- 初期化
- N 個の個体からなる初期集団を発生させ,各個体の適合度を計算しておきます.通常,各遺伝子の値はランダムに決定します.
- ここで問題になるのは,集団サイズ N をどの程度にすべきかという点です.一般的に,遺伝子長が長ければ長いほど,大きな集団サイズが必要になります.また,同じ問題の場合,集団サイズを小さくすると,1 世代あたりの計算量は減りますが,収束するまでの世代数が大きくなると共に,局所的な最適解に陥る可能性が高くなります.集団サイズを大きくすると,収束するまでの世代数は小さくなりますが,1 世代あたりの計算量が増えます.
- 生物集団の評価
- 収束したか否かの判定を行います.判定方法としては,以下のようなものが考えられます.
- 生物集団中の最大の適合度が,ある閾値より大きくなった場合
- 生物集団全体の平均適合度が,ある閾値より大きくなった場合
- 生物集団の適合度の増加率がある閾値以下の世代が一定期間続いた場合
- 世代交代の回数が規定の回数を超えた場合
- 交叉
- 子供を生成する過程です.交叉方法に対しては,問題によって様々な方法が提案されていますが,一般的な方法として,以下に示すような方法が考えられています.
- 集団内よりランダムに M 個のペア(親)を選択し,設定された交叉確率 Pc (交叉が発生する確率)に従って, 2 * M 個の子供を生成します.ここで,M の値も,集団サイズ N と同様,GA の効率に大きな影響を与えます.各ペアから子供を生成する方法(交叉方法)には,例えば,以下に示すようなものが存在します.
- 1 点交叉 染色体の切断箇所をランダムに 1 カ所指定し,その箇所(下の例における赤線の部分)で親の遺伝子を交叉させる.
01001|101 01001110 親 → 子供 01100|110 01100101
- 多点交叉 染色体の切断箇所をランダムに複数カ所(下の例では,2 カ所)指定し,それらの箇所で親の遺伝子を交叉させる.
010|011|01 01000101 親 → 子供 011|001|10 01101110
- 一様交叉 染色体と同じ長さのマスクと呼ばれるビット列を,0 に対しては確率 p,また,1 に対しては確率 (1-p) で発生させ,マスクの値が 1 であるときは親 A の遺伝子を子 1(親 B の遺伝子を子 2)に,また,0 であるときは親 B の遺伝子を子 1(親 A の遺伝子を子 2)に継承させる.例えば,マスクが 00101011 となった場合は,以下のようになる.
A 01001101 1 01000101 親 → 子供 B 01100110 2 01101110
- 個体の遺伝子型が連続値を表すときには,2 つの親の平均値を子の遺伝子とする平均化交叉等の方法も使用されます.平均化交叉では,2 つの親から 1 つの子供が生成されます.
- 今までの例に挙げた染色体では,対立遺伝子が 0 と 1 であり,染色体内に 0 や 1 が複数個現れています.しかし,問題によっては,染色体内に同じ対立遺伝子が現れないようにしたい場合があります.例えば,14352 という染色体は許されるが,12352 のように,同じ対立遺伝子が 2 回以上現れることは許したくない場合です.巡回セールスマン問題等を GA で扱いたい場合によく現れます.このような場合に対する交叉方法としては,以下のようなものがあります.
- 循環交叉 ランダムに 1 点を選択し,その位置にある遺伝子をそのまま各子供が選択する(青色の部分).その位置にある親 2( 1 )の遺伝子を,その遺伝子の親 1( 2 )の場所に,子 1( 2 )が受け継ぐ(緑色の部分).この手続きを,すでに受け継いだ遺伝子の位置が選択されるまで繰り返す.残りの遺伝子について,子 1( 2 )は,親 2( 1 )の遺伝子をその順番通りに受け継ぐ.
1 2 4 1 3 6 5 + + 1 + + 5 1 3 2 1 4 6 5 親 * → → 子供 2 3 2 5 4 1 6 + + 5 + 1 + 2 2 4 5 3 1 6
- 部分的交叉 まず,各子供は,各親の遺伝子をそのまま受け継ぐ.ランダムに切れ目を選択し,切れ目の右側で,同じ位置にある子 1 と子 2 の遺伝子を取り出す(青色の部分).次に,子 1 及び子 2 の染色体上で,この 2 つの遺伝子の位置を交換する(右図).この操作を,切れ目の右側にあるすべての遺伝子対に対して実施する.
2 4 1 | 3 6 5 2 3 5 4 1 6 → 3 2 5 | 4 1 6 4 2 6 3 5 1
- 順序交叉 ランダムに切れ目を決定し,子 1 に対し,切れ目の左側では,親 1 の遺伝子をそのまま受け継ぎ,右側では,親 1 の遺伝子を親 2 の遺伝子の出現順序に並べ替える.
2 4 | 1 3 6 5 2 4 3 5 1 6 → 3 2 | 5 4 1 6 3 2 4 1 6 5
- 一様順序交叉 位置の集合をランダムに選択し,一方の親の選択された位置における遺伝子の順序に従って,他の親の遺伝子を並べ替える
a b c d e f g h i j a i c d e b f h g j * * * * → e i b d f a j g c h b i c d f a j g e h
- 一様位置交叉 位置の集合をランダムに選択し,一方の親の選択された位置における遺伝子の位置に,他の親の同じ遺伝子を配置する.残りの遺伝子は,親と同じ順序に配置する.
a b c d e f g h i j a i b c f d e g h j * * * * → * * * * e i b d f a j g c h i b c d e f a h j g
- 突然変異
- ある与えられた確率 Pm(突然変異率)で,突然変異を起こさせます.一般的に,突然変異は,局所的最適解からの脱出に効果があります.しかし,突然変異率を大きくすると,ランダム探索に近い状態になりますので,通常,小さな値が使用されます.突然変異方法としては,以下のようなものがあります.
- 一般的な方法 各遺伝子をランダムに対立遺伝子に置き換える
- 摂動 染色体が連続値を表すときに使用され,値をランダムに与えられた幅だけ変更する
- 逆位 ランダムに選ばれた 2 点間の要素の順序を逆転する
- スクランブル ランダムに選ばれた 2 点間の要素の順序をランダムに並べ替える
- 転座 ランダムに選ばれた 2 点間の要素を他の位置のものと入れ替える
- 重複 ランダムに選ばれた 2 点間の要素を他の位置にコピーする(遺伝子長が変化)
- 位置移動 ランダムに遺伝子を 2 個選択し,2 番目の遺伝子を 1 番目の遺伝子の前に移動する
- 挿入 ある長さの遺伝子を挿入する(遺伝子長が変化)
- 欠失 ある長さの遺伝子を消去する(遺伝子長が変化)
- 各個体の評価 各個体の適合度を計算します.
- 淘汰 ここまでの過程により,一般的に,個体数は N + 2 * M (交叉方法によっては,N + M )となっているはずです.ここで,環境に適合しない個体を淘汰することによって,個体数を N に戻し,世代数 = 世代数 + 1 とし,2 に戻ります.淘汰方法としては,以下のようなものがあります.
- エリート選択 単純に,適合度が高い N 個の個体を残す方法です.この方法は簡単ですが,局所的最適解に陥りやすく,一般には,次に述べるルーレット選択と併用して使用します.つまり,ある数(< N)だけエリート選択で選択した後,残りをルーレット選択で選びます.
- ルーレット選択 適合度に基づいたルーレット版を作成し,そのルーレット版を使用してランダムに選択する方法です.例えば,現在の個体数が 5 で,かつ,各個体の適合度が,
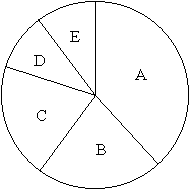
- A 40
- B 20
- C 20
- D 10
- E 10
- であったとします.適合度をそのまま利用してルーレット版を作成すれば,右図のようになります.集団サイズ N が 3 であれば,このルーレット版を 3 度回して,3 つの個体を選ぶことになります.確かに,個体 A が最も選ばれやすくなりますが,個体 D や E が選ばれる確率も 0 ではありません.
- ルーレット版を作成する際,適合度をそのまま利用する方法以外,適合度に順位をつけて,適当な減少率で線形化する方法,非線形変換を行う方法等,様々な方法が提案されています.
- A 40
- N 個の個体からなる初期集団を発生させ,各個体の適合度を計算しておきます.通常,各遺伝子の値はランダムに決定します.