利用すると,x が Complex 型でない場合,「 x.(operator+)(y) 」を解釈できず,エラーになってしまうからです.
#include <stdio.h> class Complex { private: double real; double imaginary; public: // 引数のないコンストラクタ Complex() {}; // 引数のあるコンストラクタ Complex(double a, double b = 0.0) { real = a; imaginary = b; } // 値の設定するためのメンバー関数 void set(double a, double b = 0.0); // 出力するためのメンバー関数 void print(); // + 演算子のオーバーロード friend Complex operator +(const Complex &, const Complex &); }; void Complex::set(double a, double b) { real = a; imaginary = b; } void Complex::print() { printf("実数部 = %f, 虚数部 = %f\n", real, imaginary); } Complex operator +(const Complex &a, const Complex &b) { Complex c; c.real = a.real + b.real; c.imaginary = a.imaginary + b.imaginary; return c; } int main() { Complex x(1.0); // 初期設定を行う場合 Complex y, z; // 初期設定を行わない場合 x.print(); y.set(5.1, 1.5); y.print(); z = x + y; z.print(); return 0; }
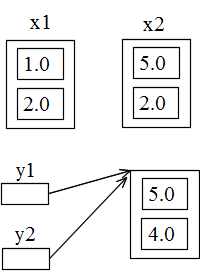
- 次に示す例における 20 行目のように,new 演算子を使用してインスタンスに必要な領域を確保し,そのアドレスを返す方法を使用する場合は注意が必要です.new 演算子を使用しない場合( 19 行目)は,22 行目の操作によって,x1 の内容がコピーされ,x2 に代入されます.つまり,右図の上( 23 行目を実行した後の状態)に示すように,x1 と x2 は全く別のものになり,x2 の値を変更しても x1 の値には全く影響ありません(逆も同様).
- しかし,new 演算子を使用した場合は,26 行目の操作によって,確保した領域のアドレスがコピーされ y2 に代入されるため,右図の下( 27 行目を実行した後の状態)に示すように,y1 と y2 は同じ場所を指すことになります.従って,y2 の指す場所の値を変更すると,y1 の指す場所の値も同様に変化します(逆も同様).
- しかし,new 演算子を使用した場合は,26 行目の操作によって,確保した領域のアドレスがコピーされ y2 に代入されるため,右図の下( 27 行目を実行した後の状態)に示すように,y1 と y2 は同じ場所を指すことになります.従って,y2 の指す場所の値を変更すると,y1 の指す場所の値も同様に変化します(逆も同様).
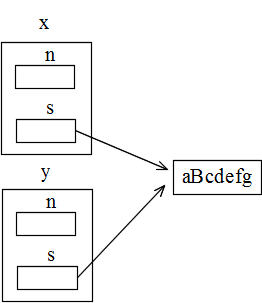
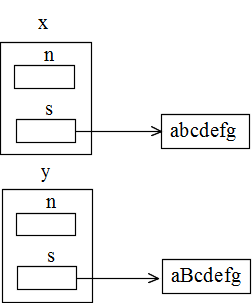
01 #include <stdio.h> 02 03 class Complex { 04 public: 05 double real; 06 double imaginary; 07 // 引数のないコンストラクタ 08 Complex() {}; 09 // 引数のあるコンストラクタ 10 Complex(double a, double b = 0.0) 11 { 12 real = a; 13 imaginary = b; 14 } 15 }; 16 17 int main() 18 { 19 Complex x1(1.0, 2.0), x2; 20 Complex *y1 = new Complex(3.0, 4.0), *y2; 21 22 x2 = x1; 23 x2.real = 5.0; 24 printf("x1 実数部 = %f, 虚数部 = %f\n", x1.real, x1.imaginary); 25 printf("x2 実数部 = %f, 虚数部 = %f\n", x2.real, x2.imaginary); 26 y2 = y1; 27 y2->real = 5.0; 28 printf("y1 実数部 = %f, 虚数部 = %f\n", y1->real, y1->imaginary); 29 printf("y2 実数部 = %f, 虚数部 = %f\n", y2->real, y2->imaginary); 30 31 return 0; 32 }- たとえ,new演算子を使用しない方法でインスタンスを生成していても,クラス定義の中で new 演算子を使用している場合は同様のことが起こります.下に示す例においては,「 y = x 」の操作によって右図のような状態になり,変数 s が同じ文字列を指すことになってしまいます.なお,右図は,「 y.mod(1, 'B'); 」を実行した後の状態を表しています.
- 以下のプログラムの中に示すデストラクタ(勿論,一般的には,その中に記述してある printf 関数は必要ありません)とは,生成したインスタンスが必要なくなったとき,自動的に呼ばれ,後処理を行うための関数です.一般に,クラス定義の中で new 演算子を使用して領域を確保しているような場合は,その領域を開放する( delete 演算子の使用)ために利用されます.しかし,このプログラムの場合,例えば,変数 x で使用した領域( 変数 s が示す文字列を記憶するための領域)を開放すると,デストラクタによって,変数 y で使用していた領域も消滅してしまいます.従って,変数 y によって確保された領域を開放する際に,デストラクタの中に記述された delete 演算子の実行が不可能になってしまいます.場合によっては,プログラムがハングアップしてしまいます.
- 以下のプログラムの中に示すデストラクタ(勿論,一般的には,その中に記述してある printf 関数は必要ありません)とは,生成したインスタンスが必要なくなったとき,自動的に呼ばれ,後処理を行うための関数です.一般に,クラス定義の中で new 演算子を使用して領域を確保しているような場合は,その領域を開放する( delete 演算子の使用)ために利用されます.しかし,このプログラムの場合,例えば,変数 x で使用した領域( 変数 s が示す文字列を記憶するための領域)を開放すると,デストラクタによって,変数 y で使用していた領域も消滅してしまいます.従って,変数 y によって確保された領域を開放する際に,デストラクタの中に記述された delete 演算子の実行が不可能になってしまいます.場合によっては,プログラムがハングアップしてしまいます.
#include <stdio.h> #include <string.h> class String { public: int n; char *s; // 引数のないコンストラクタ String () { n = 0; } // 引数のあるコンストラクタ String (char *a) { n = strlen(a); s = new char [n+1]; strcpy(s, a); } // デストラクタ ~String() { if (n > 0) { printf(" delete start %d\n", strlen(s)); delete [] s; printf(" delete end\n"); } } // 指定した位置の文字を変更するためのメンバー関数 void mod(int k, char a) { s[k] = a; } // 出力するためのメンバー関数 void print() { printf("文字列 %s\n", s); } }; int main() { String x("abcdefg"), y; y = x; y.mod(1, 'B'); x.print(); y.print(); return 0; }- 上で述べた問題を解決したのが下に示すプログラム例です.代入演算子( = )をオーバーロードし,new 演算子で確保した領域も新たな領域にコピーしています(右図参照).
#include <stdio.h> #include <string.h> class String { public: int n; char *s; // 引数のないコンストラクタ String () { n = 0; } // 引数のあるコンストラクタ String (char *a) { n = strlen(a); s = new char [n+1]; strcpy(s, a); } // デストラクタ ~String() { if (n > 0) { printf(" delete start %d\n", strlen(s)); delete [] s; printf(" delete end\n"); } } // 指定した位置の文字を変更するためのメンバー関数 void mod(int k, char a) { s[k] = a; } // 出力するためのメンバー関数 void print() { printf("文字列 %s\n", s); } // = 演算子のオーバーロード String & operator= (const String &); }; String & String::operator= (const String &b) { if (&b == this) // 自分自身への代入を防ぐ return *this; else { if (n > 0) delete [] s; // 代入する前のメモリを解放 s = new char [b.n+1]; // メモリの確保 n = b.n; // 値の代入 strcpy(s, b.s); return *this; } } int main() { String x("abcdefg"), y; y = x; y.mod(1, 'B'); x.print(); y.print(); return 0; }- 最後に,+ 演算子のオーバーロードによって,Java などのように,文字列の結合を + 演算子で行えるようにした例を示しておきます.
#include <stdio.h> #include <string.h> class String { public: int n; char *s; // 引数のないコンストラクタ String () { n = 0; } // 引数のあるコンストラクタ String (char *a) { n = strlen(a); s = new char [n+1]; strcpy(s, a); } // デストラクタ ~String () { if (n > 0) { printf(" delete start %d\n", strlen(s)); delete [] s; printf(" delete end\n"); } } // 出力するためのメンバー関数 void print() { printf("文字列 %s\n", s); } // = 演算子のオーバーロード String & operator= (const String &); // + 演算子のオーバーロード friend String & operator +(const String &, const String &); }; String & String::operator= (const String &b) { if (&b == this) // 自分自身への代入を防ぐ return *this; else { if (n > 0) { printf(" delete for =\n"); delete [] s; // 代入する前のメモリを解放 } s = new char [b.n+1]; // メモリの確保 n = b.n; // 値の代入 strcpy(s, b.s); return *this; } } String & operator +(const String &a, const String &b) { String *str = new String(); str->n = a.n + b.n; str->s = new char [str->n+1]; strcpy(str->s, a.s); strcat(str->s, b.s); return *str; } int main() { String x("abc"), y("defg"), z("ABCDE"); z = x + y; z.print(); return 0; }
- クラスにおいて,継承は重要な機能です.Window のプログラムを考えてみてください.多くのアプリケーションにおいて Window を利用していますが,その基本的構成はほとんど同じです.もし,Window アプリケーションを作成するたびに,その全てに関するプログラムを書かなければならないとしたら大変な作業になります.基本的な Window の機能を持つクラスを定義しておき,個々の Window アプリケーションは,そのクラスを利用できるとしたら非常に便利です.これを実現するのが継承です.あるクラスの性質を継承するための一般的宣言方法は,
class クラス名 : [アクセス権] 基底クラス名 [,[アクセス権] 基底クラス・・・] { 変更部分 }- となります.このとき,元になったクラスを基底クラス(複数可),そのクラスを継承したクラスを派生クラスと呼びます.
- アクセス権を省略すると,基底クラスが struct ならば public,class ならば private とみなされます.private の場合は,基底クラスのすべてのメンバーは派生クラスの private に入れられますが(基底クラスにおいて public 宣言された部分の一部を public に入れることも可能),public の場合は,基底クラスのパブリックメンバーはそのまま派生クラスのパブリックメンバーになります.また,基底クラスが複数の場合を多重継承と呼びます.
- 継承を利用すれば,指定されたクラスの機能を受け継ぎ,新しいクラスに必要な機能の追加・修正だけを行えばよくなります.例えば,以下のプログラム(あまり良い例ではありませんが)においては,クラス Number は,クラス Base を継承しています.
- 基底クラスにおいて,「 protected 」指定された変数や関数は,そのクラスを継承した派生クラスだけから参照可能です.また,この例の場合は,クラス Number の定義において,public 指定をしてクラス Base を継承していますので,クラス Base の「 public 」指定された部分は,クラス Number の「 public 」部分に入ります.そのため,3 つのメンバー関数をクラスの外から参照可能になります.なお,この例では存在しませんが,基底クラスにおいて「 private 」指定された変数は,基底クラスのメンバー関数とそれを継承した派生クラスのメンバー関数だけから参照可能であり,派生クラスで追加されたメンバー関数やクラスの外からは参照できません.
- また,コンストラクタやデストラクタは継承されません.そのため,基底クラスにパラメータを必要とするコンストラクタが存在する場合は,派生クラスから基底クラスのコンストラクタへパラメータを引き渡してやる必要があります(「 Number (int n1, int sp = 2) : Base(sp) 」における Base(sp) の部分).
- アクセス権を省略すると,基底クラスが struct ならば public,class ならば private とみなされます.private の場合は,基底クラスのすべてのメンバーは派生クラスの private に入れられますが(基底クラスにおいて public 宣言された部分の一部を public に入れることも可能),public の場合は,基底クラスのパブリックメンバーはそのまま派生クラスのパブリックメンバーになります.また,基底クラスが複数の場合を多重継承と呼びます.
#include <stdio.h> class Base { protected: int n; int step; // コンストラクタ Base (int sp) { step = sp; } public: // 出力するためのメンバー関数 void print() { printf("value = %d\n", n); } // 加算 void add() { n += step; } // 減算 void sub() { n -= step; } }; class Number : public Base // Base の継承 { public: // コンストラクタ Number (int n1, int sp = 2) : Base(sp) { n = n1; } }; int main() { Number x(10), y(5, 4); x.add(); x.print(); y.sub(); y.print(); return 0; }
- 関数テンプレート
- 例えば,様々な型の 2 つの値の大きさを比べ,小さい方を返す関数について考えてみます.C++ の場合,関数名が同じであっても,引数の型や数が異なれば異なる関数とみなされますので(関数名のオーバーロード),型毎に同じ名前の関数を定義するという方法によって実現することが可能です.しかし,次の形式で書かれる関数テンプレートを使用することによって,1 つの関数の定義だけですますことも可能です.
template <テンプレート引数宣言> 関数宣言または定義
- テンプレート引数は関数宣言や定義の中で型名として使用でき,この型が任意の型に変換されます.例えば,次の例における関数 min_t では,型 cl の部分に double や int や Test が入ります.この例のように,クラス型の変数に対しても同じ関数を使用できますが,そのクラスのオブジェクトの大きさを比較する演算子「 < 」に対するオーバーロードが定義されていなければ成りません.また,この例の場合,関数の 2 つの引数は同じ型 cl ですので,異なった型との比較はエラーになります.なお,関数 min_o は,関数名のオーバーロード機能を利用した場合に対する例です.
/****************************/ /* 関数テンプレート */ /* coded by Y.Suganuma */ /****************************/ #include <iostream> #include <string.h> using namespace std; /**************************/ /* クラスTestに関する定義 */ /**************************/ class Test { public: char *str; int n; Test () {} Test (char *str1, int n1) { str = new char [strlen(str1)+1]; strcpy(str, str1); n = n1; } bool operator< (Test &t) // < に対するオーバーロード { return strcmp(str, t.str) < 0 ? true : false; } }; /****************************************/ /* 最小値を返す関数(関数テンプレート) */ /* a,b : 比較するデータ */ /****************************************/ template <class cl> cl min_t(cl a, cl b) { return a < b ? a : b; } /**********************************************/ /* 最小値を返す関数(関数名のオーバーロード) */ /* a,b : 比較するデータ */ /**********************************************/ int min_o(int a, int b) { return a < b ? a : b; } double min_o(double a, double b) { return a < b ? a : b; } Test min_o(Test a, Test b) { return strcmp(a.str, b.str) < 0 ? a : b; } /******************/ /* mainプログラム */ /******************/ int main() { // 関数テンプレート int i = 0, j = 1; double x = 10.0, y = 5.5; Test a("xyz",1), b("abc", 2), c = min_t(a, b); cout << "テンプレート:int " << min_t(i, j) << " double " << min_t(x, y) << " クラス Test (" << c.str << "," << c.n << ")\n"; // 関数名のオーバーロード c = min_o(a, b); cout << "オーバーロード:int " << min_o(i, j) << " double " << min_o(x, y) << " クラス Test (" << c.str << "," << c.n << ")\n"; return 0; }- このプログラムを実行すると,以下に示すような結果が得られます.
テンプレート:int 0 double 5.5 クラス Test (abc,2) オーバーロード:int 0 double 5.5 クラス Test (abc,2)
- クラステンプレート
- クラスに対しても,関数と同様,以下のような形式でクラステンプレートを定義できます.
template <テンプレート引数宣言> class name { ・・・・・ };- ただし,コンストラクタ,デストラクタ,及び,メンバー関数の本体をクラス定義の外側に記述する場合は,関数テンプレートによって記述する必要があります.したがって,以下に示すような記述方法になります.
// コンストラクタ(デストラクタも同様) template <テンプレート引数宣言> クラス名 <テンプレート引数> :: クラス名 (引数) { ・・・・・ }; // メンバー関数 template <テンプレート引数宣言> クラス名 <テンプレート引数> :: メンバー関数名 (引数) { ・・・・・ };- 次の例では,クラステンプレートを使用して,任意のサイズ(この例では,3 )の様々な型の 1 次元配列を確保するクラスを定義しています.メンバー関数 input をクラス定義内で記述し,コンストラクタとメンバー関数 print はクラスの外で記述しています.
#include <iostream> using namespace std; template <class Tp, int size> class Vector { Tp *p; public: Vector(); // コンストラクタ void print(int); // 出力 void input() // 入力 { int i1; for (i1 = 0; i1 < size; i1++) { cout << " " << i1+1 << " 番目の要素は? "; cin >> p[i1]; } } }; template <class Tp, int size> Vector <Tp, size>::Vector() { p = new Tp [size]; } template <class Tp, int size> void Vector <Tp, size>::print(int k) { if (k < 0 || k > size-1) cout << " 要素番号が不適当です\n"; else cout << " " << (k+2) << " 番目の要素は " << p[k] << endl; } int main() { int k = 0, sw; cout << "整数(0) or 実数(1) ? "; cin >> sw; // 整数 if (sw == 0) { Vector < int, 3 > iv; cout << "整数ベクトル\n"; iv.input(); while (k >= 0) { cout << "要素番号は "; cin >> k; iv.print(k); } } // 実数 else { Vector < double, 3 > dv; cout << "実数ベクトル\n"; dv.input(); while (k >= 0) { cout << "要素番号は "; cin >> k; dv.print(k); } } return 0; }
01 /****************************/ 02 /* 変数の有効範囲(スコープ) */ 03 /* coded by Y.Suganuma */ 04 /****************************/ 05 #include <stdio.h> 06 07 /*******************/ 08 /* クラス Example1 */ 09 /*******************/ 10 class Example1 { 11 int pri; 12 protected : 13 int pro; 14 public : 15 int pub; 16 17 Example1() { 18 pub = 1000; 19 pri = 2000; 20 pro = 3000; 21 } 22 23 void sub1() { 24 printf("sub1 pub %d pri %d pro %d\n", pub, pri, pro); 25 } 26 }; 27 28 /*******************/ 29 /* クラス Example2 */ 30 /*******************/ 31 class Example2 : public Example1 { 32 33 public : 34 35 Example2() {} 36 37 void sub2() { 38 printf("sub2 pub %d pro %d\n", pub, pro); 39 // printf("sub2 pri %d\n", pri); // 許されない 40 } 41 }; 42 43 void sub(); 44 45 /****************/ 46 /* main program */ 47 /****************/ 48 int main() 49 { 50 // ブロック 51 int x = 10; 52 if (x > 5) { 53 printf("block x %d\n", x); 54 int x = 15; 55 int y = 20; 56 printf("block x %d\n", x); 57 printf("block y %d\n", y); 58 } 59 sub(); 60 printf("x %d\n", x); 61 // printf("y %d\n", y); // y が未定義 62 extern int z; 63 printf("z %d\n", z); 64 // クラス 65 Example2 ex = Example2(); 66 ex.sub1(); 67 ex.sub2(); 68 printf("public member( pub ) %d\n", ex.pub); 69 70 return 0; 71 } 72 73 int z = 30; 74 75 /************/ 76 /* 関数 sub */ 77 /************/ 78 void sub() 79 { 80 int x = 40; 81 printf(" sub x %d\n", x); 82 printf(" sub z %d\n", z); 83 }- まず,51 行目において,変数 x が定義され,10 で初期設定されています.この変数 x は,この位置から main 関数が終わる 71 行目まで有効になります.52 ~ 58 行目の if ブロック内の 53 行目において,変数 x の値が出力されていますが,当然,その結果は,51 行目で宣言されたときの値になります.しかし,54 行目において,再び,変数 x が宣言されていますので,この位置から if ブロックの最後である 58 行目までは,ここで宣言された x が有効になります.同様に,55 行目で宣言された変数 y の有効範囲も 58 行目までとなります.実際,60 行目における出力文では,51 行目において宣言された変数 x の値が出力されます.また,61 行目のうに,変数 y の値を出力しようとすればエラーになってしまいます.
- 59 行目において関数 sub を呼んでいます.80 行目では,変数 x を宣言し,81 行目において,その値を出力しています.当然,80 行目の宣言を行わなければ,エラーになってしまいますし,また,80 行目の宣言によって,51 行目で宣言された x の値が影響を受けることはありません( 60 行目の出力文に対応する結果参照).しかし,変数 z は,main 関数内にも,関数 sub 内にも宣言されておらず,すべての関数の外側である 73 行目において宣言されています.このように,関数の外側で宣言された変数をグローバル変数と呼び,すべての関数から参照が可能になります.逆に,変数 x や y のように,あるブロック(関数を含む)内だけで有効な変数を,ローカル変数と呼びます.
- 82 行目では,グローバル変数 z が,同じファイル内の,その変数を参照する前に宣言されていますので,そのまま参照可能ですが,異なるファイルや,参照する場所の後ろで宣言されている場合は,62 行目のような extern 指定が必要になります.以上,51 ~ 63 行目内の出力文(関数 sub 内の出力文を含む)によって,以下に示すような出力が得られます.
- 59 行目において関数 sub を呼んでいます.80 行目では,変数 x を宣言し,81 行目において,その値を出力しています.当然,80 行目の宣言を行わなければ,エラーになってしまいますし,また,80 行目の宣言によって,51 行目で宣言された x の値が影響を受けることはありません( 60 行目の出力文に対応する結果参照).しかし,変数 z は,main 関数内にも,関数 sub 内にも宣言されておらず,すべての関数の外側である 73 行目において宣言されています.このように,関数の外側で宣言された変数をグローバル変数と呼び,すべての関数から参照が可能になります.逆に,変数 x や y のように,あるブロック(関数を含む)内だけで有効な変数を,ローカル変数と呼びます.
block x 10 block x 15 block y 20 sub x 40 sub z 30 x 10 z 30
- 次に,クラスに付いて考えてみます.10 ~ 26 行目においてクラス Example1 が定義され,31 ~ 41 行目では,クラス Example1 を継承する形で,クラス Example2 が定義されています.31 行目において,public 指定がしてありますので,クラス Example の各変や関数のアクセス権は,そのままクラス Example2 に引き継がれます.
- 65 行目において,Example2 のインスタンス ex を生成し,66 行目では,クラス Example1 から継承した関数 sub1 を通して,3 つの変数を出力しています.このときは,3 つの変数の値がそのまま出力されます.しかし,67 行目では,クラス Example2 に追加された関数 sub2 を通して各変数を出力しています.この場合は,親クラス Example1 の private メンバー変数 pri を参照することができない点に注意してください.また,68 行目のようなクラスの外側からの参照においては,pubulic メンバー変数 pub だけを参照可能です.なお,private 指定は,同じクラス内の関数だけから,protected 指定は,同じクラス,及び,そのクラスを継承したクラスだけから,また,public 指定は,どこからでも参照可能なことを意味します.以上,65 ~ 68 行目内の出力文によって,以下に示すような出力が得られます.
sub1 pub 1000 pri 2000 pro 3000 sub2 pub 1000 pro 3000 public member( pub ) 1000
- まず,51 行目において,変数 x が定義され,10 で初期設定されています.この変数 x は,この位置から main 関数が終わる 71 行目まで有効になります.52 ~ 58 行目の if ブロック内の 53 行目において,変数 x の値が出力されていますが,当然,その結果は,51 行目で宣言されたときの値になります.しかし,54 行目において,再び,変数 x が宣言されていますので,この位置から if ブロックの最後である 58 行目までは,ここで宣言された x が有効になります.同様に,55 行目で宣言された変数 y の有効範囲も 58 行目までとなります.実際,60 行目における出力文では,51 行目において宣言された変数 x の値が出力されます.また,61 行目のうに,変数 y の値を出力しようとすればエラーになってしまいます.