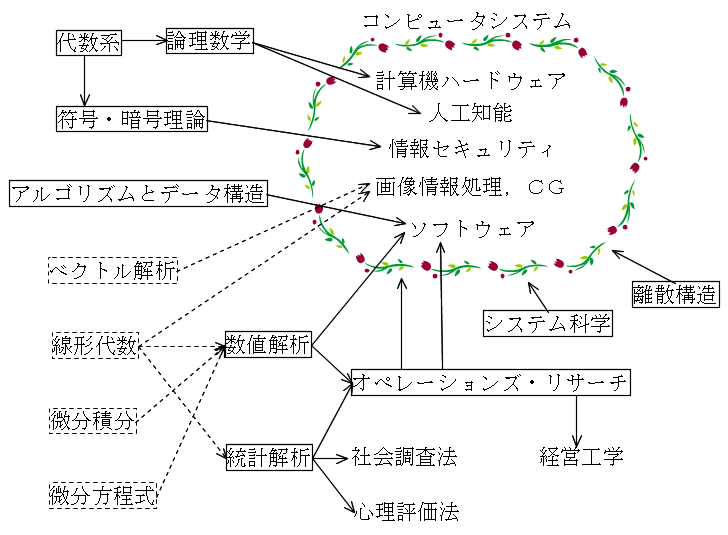
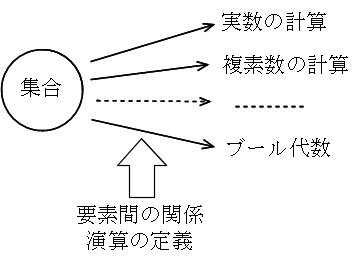
我々が通常行っている加減乗除の基礎となるのが「代数系」です.通常行っている演算体系は,代数系の立場から簡単に述べれば,実数の集合の上に加減乗除の演算を定義した体系であるといえます.一般に,どのような集合を選ぶか,又,そこにどのような演算を定義するかによってその系(代数系)の性質は異なってきます.特に,0 と 1 という 2 つの要素だけからなる集合の上に,加算( OR 演算)と乗算( AND 演算)などを定義した系はブール代数(ブール束)と呼ばれ,コンピュータ内で行われる 2 進数による演算の世界に対応します.従って,「計算機ハードウェア」や「計算機アーキテクチャ」などの科目と強い関係があります.
また,ブール代数は,論理の世界と同じ構造を持っています.0 を「偽」,1 を「真」とみなせば,同じような構造であることが分かると思います.この論理の世界を扱うのが「論理数学」です.論理体系の一つである命題論理は「ソフトウェア」を作成する際にも重要であると共に,その発展形である述語論理と共に,「人工知能」における知識表現方法の一つとしても使用されています.勿論,数学的な論理体系だけでは,人間の知的行動の一部しか表現できませんが,例えば,命題論理を使用することによって,「 A ならば B である」,「 B ならば C である」という 2 つの事実から,「 A ならば C である」という事実を推論(三段論法)できる能力は,知的なコンピュータにとって必要不可欠なものです.