int x[4] = {100, 200, 300, 400};
int *y; // int y[4]; では,y = x; は実行できない
char *c; 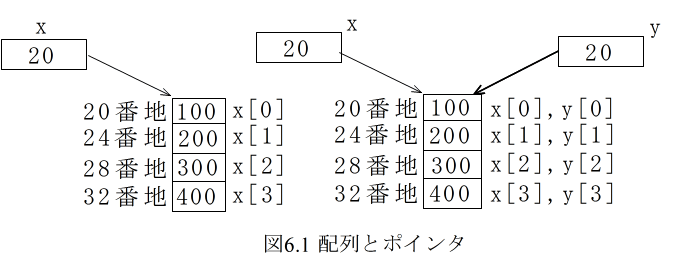
y = x; または y = &(x[0]);
int *x = new int [4]; for (int i1 = 0; i1 < 4; i1++) x[i1] = 100 * (i1 + 1); int *y; char *c;

y++; *y = ・・・;
*(y+1) = ・・・; a = *(y+2); ・・・
c = (char *)x; c++;
nt a[3][2];
int x[3][2] = {{100, 200}, {300, 400}, {500, 600}};
int **y, *z, *w[3]; 
y = &(w[0]); w[0] = x[0]; w[1] = x[1]; w[2] = x[2];
z = (int *)x; // z = &x[0][0]; でも良い
