
- 構造
- 脳の中には多数のニューロン(神経細胞)が存在しています.各ニューロンは,多数の他のニューロンから信号を受け取り,また,他の多数のニューロンへ信号を受け渡しています.脳は,この信号の流れによって,様々な情報処理を行っています.
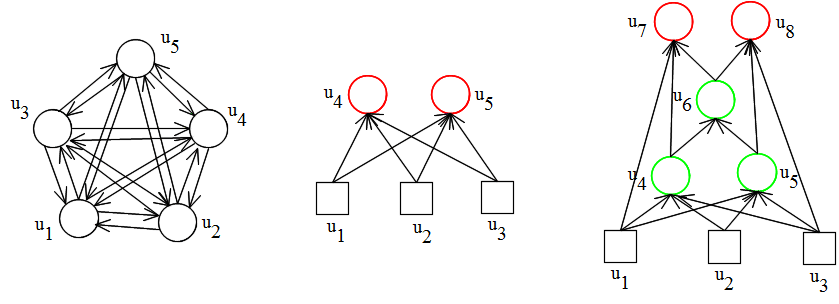
- この仕組みをコンピュータ内に実現しようとしたものがニューラルネットワークです.下の図は,ニューラルネットワークの典型的な構造を示したものです.これらの図において,円や四角は一つのニューロンに対応し,また,矢印が付いた枝は信号の流れを表しています.
- 左の図は,相互結合ネットワークを表し,また,中央と右の図は,階層的なネットワークを表しています.四角で書かれたユニットは,入力ユニットと呼ばれ,外部からの信号を受け取ります.また,赤いユニットは,出力ユニットと呼ばれ,外部へ信号を出力します.なお,相互結合ネットワークの場合は,すべてのユニットが,入力ユニットと出力ユニットを兼ねるケースが多く見受けられます.
- 中央及び右図のように,多層構造になっている場合,入力ユニットから構成されている層を入力層,また,出力ユニットから構成されている層を出力層と呼びます.右図の中間にあるユニット(緑色のユニット)は,隠れユニットと呼ばれ,その層は,隠れ層(中間層)と呼ばれます.
- 脳の中には多数のニューロン(神経細胞)が存在しています.各ニューロンは,多数の他のニューロンから信号を受け取り,また,他の多数のニューロンへ信号を受け渡しています.脳は,この信号の流れによって,様々な情報処理を行っています.
- ユニット
- あるユニット ui を拡大すると,上図のようになります.ユニット ui は,複数のユニット uj ( j = 1, 2, ・・・, n )から情報を入力し,何らかの処理をした後,情報を出力します.
- ユニットの入力及び出力値の記述方法は,ネットワークの種類によって異なりますが,通常,以下に示すいずれかの方法によります.
離散値の場合: {0, 1} or {-1, 0, 1} 連続値の場合: [0, 1] or [-1, 1]- 各ユニットにおける処理は以下のようになります.まず,入力値を元に,以下の値を計算します.
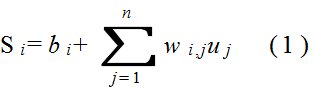
- ここで,
- bi : ユニット ui のバイアス
- wi,j : ユニット uj からユニット ui に与える影響の強さを表し,重みと呼ばれる
- uj : ユニット uj の出力値
- とします.また,図の赤い部分で示したように,出力値の強さが常に 1 である仮想的なユニット u0 を仮定し,ユニット u0 からユニット ui への重み wi,0 を bi とみなすことによって,(1) 式は,以下のようにも記述できます.
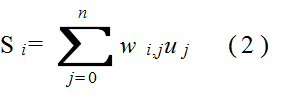
- (1) または (2) 式によって計算された Si をもとに,ユニット ui の出力値が以下のようにして計算されます.
- ui = f(Si)
- ここで,関数 f(x) として,例えば,以下のようなものが使用されます.
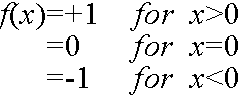
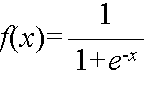
- 学習
- ニューラルネットワークを作成しただけでは,入力ユニットにデータを与えても,出力ユニットから出る値が適切なものである可能性はほとんどありません.何らかの方法で,ユニット間を繋ぐ枝の重み(バイアスも含む)を調整し,希望する出力が得られるようにしてやる必要があります.このことを行うのが,学習です.
- 学習方法には,大きく分けて 2 つの方法があります.それは,教師付き学習と教師無し学習です.教師付き学習は,幾つかの学習例と各学習例に対する目標出力を与え,目標出力と実際の出力が一致するように重みを調整する方法です.また,教師無し学習では,学習例からコンピュータ自身が何らかの基準に基づき重みを調整します.
- また,この重みの調整には,学習例から 1 回の計算だけで行う方法と,学習例を繰り返し入力し,徐々に調整していく方法とがあります.
- ニューラルネットワークを作成しただけでは,入力ユニットにデータを与えても,出力ユニットから出る値が適切なものである可能性はほとんどありません.何らかの方法で,ユニット間を繋ぐ枝の重み(バイアスも含む)を調整し,希望する出力が得られるようにしてやる必要があります.このことを行うのが,学習です.
 ) JavaScript 版では,画面上で実行可能です.テキストエリアに表示されたデータの意味については,C++,または,Javaのプログラムに対する説明を参照してください.なお,他の言語( PHP,Ruby,Python,C#,VB )によるプログラム例に関しては,「プログラミング言語の落とし穴」第 9 章の「パーセプトロン」をご覧ください.
) JavaScript 版では,画面上で実行可能です.テキストエリアに表示されたデータの意味については,C++,または,Javaのプログラムに対する説明を参照してください.なお,他の言語( PHP,Ruby,Python,C#,VB )によるプログラム例に関しては,「プログラミング言語の落とし穴」第 9 章の「パーセプトロン」をご覧ください.
- 構造
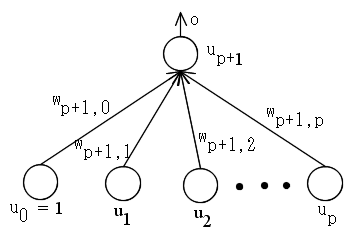
- パーセプトロンは,上図に示すように,入力層と出力層だけから成る 2 層のネットワークです.また,入力ユニットの数(p 個)は任意ですが,出力ユニット( p+1 番目が出力ユニット)は 1 つだけです. 今,
重み: w = [wp+1,0, wp+1,1, wp+1,2, ・・・, wp+1,p]T k 番目の訓練例: ek = [u0, u1, u2, ・・・, up]T k = 1, 2, ・・・, N u0 は,常に 1 k 番目の訓練例に対する目標出力: ck = +1 or -1 k = 1, 2, ・・・, N
- とすると,出力(ユニット up+1 の出力) o は,以下のようにして計算されます.
S = up+1 = wTek (3) o = f(S) = +1 for S > 0 = 0 for S = 0 = -1 for S < 0
- パーセプトロンは,各訓練例に対してその出力が目標出力に一致するように,重みを修正するネットワークです.つまり,与えられた訓練例を,目標出力が +1 か -1 によって,2 つのグループに分類することが目的となります.例えば,p = 2 の場合であれば,(3) 式は,
S = w3,0 + w3,1u1 + w3,2u2
- となります.u1,及び,u2 を x,および,y とおくと,パーセプトロンの目標は,訓練例を正しく分類するような直線,
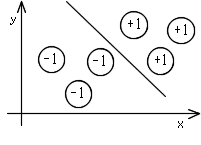
0 = w3,0 + w3,1 x + w3,2 y
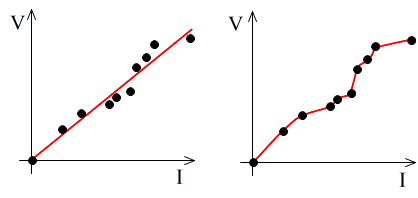
- の係数 w3,0, w3,1,及び,w3,2 を求めることになります.図示すれば,右図のような直線を求めることになります.そこで,(3) 式のような関数を線形識別関数と呼びます.
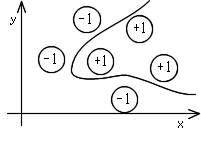
- 以上の説明からも明らかなように,線形識別関数では分類できない場合が存在します.例えば,右図に示すような場合は,2 つのグループに分類する直線を引くことができません.分類しようとすれば,図に示すような曲線になってしまいます.
- 従って,パーセプトロンでは,
u1 u2 c -1 -1 -1 -1 +1 +1 +1 -1 +1 +1 +1 +1
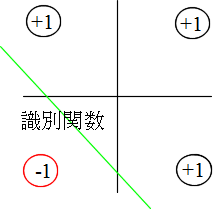
- のような論理和をネットワークによって実現することは可能(分類する直線が引ける)ですが,
u1 u2 c -1 -1 -1 -1 +1 +1 +1 -1 +1 +1 +1 -1
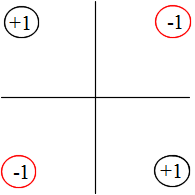
- のような排他的論理和を実現することは不可能(分類する直線を引けない)となります.
- 学習方法
- パーセプトロンの学習アルゴリズムは,以下のようになります.
- count = 0, w = 0 とする( count は学習回数)
- ランダムに,訓練例 ek を選ぶ
- count++.学習回数の上限を超えたら終了し,そうでなければ,以下に進む
- もし,正しく分類されたら,つまり,
wTek > 0 , かつ, ck = +1 ,または, wTek < 0 , かつ, ck = -1
- であるなら,
- もし,現在の重み w を使用し,続けて正しく分類した回数が,保存してある重み wold による回数より多く,かつ,w が,保存してある重み wold より多くの例を分類したならば,
- 保存してある重み wold を w で置き換え,続けて正しく分類した回数を記憶する
- すべての学習例を正しく分類できたら終了
- そうでなければ
- 以下の式で重みを修正し,かつ,続けて正しく分類した回数を 0 にする
w = w + ckek
- B に戻る
e1 = [1 -1 -1 -1] c1 = +1 e2 = [1 1 -1 -1] c2 = -1 e3 = [1 1 1 1] c3 = +1
このとき,例えば,以下のようにして学習が行われます.
繰返し 重み 例 結果 行動 1. [0 0 0 0] e1 no w = w + e1 2. [1 -1 -1 -1] e2 no w = w - e2 3. [0 -2 0 0] e1 yes 変更されない 4. [0 -2 0 0] e3 no w = w + e3 5. [1 -1 1 1] e1 no w = w + e1 6. [2 -2 0 0] e3 no w = w + e3 7. [3 -1 1 1] e1 yes 変更されない 8. [3 -1 1 1] e2 no w = w - e2 9. [2 -2 2 2] e1 no w = w + e1 10. [3 -3 1 1]
例 入力ユニットの数が 3 であるパーセプトロンに対して,以下の学習例を使用して学習を行います.
) JavaScript 版では,画面上で実行可能です.テキストエリアに表示されたデータの意味については,C++,または,Javaのプログラムに対する説明を参照してください.なお,他の言語( PHP,Ruby,Python,C#,VB )によるプログラム例に関しては,「プログラミング言語の落とし穴」第 9 章の「Winner-Take-All」をご覧ください.
wcor = wcor + ek wmis = wmis - ek
) JavaScript 版では,画面上で実行可能です.テキストエリアに表示されたデータの意味については,C++,または,Javaのプログラムに対する説明を参照してください.なお,他の言語( PHP,Ruby,Python,C#,VB )によるプログラム例に関しては,「プログラミング言語の落とし穴」第 9 章の「競合学習」をご覧ください.
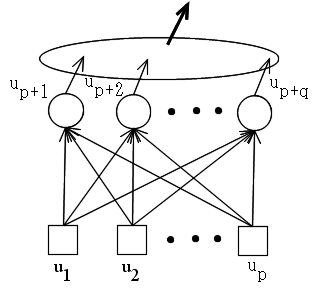
入力: {0, 1}
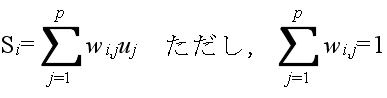 ui = 1 if Si > Sk for all k ≠ i (ユニット i が勝ったとき)
= 0 その他
i = p+1, p+2, ・・・, p+q
ui = 1 if Si > Sk for all k ≠ i (ユニット i が勝ったとき)
= 0 その他
i = p+1, p+2, ・・・, p+q 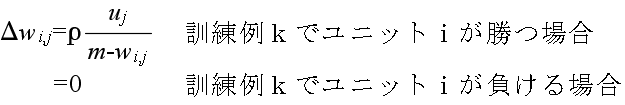
- 離散型モデル
- Hopfield ネットワーク(ホップフィールドネットワーク)は,基本構造の最初の図に示したように,すべてのユニットが相互に結合されたネットワークです.各ユニット j の出力は,他のユニットの出力の重み付き総和( Wj0 はバイアス,u0 = 1 ),
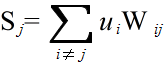
- を計算し,以下に示すような基準によって決定されます.
Sj ≧ 0 なら uj = 1 Sj < 0 なら uj = 0
- 重み Wij は,今まで述べたように学習によって決めるのではなく,問題によって,前もって設定しておきます.その後,適当なパターンを設定(各ユニットに,0 または 1 を設定)し,
- 1) ユニットをランダムに選択する
- 2) 選択されたユニットの出力を再計算する
- という処理を,どのユニットが選択されてもネットワークの状態が変化しなくなるまで繰り返すと,ネットワークのエネルギー,
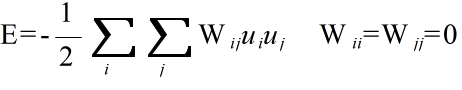
- が最小の状態に収束します.
- C/C++ によるプログラム例 →
,JavaScript 版では,画面上で実行可能です.なお,他の言語( PHP,Ruby,Python,C#,VB )によるプログラム例に関しては,「プログラミング言語の落とし穴」第 9 章の「Hopfield ネットワーク」をご覧ください.- 具体的に,連想記憶を例として説明します.ユニットの数を 36 個とし,ネットワークに以下に示すパターン(縦,横,斜め)を記憶します.
0 0 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 1 1 1 0 0 0 0 0 1 1 0 0 1 1 1 1 1 1 0 1 1 1 0 0 0 0 1 1 0 0 1 1 1 1 1 1 0 0 1 1 1 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1
- これら 3 つのパターンを記憶するため,重みは以下の式に従って決定します.ただし,api は,p 番目のパターンにおけるユニット i の出力とします.このように,複数のパターンを重ねて記憶することになります(記憶できるパターンの数には限度がある).
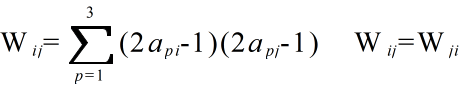
- このネットワークに対して,下の左側に示すパターンを初期状態として与え,上で述べた 1),2) の処理を繰り返すと,下の右側のように,縦棒のパターンに収束します.なお,このプログラムでは,ランダムにユニットを選択し,状態が変化しない回数が 100 回続いたとき,収束したものとして実行を停止しています.
0 0 1 1 0 0 0 0 1 1 0 0 1 0 0 0 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 0 0 0 1 1 0 1 0 0 1 1 0 0 0 0 1 0 0 0 0 0 1 1 0 0
- ただし,常に目的とするパターンに収束するわけではありません.下に示す左側の例の場合は,その右にある状態に収束してしまいます.この例のように,初期状態,乱数の初期値等によって,収束する状態が異なる場合があります.一般的に,目標とする状態との差が大きいほど,目標状態に収束する可能性が小さくなります.
1 0 1 1 0 0 1 1 1 1 1 1 0 0 1 0 0 0 1 1 1 1 1 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 1 1 1 0 1 1 1 1 1 1 1 0 0 1 1 0 0 1 1 1 1 1 1
- 似たようなモデルにボルツマンマシン( Boltzmann machine )が存在しますが,ボルツマンマシンの場合は,確率 { 1 / (1 + exp(-Sj / T)) } で uj = 1 となります.T を大きな値から小さな値まで徐々に変化させ,局所的最適解に陥ることを防いでいます.ボルツマンマシンは,T → 0 の極限で Hopfield ネットワークに一致します.
- 連続型モデル
- 連続型モデルにおいては,ユニット i の状態が ui である時,その出力 oi は以下に示すようなシグモイド関数によって決められます(どちらの関数を使用しても,結果は大きく変わらないと思います).
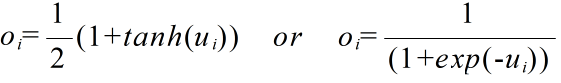
- ネットワークのエネルギーを E としたとき,内部状態 ui の時間変化は,微分方程式,
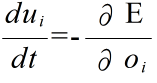
- で表されます.従って,この微分方程式を解き,その定常状態が求まれば,目的が達成できたことになります.
- ( C/C++ によるプログラム例 →
,JavaScript 版では,画面上で実行可能です.なお,他の言語( PHP,Ruby,Python,C#,VB )によるプログラム例に関しては,連想記憶の場合と同様,「プログラミング言語の落とし穴」第 9 章の「Hopfield ネットワーク」をご覧ください.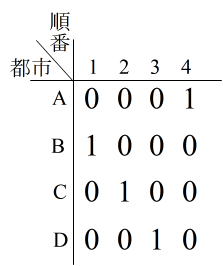
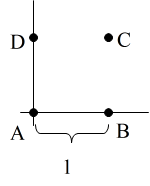
- 具体的に,巡回セールスマン問題( TSP: Traveling Salesman Problem )を例に取り,詳しく説明していきます.Hopfield ネットワークにおいては,n 都市の TSP は,n × n 個のユニットで表現されます.例えば,4 都市の場合は右図のようになり,各要素がユニットの出力を表しています.x 行 i 列の要素 oxi が 1 であることは,x 行目の都市を i 番目に訪問すると言うことを意味しますので,この図は,都市 B を最初に訪れ,2 番目に都市 C,3 番目に都市 D,最後に,都市 A を訪れることを意味しています.
- Hopfield ネットワークとしての TSP のエネルギー E は,以下のように表現されます.
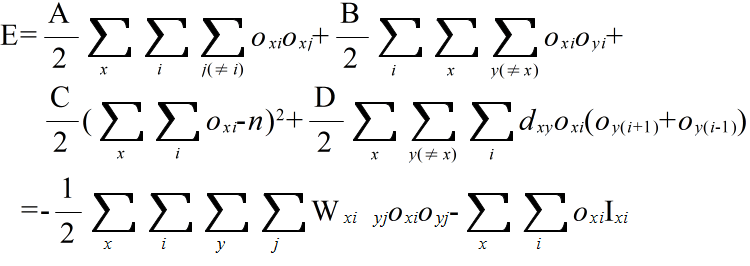
- ここで,重み Wxi yj 及び バイアス Ixi は以下のようになります.
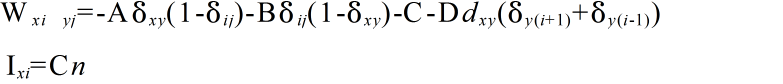
- 以上の式において,dxy は都市間の距離,δij はクロネッカのデルタ関数であり,
δij = 1 i = j のとき δij = 0 i ≠ j のとき
- を意味します.また,添え字の j + 1 が n より大きくなったときは 1 (プログラム上では,n - 1 より大きくなったときは 0 ),j - 1 が 0 になったときは n (プログラム上では,負になったときは n - 1 )に設定されます.
- エネルギーの第 1 項は,各行に 1 が一つだけあるときに小さくなります(すべての都市を 1 回だけ訪問する).第 2 項は,各列に 1 が一つだけあるときに小さくなります(同時に二つ以上の都市を訪問しない).また,第 3 項は,ネットワーク全体に n 個の 1 しかないときに小さくなります.最後の項は,最小化すべき経路長(都市間の距離の和)を意味しています.A,B,C,D は,これらの各項に着けられた重みです(都市名ではありません).
- 以上述べたエネルギーに対する微分方程式は,エネルギー E を oxi で偏微分すると得られ,以下のようになります.
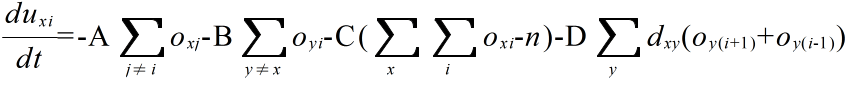
- 具体的に,右図に示すような 4 都市問題を解くと,以下に示すような結果が得られます.この結果では,A → D → C → B が最適経路となります.ただし,常にこのような正しい結果が得られるわけではありません.重み A,B,C,D の値,乱数の初期値等によって,結果はかなり異なります.
初期状態(出力): 最終状態(出力): 0.523 0.506 0.515 0.491 1.000 0.000 0.000 0.000 0.505 0.503 0.483 0.518 0.000 0.000 0.000 1.000 0.519 0.512 0.517 0.516 0.000 0.000 1.000 0.000 0.510 0.523 0.515 0.524 0.000 1.000 0.000 0.000
,なお,他の言語( JavaScript,PHP,Ruby,Python,C#,VB )によるプログラム例に関しては,「プログラミング言語の落とし穴」第 9 章の「バックプロパゲーション」をご覧ください.
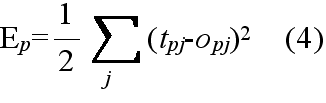
tpj: パターン p に対する出力ユニット j の目標出力 opj: パターン p に対する実際の出力ユニット j の出力
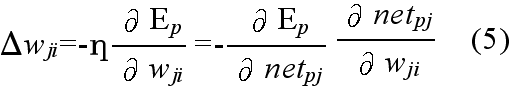
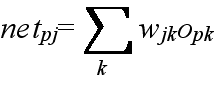
- opk: パターン p が与えられたときのユニット k の出力であり,ユニット k が入力ユニットの場合は,与えられた入力値,そうでない場合は,opk = fk(netpk) として計算される.ただし,k = 0 のときは,常に 1 とする.
- wji: ユニット i から j へ向かう枝に付加された重み.ただし,i = 0 のときは,ユニット j のバイアスとする.
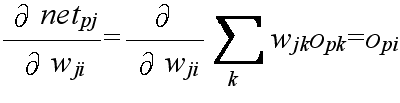
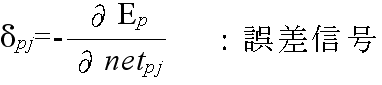
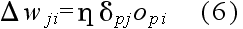
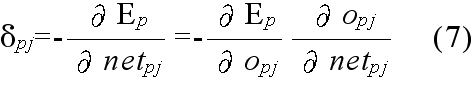
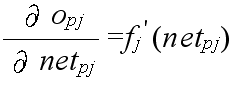
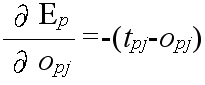
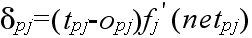
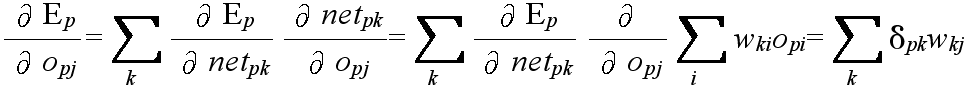
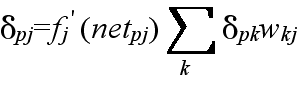
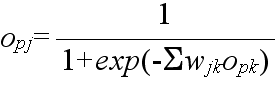
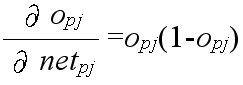
- パターン(訓練例) p を選択する
- 各ユニット j の出力 opj を計算する.ここで,opj は次の式によって計算される(入力層に対しては,opj = 入力値).
- ただし,wji は,ユニット i から j へ向かう枝に付加された重みであり,i = 0 のときは,ユニット j のバイアスとする.
- 隠れユニット i (または,入力ユニット)から出力ユニット j に向かう枝に付加された重み wji を次式によって修正する.
Δwji(n+1) = η δpj opi + α Δwji(n)
- ただし,
- η: 学習係数(学習速度の調整)
- α: 慣性係数(前回の重みの変化の影響を表す)
- とし,また,δpj は出力ユニット j の誤差信号であり,
δpj = (tpj - opj) opj (1 - opj)
- とする.
- 隠れユニット i (または,入力ユニット)から隠れユニット j に向かう枝に付加された重み wji 前式によって修正する.ただし,
- δpj = opj (1 - opj) Σ δpk wkj
- とする.ここで,
- δpk: ユニット j が出力を送っているユニット k の誤差信号
- wkj: ユニット j から k に向かう枝に付加された重み
- である.
- δpj = opj (1 - opj) Σ δpk wkj
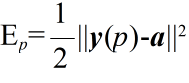
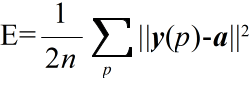
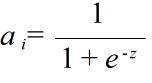
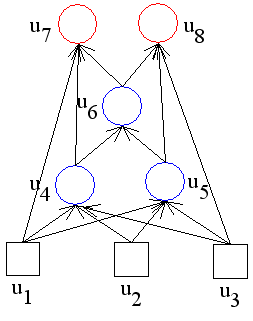
- 畳み込みニューラルネットワーク( CNN: Convolutional Neural Network )
- 画像認識に多く利用されています.通常のバックプロパゲーションモデルでは,ある層のユニットからその上のユニットに全結合されていますが,CNN ではそのようになっていません.CNN は,畳み込み層( Convolutional Layer,特徴マップ,Feature Map )とプーリング層( Pooling Layer )の組が何層も繰り返される隠れ層から構成されます.
- 簡単な例を考えてみます(以下に示す数値は,あくまで,例です).今,入力層が 30×30 個のユニットから構成されているとします.このとき,その上の畳み込み層のユニットは,入力層の 5×5 個のユニットから入力を得ることになります.5×5 個のユニットの位置は,畳み込み層のユニット毎に少しずつ移動していきます.1 ユニットずつ移動する場合は,畳み込み層の (1, 1) ユニットは入力層の (1, 1) ~ (5, 5) から,(1, 2) ユニットは入力層の (1, 2) ~ (5, 6) から,・・・,(26, 26) ユニットは入力層の (26, 26) ~ (30, 30)から入力を得ることになります.なお,入力層のユニットと畳み込み層のユニットを結ぶ重みとバイアス( 25 + 1 個)は,すべて共通とします.
- プーリング層は,畳み込み層から入力を得ますが,畳み込み層と同様,畳み込み層の少しずつ移動した 2×2 個のユニットから入力を得ます.ただし,プーリング層の各ユニットの出力は,重みやバイアスを使用せず,そこに繋がれた 2×2 個のユニットの出力の最大値などによって決定します.
- 再帰型ニューラルネットワーク( RNN: Recurrent Neural Network )
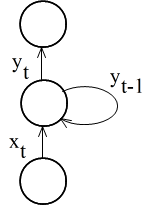
- 音声認識など,時間的な順序が重要となる場合に利用されています.RNN の基本的な考え方は右図のようになります.右図においては,1 ステップ前の隠れ層の出力 yt-1 を保持しておき,その値と現在の入力 xt-1 によって,隠れ層の出力を決定しています.これは,非常に単純な場合ですが,実際においては,様々な工夫がなされています.
| 情報学部 | 菅沼ホーム | SE目次 | 索引 |